

📌 QUICK ANSWER
Data governance is organizing, securing, managing, and presenting data using methods and technologies that ensure it remains correct, consistent, and accessible to verified users. In other words, it's the framework that ensures your organization's data is trustworthy, secure, and ready to drive business decisions.
Digital transformations are sweeping the business world at every level. From global enterprises trading legacy systems for multi-cloud architecture to local car dealerships swapping cable commercials for CRM systems, technology is advancing the fortunes and reach of companies across the board.
Today, the most influential technologies in the enterprise toolkit include AI, automation, cloud applications, infrastructure, cybersecurity defenses, and analytics. Together, these critical mechanisms empower companies to thrive in the most competitive business landscape in history and meet the expectations of an increasingly discerning customer base.
While these technologies may appear different on the surface, serving unique purposes, there's one thing that unites them all: data.
You already know data is the new oil, but did you know just how integral it is to your entire technology ecosystem? Every digital touchpoint generates data, and it's this data that fuels the applications and approaches that drive digital transformation.
However, for data to work for an organization, it has to be clean, available, and managed. With the increase in data sprawl, it needs to be secure. In other words, it needs to be governed.
Think of data governance as Michael Caine. He only ever won an Academy Award for Best Supporting Actor, but he's always the star of the show.
In this guide, we'll explain what data governance is, why you need it, and how to implement it at a pace that matches your digital transformation strategy.
What is Data Governance?
Data governance is organizing, securing, managing, and presenting data using methods and technologies that ensure it remains correct, consistent, and accessible to verified users.
Let's break that down into four key components:
Organizing — Identifying all your data sources and getting all your data in one place.
Securing — Making sure all your data complies with data privacy regulations and internal company policies.
Managing and presenting data — After you've organized your data, you need to decide how you present this data to your team.
Using methods and technologies — Like modern data governance platforms.
Ensuring correctness and accessibility — The people in your organization have the permission to access it and trust its accuracy.
In practice, data governance boils down to two key actions: drafting and implementing policies. Organizations must write policies that involve all the key stakeholders, address specific pain points, and are implementable within the confines of the available technologies.
Example: The marketing department of a clothing company needs to secure the PII data it uses to contact customers. However, they need a mechanism in place that enables managed access. Currently, they have two options: leave it open to all users or confine it to individual team members.
They must write a policy governing access requests and implementing data masking.
Data Governance vs Data Management
Data governance is often confused with data management, but they serve different purposes.
Data governance focuses on the policies, standards, and accountability for data quality, security, and compliance. It answers questions like: Who owns this data? Who can access it? What quality standards must it meet?
Data management is the broader operational practice of collecting, storing, processing, and using data throughout its lifecycle. It includes the technical execution of data storage, integration, and analytics.
Think of it this way: data governance sets the rules, while data management executes them.
|
Aspect |
Data Governance |
Data Management |
|
Focus |
Policies, standards, accountability |
Technical operations, execution |
|
Questions |
Who, what, when, why |
How, where |
|
Output |
Rules, frameworks, compliance |
Data infrastructure, pipelines |
|
Scope |
Strategic |
Operational |
Both work together. A governance team might set policies for data access, while a management team creates the technical mechanism to enforce those policies through role-based access controls.
Why do we need data governance?
While data powers your company's most critical applications and practices, this is just one strand of a web of drivers that make data governance a vital business process.
You can break these down into two approaches: defensive and offensive.
