.webp)
Data governance defines the policies, roles, and processes for managing and securing data across an organization, while data quality measures how accurate, complete, and reliable the data is. Effective data quality depends on strong governance to ensure consistent standards, compliance, and trustworthy decision-making.
There is a subtle difference between data governance and data quality. While data quality focuses on the state of the data itself, data governance considers how we manage and process that data.
Although they’re different disciplines, it’s difficult to ensure data quality without proper data governance. They’re so entwined that data stewards spend around 75% of their time defining standards, viewing data quality, and correcting data quality, according to Dataversity.
Because of this, it’s vital to understand the difference between the two, and how they can work together to benefit your company and reduce risk.
In this article, we’ll cover:
- The differences between data governance and data quality
- Data quality is impossible to implement without data governance
- How data governance tools can help improve data quality
Are you struggling to fully understand how data flows from one place to another within your cloud-based or on-prem infrastructure? Download our white paper How to Build Data Lineage to Improve Quality and Enhance Trust
What is Data Governance?
Data governance is the framework of policies, roles, processes, and standards used to manage data across its lifecycle. It ensures data is secure, accessible, compliant, and properly managed across systems and departments.
Key focus areas include:
a. Data ownership and accountability
b. Data security and access control
c. Compliance and regulatory alignment
d. Metadata and data lifecycle management
e. Standardization of data practices
What is Data Quality?
Data quality refers to the condition of data and how well it meets business requirements. High-quality data is accurate, complete, consistent, timely, and reliable for operational and analytical use.
Common data quality dimensions include:
a. Accuracy
b. Completeness
c. Consistency
d. Timeliness
e. Integrity
f. Validity
Data Governance vs Data Quality: Key Differences
Now let’s answer the main question: how do data governance and data quality differ?
Quick Differences Explained
a. Data governance defines rules, while data quality measures outcomes
Data governance establishes the policies, standards, and procedures that guide how data should be created, stored, accessed, and used. Data quality, on the other hand, evaluates whether the data actually meets those standards in practice.
b. Governance focuses on management and control, quality focuses on data condition
Data governance ensures proper oversight through ownership, security policies, and compliance controls. Data quality examines the actual state of the data — determining whether it is accurate, complete, consistent, and reliable for business use.
c. Governance establishes ownership; quality ensures usability
Through governance, organizations assign data owners and stewards responsible for maintaining data assets. Data quality ensures that the managed data remains usable, meaningful, and trusted for analytics, reporting, and operational decisions.
d. Governance is strategic and organizational; quality is operational and measurable
Data governance operates at a strategic level by aligning data practices with business objectives and regulatory requirements. Data quality works at an operational level, using measurable metrics such as error rates, completeness scores, and validation checks.
e. Data quality cannot be sustained without effective governance
Without governance frameworks, data standards vary across teams, leading to inconsistencies and errors. Governance provides the structure, accountability, and processes required to continuously maintain and improve data quality over time.
Bird’s-Eye View: Data Governance vs Data Quality
|
Aspect |
Data Governance |
Data Quality |
|
Definition |
The framework of policies, roles, standards, and metrics that ensure data is properly managed and used across the organization. |
The measure of data’s accuracy, consistency, completeness, and reliability for business use. |
|
Focus Area |
How data is managed, stored, accessed, and secured. |
The condition or state of the data itself. |
|
Objective |
To ensure that data management aligns with business goals, compliance, and security standards. |
To ensure data is accurate, consistent, and useful for decision-making. |
|
Responsibility |
Managed primarily by data governance teams, data stewards, and compliance officers. |
A shared responsibility across all employees and departments. |
|
Scope |
Broad — includes data policies, processes, roles, and data lifecycle management. |
Narrower — focuses specifically on data validity, accuracy, and reliability. |
|
Outcome |
Builds trust, compliance, and accountability around data handling. |
Enables high-quality analytics, reporting, and decision-making. |
|
Dependency |
Independent process that provides structure for data management. |
Dependent on governance — cannot exist effectively without it. |
|
Tools Used |
Enterprise data governance tools, data catalogs, metadata management platforms. |
Data profiling, data cleansing, and data monitoring software. |
Related Post: What is Data Quality? Dimensions & Their Measurement
Why Data Quality Depends on Data Governance
Data quality initiatives succeed only when governance establishes clear standards and accountability. Without strong governance practices, organizations often face the following challenges:
1. Data definitions vary across teams
Without governance, departments may define the same data differently. For example, “customer” or “revenue” may have multiple meanings across teams, leading to confusion, inconsistent reporting, and difficulty aligning business decisions based on shared data.
