

Hadoop ETL fails when teams copy relational database habits onto distributed systems. The fix: use managed tables over Views, store data in ORC or Parquet instead of text, right-size partitions at 64–128 MB, and build pipelines in parallel phases rather than sequential chains. Choose Hive over Pig and Spark over MapReduce for new work. Validate at every phase boundary.
Hadoop ETL best practices start with a question most teams skip: are you actually using Hadoop the way it was designed, or are you just running Oracle logic on Hadoop hardware?
The distinction matters more than most teams realize.
A Wakefield Research survey found that data engineering teams spend a median of 44% of their time maintaining existing pipelines, at an average cost of $520,000 per year per organization.
In Hadoop environments, a significant share of that overhead traces back to one root cause: architectural patterns copied from relational databases that were never built for distributed compute.
The core principles for avoiding that are consistent. Use ORC or Parquet instead of text formats. Build managed tables, not Views. Right-size your partitions. Develop in parallel phases, not sequential chains. And for new development, Hive beats Pig on every practical dimension.
This guide walks through each of those decisions in detail, including why the habits that feel natural in SQL Server quietly destroy performance when you bring them into Hive.
Hadoop ETL vs Traditional ETL: What's Different
Traditional ETL centralizes transformation on a staging server before loading data into a warehouse. Hadoop distributes both storage and compute across a cluster, so transformation runs in parallel across nodes rather than on a single server. The core difference is architectural: Hadoop is built for petabyte-scale, multi-format data that would overwhelm any centralized system.
Key differences:
-
Processing model: Traditional ETL runs sequentially on one machine. Hadoop processes data in parallel across a cluster.
-
Data types: Traditional tools handle relational data. Hadoop handles structured, semi-structured, and unstructured data in the same pipeline.
-
Scalability: Traditional ETL scales vertically (bigger hardware). Hadoop scales horizontally (more nodes).
-
Transformation timing: Traditional ETL transforms before load. Most Hadoop pipelines use ELT: load raw data into HDFS first, transform on demand.
-
Schema enforcement: Traditional ETL requires schema on write. Hadoop supports schema on read, so raw data can be stored and structured later at query time.
|
Particulars |
Traditional ETL |
Hadoop ETL/ELT |
|
Processing model |
Centralized, sequential |
Distributed, parallel |
|
Data types handled |
Primarily relational |
Structured, semi-structured, unstructured |
|
Transformation location |
Staging server |
In-cluster (Hive, Spark, MapReduce) |
|
Scalability |
Vertical (bigger server) |
Horizontal (more nodes) |
|
Best for |
Moderate volumes, relational data |
Petabyte-scale, diverse data sources |
ETL vs ELT in Hadoop: Which one are you actually running?
In traditional ETL, transformation happens before data lands in the target system. Most modern Hadoop pipelines use ELT instead: raw data loads into HDFS first, then transforms on demand using the cluster's distributed compute. ELT fits Hadoop better because transformation work stays inside the cluster where the parallelism is, not on a separate staging server that becomes a bottleneck.
The distinction matters for how you design pipelines. ETL requires defined schemas upfront and a solid staging layer. ELT gives you more flexibility on schema but demands discipline in how raw data is organized in HDFS. Without that, you end up with a data swamp: technically queryable, practically useless.
Hadoop ETL best practices: Dos and don'ts

The mental model before anything else: storage is cheap, processing is expensive, and source data doesn't change between pipeline runs. Most of the practices below follow from those three facts. The table is the short version. Each section below explains the reasoning.
|
Do |
Don't |
Why |
|---|---|---|
|
Use managed tables and pre-materialize results |
Use Views built for transactional systems |
Source data is static between runs, so there's nothing for a View to recompute |
|
Size partitions at one HDFS block or more (64–128 MB) |
Over-partition by query where-clause |
Container start/stop overhead costs more than tiny partitions save |
|
Store in ORC or Parquet |
Default to text formats |
Columnar storage, compression, and predicate pushdown cut I/O and storage |
|
Build in parallel phases |
Write long sequential pipelines |
Phase development uses Hadoop's distributed compute instead of fighting it |
|
Use Hive for new development |
Start new work in Pig |
Hive has the talent pool and active investment; Pig does not |
|
Use Spark for heavy transforms |
Default to MapReduce |
Spark is faster in-memory and more flexible for iterative jobs |
|
Process only new/changed records per run |
Default to full dataset reloads | |
Full reloads re-scan the entire dataset even when 99% hasn't changed |
|
Validate outputs at every phase boundary |
Test only final pipeline output |
A bad join in Phase 2 creates a wrong Phase 3 aggregate — catching it late is expensive |
1. Use managed tables
In transactional systems, Views make sense. Data changes constantly, so a View that recomputes on demand gives you a live, consistent snapshot of the underlying data. Hadoop doesn't work that way. Between pipeline runs, source data is static.