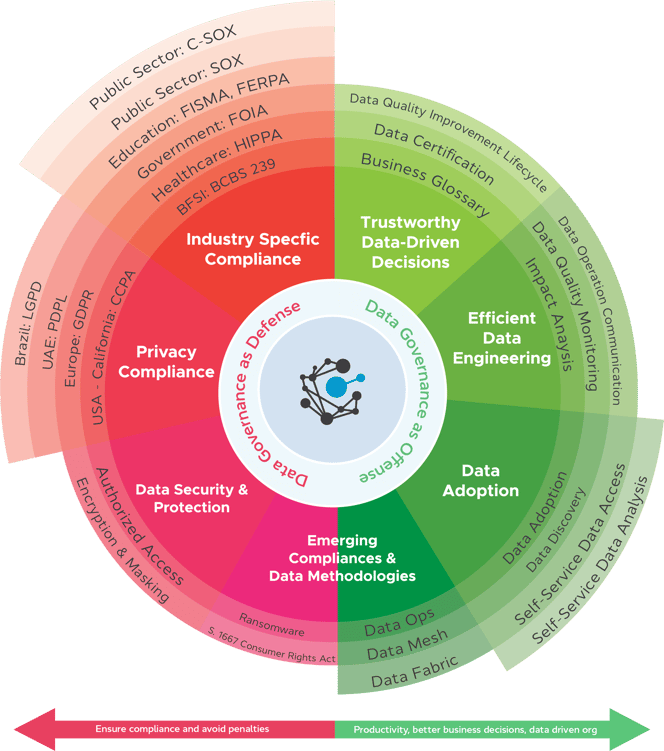
Defensive Data Governance
Defensive Data Governance is about protecting data and falls under the following categories:
Industry-Specific Compliance
Data governance helps companies comply with various industry-specific regulations such as the Health Insurance Portability and Accountability Act (HIPAA), the Basel Committee on Banking Supervision's standard number 239 (BCBS 239), and the Family Educational Rights and Privacy Act (FERPA).
Example: A small Colorado bank must report its financial statements to a regulator. In the aftermath of the 2008 financial crash, regulators require far more stringent proof that the information provided is accurate. So, along with the figures, the bank needs to provide evidence of the data's lineage, consistent definitions, and more.
Read more: Data Governance in Banking
Privacy Compliance
Companies that deal with consumer data must adhere to the various data privacy regulations that protect that information. The most famous is the European Union's General Data Protection Regulation (GDPR), which sent shockwaves through thousands of organizations when it launched in 2017.
Yet, the GDPR is just one of many international privacy regulations. Others include the California Consumer Privacy Act (CCPA) and the UAE's Personal Data Protection Law, but regulators worldwide are constantly developing new regulations, and the list is growing.
Example: In 2022, Meta was fined €405 million by the Irish Data Protection Commission for violating the GDPR. Meta-owned Instagram failed to protect the privacy of minors using the app by publishing email addresses and phone numbers.
Related: 3 Data Privacy Compliance Challenges that can be solved with OvalEdge
Data security and protection
Organizations that collect PII or other confidential data are required to adhere to various industry regulations and must have policies that define how data is collected, who can access it, how they can access it, and more.
Data must be stored safely and masked so users without authorized access can't see what it contains.
Example: A US furniture retailer spends approximately 12% of its operating budget on cybersecurity. However, the company still faces fines for violating the terms of the CCPA because customer data was leaked in a credential-stuffing attack. Data was stored on-premises, and the files weren't encrypted, so attackers could access them using stolen credentials.
Emerging Compliance and Data Methodologies
While many compliance regulations exist, the transformative nature of data-driven industries dictates that new compliance regulations combat new threats, like advanced ransomware, and support new data methodologies.
Example: In 2021, the Social Media Privacy Protection and Consumer Rights Act was introduced in the US, requiring social media platform operators to provide users with information about data collection and usage before creating an account.
Offensive Data Governance
Offensive Data Governance is about extracting the maximum value from your company's data assets. It looks at the positive outcomes from a defensive stance and deploys them to increase a business's success.
You can split this offensive approach into the following areas:
Trustworthy Data-Driven Decisions
When data is of high quality, standardized, and certified, it can be used to make better business decisions. The same governance process that ensures data is secure and well-organized for compliance reasons makes it available for business teams, too.
Example: A coffee shop uses a data governance process to optimize its ordering system. With stringent data management facilities, the shop can easily match the amount of the most popular coffee and fresh ingredients it needs to order with customer demand. Previously, the company was experiencing a high level of waste due to overordering.
Efficient Data Engineering
A positive side effect of data governance is increased efficiency. Data engineers can monitor data quality to create better models. Data governance processes also enable more detailed impact analysis so engineers can track the successes and failures of data processes.
Example: An advertising company wants to increase its capacity for data visualization to provide a client-facing dashboard so customers can monitor campaigns independently. With an efficient data quality improvement procedure, the company's data engineers can quickly develop the model and ensure it's updated in real-time with high-quality data.
Data Adoption
Data governance makes data more accessible to more users. It enables organizations to put measures in place that support self-service, increase adoption of data analysis, create a culture of data-driven innovation, and alleviate pressure from the IT department.