2. Integrations introduce inconsistencies
When systems integrate without standardized governance rules, data formats, naming conventions, and validation processes differ. This creates duplication, mismatched records, and transformation errors, ultimately reducing confidence in integrated data environments.
3. Reporting becomes unreliable
Poor governance leads to inconsistent data sources and unclear ownership. As a result, dashboards and reports may display conflicting numbers, making it difficult for leadership to trust analytics or make informed strategic decisions.
4. Compliance risks increase
Without governance policies controlling access, retention, and usage, organizations risk violating data privacy and regulatory requirements. Poorly managed data can expose sensitive information, leading to legal penalties, financial loss, and reputational damage.
5. Data governance creates the foundation, while data quality represents the result
Data governance establishes the rules, responsibilities, and standards for managing data. Data quality reflects how well those rules are followed, ensuring data remains accurate, consistent, and trustworthy across the organization.
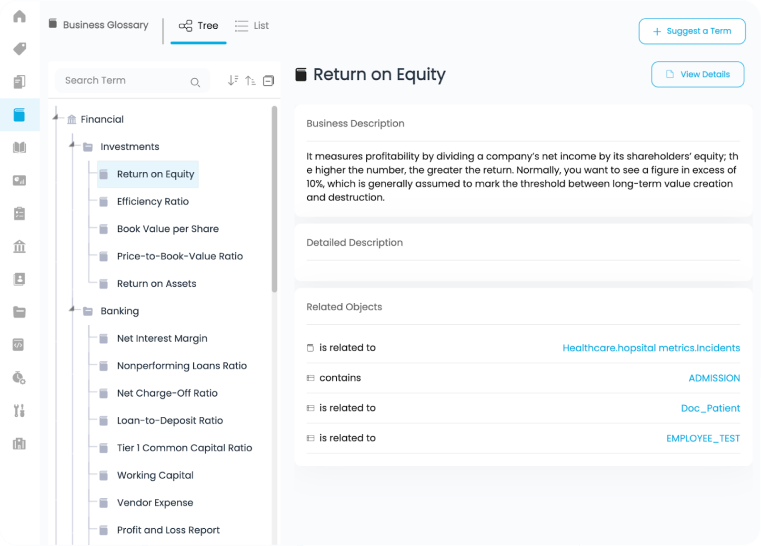
How Data Governance Improves Data Quality?
Organizations improve data quality through strong governance practices that standardize processes, clarify accountability, and promote consistent data usage.
1. Defining standardized data formats
Data governance establishes consistent formats for fields such as dates, addresses, and customer IDs. Standardization prevents duplication, reduces errors during data exchange, and ensures systems interpret data uniformly across departments and applications.
2. Establishing data ownership roles
Governance assigns clear ownership through data owners and stewards responsible for maintaining data accuracy and integrity. Defined accountability ensures issues are addressed quickly and prevents confusion over who manages or validates specific datasets.
3. Implementing data catalogs and lineage tracking
Data catalogs provide centralized visibility into available datasets, while data lineage tracks how data moves and transforms across systems. This transparency helps teams understand data origins, detect errors faster, and maintain reliable data throughout its lifecycle.
4. Monitoring data through quality rules
Governance frameworks introduce automated data quality rules that continuously validate data against predefined standards. Alerts and monitoring help organizations proactively identify anomalies, preventing recurring issues and maintaining consistent data reliability.