There's nothing for a View to recompute, and you're paying compute cost every time a query runs against it. Pre-materializing results into a managed table almost always costs less and makes each stage independently testable.
On managed vs external tables: use external tables only at the point of ingestion, when you're pulling data from an outside system and need to define a schema for it. Once data is inside Hadoop, the entire workflow should run on managed tables built with Hive scripts. Managed tables are easier to govern because Hadoop tracks their full data lifecycle, which matters when you're auditing pipelines or tracing bad output back to a source.
2. Right-size your partitions (64–128 MB minimum)
Partitioning by a query where-clause is standard in relational databases. In Hadoop, the math is different. Every partition spins up a container, and the start/stop cost of that container is high.
If each partition holds less than one HDFS block (64 or 128 MB), you're spending more on container overhead than you're saving on query time.
The rule is straightforward: don't partition unless each partition will hold at least one full HDFS block of data. If you're partitioning by date and each day's data is only a few MB, consolidate. Hadoop's mapping cost is cheap. Spinning up hundreds of tiny containers per job is not.
3. Use ORC or Parquet
Text formats read every column and every row on every query. ORC and Parquet use columnar storage, so a query touching 3 columns out of 20 only reads those 3 columns from disk.
Add built-in compression and predicate pushdown, and you get meaningful cuts to both I/O and storage costs without changing any pipeline logic.
The choice between them depends on your stack. ORC performs better in Hive-heavy workloads. Parquet is the better default if you're using Spark downstream or need cross-platform compatibility. Either is a significant step up from CSV or text. If your pipelines are still running on text-based storage, this is the lowest-effort performance gain available.
4. Build pipelines in parallel phases
The instinct when writing ETL logic is to chain steps: clean, join, aggregate, write. In Hadoop, sequential pipelines leave the cluster idle at every dependency boundary and make debugging hard because there is no intermediate state to inspect.
Phase development solves both problems. Break the work into discrete stages, write each stage's output to a managed table, and let the next stage read from that table. Any two phases that don't depend on each other run in parallel. Each phase is independently re-runnable and inspectable.
|
A worked example: Building a daily customer summary.
|
5. Use Hive for new development
If you're maintaining existing Pig code, stay on it. For anything new, use Hive. The talent pool for Pig is thin, the learning curve is steep, and investment from major vendors including Cloudera, AWS, and Microsoft has slowed considerably compared to Hive.
A pipeline built in Pig today will be hard to find someone to maintain in two years. One built in Hive won't be.
The argument for Pig is usually that some logic is simpler to express in Pig's data flow syntax than in Hive SQL. That's sometimes true. It's not a good enough reason to take on maintainability risk for anything you're building from scratch.
6. Use Spark for heavy transforms
MapReduce is still valid for simple, highly parallelizable jobs. For anything computationally intensive, iterative, or multi-step, Spark is faster.
Spark processes data in memory across the cluster rather than writing intermediate results to disk between stages, which is where MapReduce loses most of its time on complex jobs.
In practice: use Hive SQL for standard batch transformations on stable schemas. Switch to Spark when you need faster execution, complex logic, or cross-platform compatibility with Parquet pipelines. MapReduce is rarely the first choice in modern Hadoop ETL design.
7. Use incremental loading instead of full reloads
Full reloads are expensive in Hadoop: every run reprocesses the entire dataset, including data that hasn't changed since the last run. At petabyte scale, this isn't a performance annoyance; it's a resource drain that compounds across daily jobs.