Many technologies, particularly AI-powered applications, empower companies to streamline business processes. However, as we mentioned at the start of this guide, all these technologies require governed data and techniques that make it easy for regular business users to use them.
Example: A paper manufacturing company leverages AI to optimize its supply chain, bolster marketing efforts, and improve other internal processes. However, the team members creating the AI model are data scientists with little business knowledge.
On the other hand, business users need help accessing the data they need or even understanding the information required to build the models. They need to speak the same language, communicate, and collaborate.
Learn more: Measuring AI Readiness
Emerging Compliances and Data Methodologies
New data methodologies like data ops, data mesh, and data fabric are revolutionizing the data industry. However, you can't begin to use these techniques without getting the basics right.
All of the central data processes required to maximize these methodologies come when you start to govern your data smartly.
Example: A timber company that has been in operation for over a century expanded its operation into manufacturing timber products for custom eco homes. The shift from regular lengths to bespoke designs and a far wider client base resulted in an exponential increase in company data.
The company wants to start working with a data mesh strategy to support these innovations, but the company culture is stagnant. Data literacy is low, and the majority of users need the tools to find and process the data they need.
Defensive vs Offensive Data Governance: Quick Comparison
|
Defensive Governance |
Offensive Governance |
|
Compliance (GDPR, HIPAA, CCPA) |
Data-driven decision making |
|
Security and data protection |
Innovation and competitive advantage |
|
Risk mitigation and auditing |
Operational efficiency |
|
Privacy safeguards |
Self-service analytics |
|
Regulatory reporting |
AI and ML enablement |
Data Governance for AI and Machine Learning
As organizations increasingly adopt AI and machine learning, data governance becomes even more critical. AI models are only as good as the data they're trained on, and poor governance can lead to biased models, compliance violations, and security risks.
Why AI Needs Governed Data
Quality Requirements: AI models require high-quality, well-labeled data. Governed data ensures accuracy and completeness.
Bias Prevention: Without governance, AI models can inherit biases present in training data, leading to unfair outcomes.
Compliance: AI governance ensures that sensitive data isn't inadvertently exposed through model outputs or training processes.
Explainability: Data lineage tracking helps explain how AI models make decisions, which is increasingly required by regulations.
AI Governance Best Practices
- Implement data lineage tracking for all data used in AI models
- Create clear policies for AI data usage and model deployment
- Monitor model outputs for bias and data quality issues
- Ensure compliance with AI-specific regulations (like the EU AI Act)
- Document data sources and transformations used in model training
Organizations that implement strong data governance before deploying AI see better model performance, fewer compliance issues, and faster time to value.
Who is responsible for Data Governance?
Most organizations realize the importance of data governance. Organizations have people from business, data engineering, and compliance who all understand the benefits of a data governance strategy.
When consensus is reached, companies usually hire a consultant or assign a person or team to implement data governance. Sometimes this team is carved out from the business side, sometimes from the data engineering side, but rarely from the compliance department, although the requirements are there.
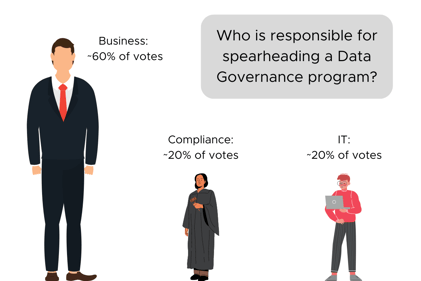
OvalEdge CEO Sharad Varshney recently surveyed data governance champions. He asked, "Who is responsible for spearheading your Data Governance Program?" You can see the results here.
Key Data Governance Roles
|
Role |
Responsibilities |
Level |
|
CDO (Chief Data Officer) |
Leads all data operations, responsible for data management, governance, and analytics processes |
Executive |
|
Data Governance Manager |
Responsible for enforcing data governance practices and ensuring stakeholders are aligned |
Management |
|
Data Steering Committee |
Includes representatives from every department. Meets to discuss pain points and recommend policies |
Cross-functional |
|
Data Owner |
Protects and manages specific data assets by overseeing and granting or denying data access requests |
Domain-specific |
|
Data Steward |
The primary role is maintaining data quality and security by drafting policies |
Operational |
|
Data Custodian |
Responsible for the technical requirements needed to support data initiatives |
Technical |
CDO (Chief Data Officer): A CDO leads all data operations in an organization. They are responsible for data management, governance, and analytics processes and oversee technology and process implementation.