5. Promoting organization-wide data literacy
Data governance encourages employees to understand how data should be created, interpreted, and used responsibly. Improved data literacy enables teams to recognize errors, follow standards, and contribute collectively to maintaining high-quality data across the organization.
Related: Data Catalog: The Ultimate Guide
Implementing data quality with OvalEdge
We’ve already touched on the pillars of data quality, but let’s drill down more to see how you can address each one with OvalEdge.
1. Define
Before you do anything else, you need to define your data quality standards and capture them in OvalEdge. This will be the benchmark for your data quality, and tells everyone in the company what they should aim for.
This includes defining how data should be collected and stored, such as date and time format, or whether to include dashes in phone numbers.
Note: It’s important to define your standards in accordance with your company’s data governance strategy, to ensure consistency
2. Collect
Once you’ve defined your standards, you need to locate and collect all existing data quality issues within the company. This is easier said than done, but it’s much easier if you create a data literacy program.
This gives you the means to educate your colleagues on data quality, allowing them to report issues within OvalEdge as they find them. These reports should include business value, where the problem exists, what the issue is, and the priority.
To collect issues, OvalEdge presents the data catalog when decision makers are looking at the data, so they can report the problem right there. This facilitates the issue creation process.
3. Prioritize
When you’ve compiled a list of the issues in OvalEdge, you can focus on triaging these issues in order of priority.
This is where you get a lot of value from your quality standards, as you’ll be able to use these to validate and prioritize each issue.
It’s also important to consider business value, time to fix, and change management when deciding what should be prioritized. You can see all the key information, and carry out advanced filtering to make this process much quicker.
You need to collect various metadata, like business impact and data decision importance. OvalEdge helps you collect these data points, and prioritize the problems. If data is going to the regulators, you need to ensure there are no data quality issues.
4. Analyze
The next step is to dig deeper into the issues, and carry out further root cause analysis. Using the data catalog in OvalEdge, your analysts can create relationships and find where the issues stemmed from.
It’s also important to understand why the data caused an issue, and to investigate ways to prevent this from happening again in the future.
One major area of analysis is finding the root cause of the problem. OvalEdge lineage helps you easily understand where the data comes from. Analysts can then easily understand the data, and find the root cause of the problem.
5. Improve
Using the findings of your investigation and analysis, you then need to agree and implement improvements that will increase your data quality over time.
This can vary from manual fixes, technical solutions, master data, or even implementing new processes. The solution will vary depending on the issue, but it’s vital to define measurable objectives so you know you’re going in the right direction.
6. Control
The final step in this process is to write a set of rules that monitor data quality and send alerts when issues are detected. This can’t catch brand new issues, but it will ensure you catch known issues if they happen again.
Control is about proactively checking for errors, and data quality rules in OvalEdge help in this process. Companies can use data quality rules for the whole control process, alongside previously defined rules.
This allows you to be proactive and not have to rely on manual discovery.
Conclusion
Data governance and data quality work together but serve different purposes. Governance defines how data should be managed, secured, and standardized, while data quality evaluates whether the data meets business expectations. Strong governance enables consistent, reliable, and high-quality data across the organization.
Read our Best Practices for Improving Data Quality post for a more detailed breakdown of this process.
Frequently Asked Questions (FAQ)
1. Is data governance the same as data quality?
No. Data governance defines policies and processes for managing data, whereas data quality measures how accurate and reliable the data is.
2. Which comes first: data governance or data quality?
Data governance comes first because it establishes the standards and controls required to maintain data quality.
3. Who is responsible for data quality?
Data quality is a shared responsibility across all departments, although data stewards and governance teams typically oversee implementation.
4. Can organizations improve data quality without governance?
Sustainable data quality is difficult without governance because there are no standardized rules or ownership structures to maintain consistency.
5. Why are both important for businesses?
Together, they ensure trustworthy analytics, regulatory compliance, improved decision-making, and reduced operational risk.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)