Incremental loading processes only records that are new or modified since the last pipeline run. Three approaches are common in Hadoop environments:
-
Timestamp-based: Compare last_updated in the source against a stored watermark value. Sqoop's --query and --where flags handle this cleanly for RDBMS sources.
-
Log-based CDC: Read source database transaction logs directly. Captures inserts, updates, and deletes. More complex to set up, but the right pattern for near-real-time pipelines.
-
Watermark tables in Hive: Store the last processed ID or timestamp as a managed table row. Update it atomically at the end of each successful run. Simple, auditable, and fits naturally into a phase-based pipeline.
The managed table pattern you're already using is exactly right for this: your watermark lives in a managed table, your incremental extract populates a staging managed table, and your transformation phases run from there.
8. Validate transformations at each phase boundary
Each managed table in a phase pipeline is a natural validation checkpoint. Use them.
At every phase boundary, run three checks before the next phase starts: row count reconciliation vs. the source or previous phase, null checks on required columns, range or format checks on any column that feeds a downstream calculation.
These don't have to be elaborate. A Hive SQL query that asserts SELECT COUNT(*) FROM phase_2_output is between an expected lower and upper bound catches most structural failures immediately.
These checks are the pipeline-specific application of broader data quality best practices, catching problems at the source rather than downstream.
The failure mode to avoid: testing only at the final output. A skewed join in Phase 2 can produce a result that looks plausible but is wrong. By the time it surfaces in a dashboard, the job has been running in production for a week.
For teams managing multiple pipelines, Apache Griffin and Great Expectations both integrate with Spark and support rule-based validation at each stage without requiring manual queries.
Monitoring and error handling in Hadoop ETL pipelines
Most Hadoop ETL failures don't announce themselves loudly. A job completes, the output lands in a managed table, and downstream queries run fine, until someone notices a number is off and traces it back to a bad record that silently corrupted an aggregate three days ago. Good monitoring catches infrastructure failures fast. Good error handling catches data failures before they compound.
Separate infrastructure failures from data failures
-
Hadoop pipeline failures fall into two categories, and treating them the same way is a common mistake.
-
Infrastructure failures (a node going down, a network drop, a YARN container getting preempted) are transient. They're safe to retry automatically. Configure Oozie or Airflow retry policies with exponential backoff: 3 retries at 5 minutes, 15 minutes, 45 minutes handle most transient failures without manual intervention.
-
Data failures (an unexpected null in a required column, a schema mismatch on an incoming file, a record that breaks your transformation logic) are not safe to retry as-is. Retrying them just re-fails the same job.
-
For data failures, the right pattern is to quarantine bad records into an error table rather than dropping them. Log the record, the failure reason, the job run ID, and the timestamp. This keeps the pipeline moving and gives you a full audit trail to debug later.
Use phase development for natural fault isolation
-
This is already in the blog, but it deserves a callout here: phase-based pipelines fail at known boundaries. When your Phase 3 aggregation job fails, you know exactly what intermediate state is in your Phase 2 managed table. You can inspect it, fix the issue, and rerun Phase 3 without touching Phase 1 or 2.
-
A monolithic sequential pipeline that fails at step 18 of 20 gives you nothing inspectable and requires a full rerun. Phase development and error handling are the same best practice viewed from two different angles.
Monitor at the job level and the data level
-
YARN Resource Manager UI gives you job-level visibility: task completion rates, failed tasks, memory usage per job. This is your first diagnostic tool when a job is slow or fails.
-
Apache Ambari or Cloudera Manager extends this to cluster-level health: node availability, disk I/O, network saturation.
-
Job monitoring tells you a job failed. It doesn't tell you whether the output data is correct. Data-level monitoring: did row counts drop by 30%? Is a column that's normally 100% populated suddenly 40% null? Requires a separate layer. This is where data observability tooling and lineage tracking come in, and it connects directly to the governance section later in the blog.
-
Set alerts for three things: job failure, job exceeding its expected SLA window, and data volume anomaly (output row count more than 2x or less than 50% of the rolling average).
Choosing the right tools for each pipeline stage
The tool you pick for each stage matters as much as the logic. Using the wrong engine at the wrong stage (MapReduce for complex iterative transforms, for example) will hurt performance regardless of how well the rest of the pipeline is designed.