Data Governance Manager: A Data Governance Manager is responsible for enforcing data governance practices in an organization and ensuring that the various stakeholders are aligned.
Data Steering Committee: A Data Steering Committee includes representatives from every department in an organization. The Committee meets to discuss pain points and requirements, and they recommend data governance policies for implementation.
Data Owner: A Data Owner protects and manages specific data assets primarily by overseeing and granting, or dismissing, data access and edit requests. They work closely with Data Stewards and Data Custodians.
Watch a funny skit about Data Owners here.
Data Steward: A Data Steward's primary role is to maintain data quality and security. To achieve this, they will draft policies that define the actions required to achieve these goals.
Watch a funny skit about Data Stewards here.
Data Custodian: While a Data Steward is responsible for the business implementation of data governance policies, a Data Custodian is responsible for the technical requirements needed to support data initiatives.
Watch a funny skit about Data Custodians here.
How to Implement Data Governance
Assess Your Data Governance Maturity
A data governance maturity assessment provides you with a way to understand the level of data maturity in your organization. Calculating data maturity is critical in understanding where you are on your data governance journey and where you need to be.
This knowledge enables you to track the progress of your roadmap, measure and evaluate, and determine which areas of data governance you thrive in and which areas need work.
Follow our step-by-step guide to assessing your level of data maturity and download our maturity model questionnaire to speed up the process.
.png?width=396&height=284&name=DG%20Maturity%20Model%20Graphic_V10%20(1).png)
Implement Data Governance by Use Case
One of the best ways to develop a solid data governance strategy is to implement procedures based on individual use cases. This way, you can roll out data governance incrementally, focusing on the most pressing pain points.
The top five data governance use cases include:
- Collaborative analytics or building new data products
- Data privacy compliance
- Data discovery and data literacy provisions
- Creating a centralized repository of all standardized business terms
- Centralized data access management
Find out how implementing data governance by use case can quickly give you quantifiable results that help you measure the impact of your governance strategy.
Lay Out Your Data Governance Roadmap
Like a project plan for data governance success, a roadmap provides tangible goals for an achievable data governance strategy. There are a wide variety of considerations you need to account for to ensure your roadmap is achievable, in line with the requirements of key stakeholders, focused on critical data governance outcomes, and communicable.
Learn how to develop and implement a successful data governance roadmap in your organization. Download our free roadmap template to provide structure to your strategy.
How to Practice Data Governance
As we learned, data governance is about drafting and implementing policies to organize, secure, and manage data. If you get it right, your organization can thrive with improved efficiency and better methods to sell your products or services.
The trouble is, if you draft policies that are difficult to implement, you risk their success and the success of your organization.
Let's understand the different kinds of policies we need to draft or adapt. These policies must comply with the laws governing where the business operates, cover internal business needs, and encourage data adoption.
Essential Data Governance Policies
Data quality policy: A data quality policy must specify standards for precision, completeness, consistency, and timeliness. It should explain how data is exchanged, validated, and processed, and how data quality metrics are reported.
Data classification policy: These guidelines enable users to categorize data based on various factors, including sensitivity, confidentiality, and business value. The policy determines the levels of security, access, and handling procedures for diverse data assets.
Data ownership policy: A data ownership policy assigns responsibility for data assets to corresponding Data Owners and Stewards. These guardians are liable for the accuracy, completeness, and appropriate use of data in line with verified guidelines.
Data lineage policy: A data lineage policy is the procedure for tracking data flow from source to destination. With data lineage in place, organizations can quickly understand data transformation and usage across an organization and benefit from a critical methodology for data quality maintenance and compliance.
Data privacy and protection policy: Data collection, usage, storage, and sharing are governed collectively by a data privacy and protection policy. It usually includes measures to comply with applicable data protection regulations, like the GDPR or CCPA.
Data retention and disposal policy: Companies deploy a data retention and disposal policy to specify the rules for data retention periods and data disposal procedures. It considers legal, operational, and risk management requirements.
Data access and security policy: A data access and security policy determines the processes and rules for data access management. Considerations include authentication, permission, encryption, and monitoring to protect data from unauthorized access and security breaches.