Here's how the standard Hadoop ETL tools map to each stage:
|
Stage |
Tool |
Use it when |
|---|---|---|
|
Ingestion |
Apache Sqoop |
Bulk transfer from relational databases into HDFS |
|
Ingestion |
Apache Kafka / Flume |
Streaming or event-driven, low-latency arrival |
|
Transformation |
Apache Hive |
SQL-based batch transformations on stable schemas |
|
Transformation |
Apache Spark |
Complex, iterative, or performance-intensive jobs |
|
Orchestration |
Apache Oozie |
Traditional Hadoop-native scheduling |
|
Orchestration |
Apache Airflow |
Modern stacks needing flexibility and a better UI |
|
Storage format |
ORC |
Hive-heavy workloads |
|
Storage format |
Parquet |
Spark or cross-platform pipelines |
If you'd rather not hand-build pipelines, third-party tools like Informatica, Talend, and Pentaho can write ETL jobs against Hadoop and may reduce development time for teams that don't have deep Hive or Spark expertise in-house. The tradeoff is licensing cost and a layer of abstraction you'll eventually need to debug.
How Hadoop ETL has evolved: What's changed since batch-only pipelines
The original Hadoop ETL model was pure batch processing. Large jobs ran overnight, and results were ready in the morning. That model still exists, but three shifts have changed what modern Hadoop ETL actually looks like in practice.
1. Real-time and hybrid pipelines
Real-time and hybrid pipelines are now standard in data-intensive industries. Tools like Apache Kafka handle continuous data ingestion, while Apache Flink and Spark Streaming allow transformations to run as data arrives rather than in scheduled batches. Organizations in finance, retail, and telecom have moved to this model because they need near-real-time insights to act on, not overnight reports.
2. Cloud-managed Hadoop environments
Cloud-managed Hadoop has changed how teams think about infrastructure. Services like Amazon EMR, Google Dataproc, and Azure HDInsight let you run Hadoop workloads without managing physical clusters. You get on-demand compute scaling and tighter integration with cloud storage and BI tools, which cuts operational overhead significantly for teams that do not want to maintain hardware.
3. Governance as part of pipeline design
Data governance is no longer separate from pipeline design. Teams are increasingly integrating data catalogs, lineage tracking, and metadata tools directly into their Hadoop workflows. This gives you visibility into where data came from, how it was transformed, and whether it meets compliance requirements.
Most Hadoop teams still treat governance as an afterthought. When pipelines sprawl across dozens of jobs, tables, and downstream consumers, basic questions become operational blockers: where did this number come from? Which job last wrote to this table? Who has access to this column? At scale, not having answers to these questions reliably costs time and creates compliance exposure.
Hadoop ETL architecture best practices
The cleanest architectural pattern for Hadoop ETL separates extraction, transformation, and load into modular, independently testable components. If your transformation logic changes, your extraction and load layers should not need to change.
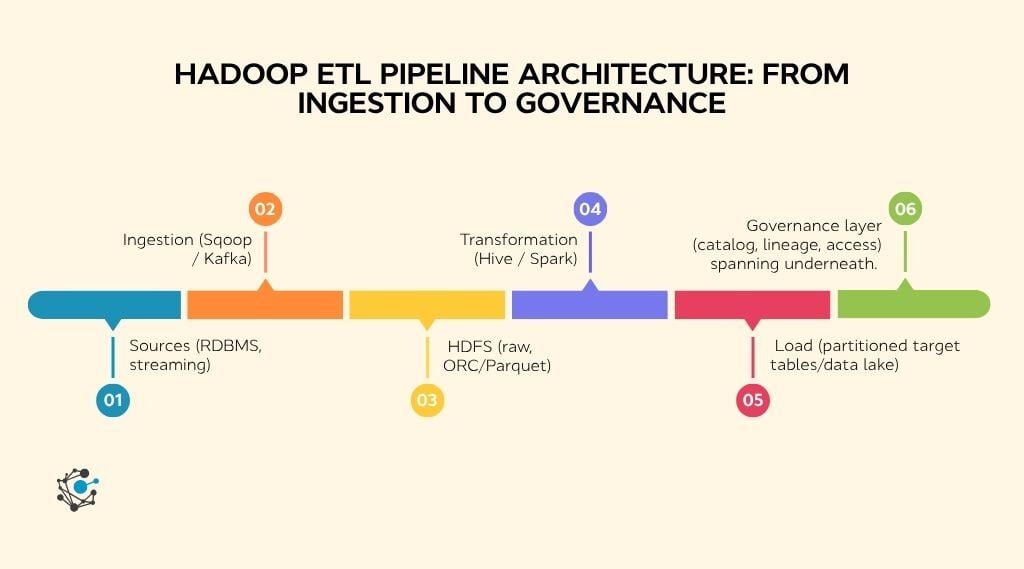
1. Extract
Pull from source systems using connectors built for distributed environments. Sqoop is the standard for bulk transfer from relational databases into HDFS. Kafka handles streaming and event-driven sources where data arrives continuously. Avoid custom extraction scripts unless there is no alternative. They are harder to maintain, harder to scale, and add operational burden that grows with every source system you add.