Data sharing and integration policy: A data sharing and integration policy covers both internal and external data assets. It manages data integration and oversees the consistent and accurate incorporation and transformation across dispersed sources.
Data backup and recovery policy: These guidelines outline procedures for developing and maintaining critical data backups and strategies for data recovery.
Data compliance policy: A data compliance policy enables an organization to undertake data management practices per applicable laws, regulations, and standards. The policy includes procedures for periodic audits, risk assessments, and ongoing data governance improvement.
As we know, these policies can be complex, so both academics and various startups are working on simplifying them. While academia is more focused on drafting policies than implementing them, tech startups tend to focus on a single strand, like access level control or lineage.
At OvalEdge, we take a holistic approach to data governance. Learn more about drafting policies in the OvalEdge Academy, and OvalEdge has next-generation data governance tools to help you implement them.
Analyze the various aspects of Data Privacy Compliance before revealing how OvalEdge can address them in your company. Download our whitepaper Implementing Data Governance
Data Governance framework
If you can organize your data correctly, all your policies can be drafted and implemented. For example, if privacy data is easy to find, you can prepare a policy that addresses this privacy data. Administrators might block access to the entire database, so the data is difficult to find.
A data governance framework is a way to structure data governance and begin organizing your data. You can understand the various data governance frameworks as you do the various methods of governing countries, such as democracy, autocracy, or communism. Frameworks for data governance teach you how you should approach drafting policies.
The first consideration is data organization, which is a significant task. You need to organize your data to enable as many people as possible to find it for their use cases.
For example, data analysts must find the correct data to build business analytics. Business users need to find data to make data-driven business decisions. And your compliance team must ensure the data going to regulators or stakeholders is accurate.
This is why there are various frameworks for data governance. Some of these are described below.
Common Data Governance Frameworks
|
Framework |
Best For |
Complexity |
Key Focus |
|
Progressive (OvalEdge) |
Modern, incremental adoption |
Medium |
Practical implementation at your pace |
|
DAMA-DMBOK |
Comprehensive, enterprise-wide |
High |
Traditional, all-encompassing approach |
|
Stanford Model |
Academic, structured |
High |
Maturity assessment and planning |
The DAMA framework: Traditional governance follows the DAMA framework. This framework's requirements enable cross-company involvement with each stakeholder working in specific areas. However, implementing data governance using this framework is complex, costly, and bulky.
The Stanford Data Governance Maturity Model: The Stanford data governance framework was developed by the university in 2011 and was adopted from other well-known maturity models. While the Stanford framework is extensive, it doesn't support incremental implementation steps or correspond with the technological shift since it was conceived.
The Stanford and DAMA frameworks are prescriptive and out of touch with the current business landscape. That is why we developed the progressive data governance framework for implementing policies.
Read more: Top Data Governance Frameworks: Best Detailed Guide
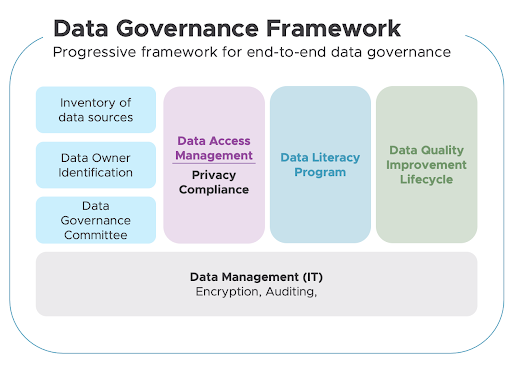
Progressive data governance framework
OvalEdge's progressive data governance framework is built for today's technological timelines. It is based on an acute understanding of current and evolving technologies, AI capabilities, technology limitations, and use cases.
Based on that, it supports the highest implementation parameters to achieve the maximum output. Progressive implementation enables users to develop data governance programs at their own pace based on the technologies available to them.
Let's explore each section of the progressive framework:
- Roles and Responsibilities
Companies need to create an organizational structure for implementing data governance. This organizational structure must include part-time roles such as data stewards and custodians, and full-time positions such as data governance managers and administrators to manage governance tools.
This stage is about defining ownership of data so you can build a system whereby everyone knows where to access data and who is responsible for it.
- Inventory of Data Sources
Before any other data governance activities, organizations must catalog and classify their data.
Cataloging involves collecting all of the data in one place so it can be better understood.