2. Transform
Match your compute engine to the workload. Hive SQL works well for structured transformations on stable schemas. Spark is better for complex logic, iterative processing, or jobs that need faster execution. MapReduce is still valid for simple, highly parallelizable jobs but is rarely the first choice in modern Hadoop ETL design.
3. Load
Write transformed data into target tables or data lake storage in ORC or Parquet. Partition output by the fields most commonly used in downstream queries, typically date, region, or category. Avoid over-partitioning, as covered in the best practices section above.
Conclusion
The most common mistake in Hadoop ETL development is treating it like a traditional relational database with more hardware. It isn't. The architecture rewards parallel thinking, distributed design, and the right file formats. It punishes patterns copied from Oracle or SQL Server.
If you're building or refactoring pipelines, start with the fundamentals: managed tables over Views, ORC or Parquet over text, phase development over sequential logic, and Hive over Pig for anything you need to maintain long-term. Layer in Spark for performance-intensive transforms and pick Sqoop or Kafka for ingestion based on whether your sources are batch or streaming.
Getting the pipeline right is half the problem. The other half is knowing what is inside it. As pipelines scale across dozens of jobs, tables, and downstream consumers, lineage, access governance, and metadata visibility stop being optional.
|
OvalEdge wires directly into Hadoop environments to give your team that visibility. Schedule a demo to see how it fits your stack. |
FAQs
1. What is Hadoop ETL and why is it important?
Hadoop ETL extracts data from source systems, transforms it using distributed engines like Hive or Spark, and loads it into HDFS or analytics platforms. Traditional ETL tools cannot handle the volume and variety of data modern organizations generate at scale.
2. What is the difference between Hadoop ETL and traditional ETL?
Traditional ETL transforms data on a centralized staging server before loading. Hadoop ETL distributes storage and compute across a cluster, handling structured, semi-structured, and unstructured data at petabyte scale that would overwhelm any centralized system.
3. What is the difference between ETL and ELT in Hadoop?
ETL transforms data before loading into the target system. ELT loads raw data into HDFS first, then transforms on demand using the cluster's compute. ELT fits Hadoop better because transformation stays inside the cluster where the parallelism is.
4. Is Hadoop ETL still relevant in 2026?
Yes, particularly for organizations running large-scale on-premise or hybrid data workloads. Most teams now pair Hadoop with Spark for in-memory processing and cloud-managed environments like Amazon EMR or Azure HDInsight for elastic compute. The core distributed ETL principles remain valid.
5. When should I use Hive instead of Spark for Hadoop ETL?
Use Hive for SQL-based batch transformations on stable schemas. Use Spark for complex, iterative logic or performance-intensive jobs. For most standard Hadoop ETL work, Hive is the right default. Switch to Spark when execution speed is the priority.
6. How do you handle data governance in a Hadoop ETL pipeline?
Governance in Hadoop ETL means lineage, access policies, and metadata management across your data lake. Most teams treat it as an afterthought, which creates compliance risk as pipelines scale. OvalEdge handles all three natively. See how it works.
7. What are the most common mistakes in Hadoop ETL development?
Porting Oracle or SQL Server patterns into Hive: using Views built for transactional systems, over-partitioning with small partition sizes, and writing sequential pipelines instead of parallel phases. These patterns work in relational databases but destroy performance in Hadoop.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)