Classification consists of defining the data and dividing it into functional categories so companies can create various policies (confidential, location, privacy, etc.) based on it.
Learn more about organizing your data with what is a data dictionary and what is a business glossary.
- Build a Steering Committee
A data governance committee provides the leadership and resources required to run your data governance programs. Data governance committees must meet formally and regularly to decide policies.
- Run Critical Programs
Once data is cataloged, classified, and assigned ownership, and under the guidance of a steering committee, organizations can use OvalEdge to run three core programs focused on data quality, access, and literacy.
Each program has a simple objective:
- Data literacy is about building standards in data use and increasing discoverability.
- Data quality is about improving the quality of data to make it trustworthy.
- Data access is about making secure data access an integral component of an organization's data strategy and ensuring privacy compliance through secure, managed access controls.
- IT Data Management
Underpinning the critical programs that constitute the OvalEdge progressive data governance framework is the data management efforts of a company's IT team. They play a crucial role in the framework by providing the encryption, auditing, security, and infrastructure management required for successful implementation.
Ultimately, IT supports the running of the three core data governance programs in the progressive framework.
Read more: The Four Pillars of Data Governance for Modern Enterprises
5 Data Governance Best Practices for 2026
As data volumes grow and AI adoption accelerates, these best practices will help you maintain effective governance:
- Start Small, Scale Gradually
Don't try to govern all your data at once. Begin with high-impact use cases like compliance requirements or critical business analytics. Prove value quickly, then expand.
- Automate Where Possible
Use modern data governance tools to automate data cataloging, lineage tracking, and policy enforcement. This reduces manual effort and improves consistency.
- Foster a Data-Driven Culture
Data governance isn't just a technology problem. Invest in training and education to help employees understand why data quality and security matter.
- Build Cross-Functional Teams
Data governance requires collaboration between IT, business units, compliance, and leadership. Create steering committees with representatives from each area.
- Measure and Iterate
Track metrics like data quality scores, policy compliance rates, and time to data access. Use these metrics to continuously improve your governance program.
FAQs
What is data governance in simple terms?
Data governance is the practice of managing your organization's data to ensure it's accurate, secure, accessible, and compliant with regulations. Think of it as creating rules and processes for how data is collected, stored, used, and shared across your company.
Why is data governance important for businesses?
Data governance is important because it ensures data quality for better decision-making, helps you comply with regulations like GDPR and HIPAA (avoiding fines), improves data security to prevent breaches, and enables AI and analytics initiatives by providing trustworthy data.
Who is responsible for data governance in an organization?
Data governance is a shared responsibility. Typically, a Chief Data Officer (CDO) leads the program, a Data Governance Manager enforces policies, Data Stewards maintain quality, Data Owners oversee specific data domains, and a Steering Committee provides strategic direction.
What is the difference between data governance and data management?
Data governance vs data management: Data governance sets the policies, standards, and accountability for data (the "what" and "why"). Data management is the operational execution of collecting, storing, and processing data (the "how"). Governance defines the rules; management implements them.
How long does it take to implement data governance?
Implementation time varies based on organization size and complexity. A basic program can be launched in 3-6 months with a phased approach focusing on high-priority use cases. Full enterprise-wide implementation typically takes 12-24 months.
What are the main components of a data governance framework?
The main components include: roles and responsibilities (who does what), policies and standards (the rules), data catalog (inventory of assets), quality management (ensuring accuracy), security and compliance (protecting data), and tools and technology (automation platforms).
What tools are used for data governance?
Common data governance tools include data catalogs (Collibra, Alation, OvalEdge), master data management platforms (Informatica MDM, IBM MDM), data quality tools (Talend, Ataccama), and data lineage tools (MANTA, Collibra Lineage). Many organizations use integrated platforms that combine these capabilities.
How do you measure data governance success?
Success can be measured through: improved data quality scores, reduced compliance violations, faster time to data access, increased user adoption of governed data, fewer data-related incidents, and demonstrable business impact, like better decision-making or cost savings.
Take the Next Step in Your Data Governance Journey. Data governance is no longer optional in today's data-driven world. Whether you're protecting customer privacy, enabling AI initiatives, or simply trying to make better business decisions, governed data is the foundation of success.
The progressive data governance framework gives you a practical, incremental path forward that matches your organization's pace and capabilities.
Book a call with us to find out:
|

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)