Data lineage is the practice of tracking data from its origin through every transformation, movement, and destination across your systems. It tells you where data came from, how it changed, and where it went and it's foundational to data governance, compliance, and trustworthy analytics.
But "data lineage" isn't a single approach. Different organizations use different techniques depending on their infrastructure, compliance requirements, and how granular they need visibility to be.
In this guide, we cover the core data lineage techniques from system-level tracking to column-level granularity, and from manual documentation to automated parsing so you can understand which approach fits your environment and how to implement it effectively.
The 5 Core Data Lineage Techniques:
- Manual documentation — map data flows by hand; best for small environments
- Pattern-based lineage — infers relationships from metadata; technology-agnostic
- Parsing-based lineage — reverse-engineers transformation code; most accurate for complex environments
- Tagging-based lineage — tracks tagged data through a consistent transformation tool
- Query history tracking — uses query logs to reconstruct data flows in BI-heavy environments
Combined with system, object, and column-level granularity, these techniques give organizations full visibility into how data moves, transforms, and is used across their stack.
What Are Data Lineage Techniques?
Data lineage techniques are the methods organizations use to capture, track, and visualize how data moves from source systems through transformations to its final destination. Each technique differs in how lineage is collected, how accurate it is, and which environments it supports.
The five core data lineage techniques are:
|
Technique |
How It Works |
Best For |
|
Manual documentation |
Teams map data flows by hand using interviews and spreadsheets |
Small environments, early-stage programs |
|
Pattern-based lineage |
Infers relationships from metadata patterns without reading code |
Diverse or legacy environments |
|
Parsing-based lineage |
Reverse-engineers SQL, ETL code, and pipeline logic |
Complex, multi-system environments |
|
Tagging-based lineage |
Tracks tagged data through a consistent transformation tool |
Closed, single-tool environments |
|
Query history tracking |
Reconstructs flows from query logs and usage patterns |
BI-heavy, data warehouse environments |
Most enterprise data teams use a combination: automated parsing for core systems, pattern-based inference for legacy tools, and manual documentation for edge cases and compliance sign-off.
Drivers of Data Lineage
Why is data lineage so high on the data governance agenda? Today, companies collect and utilize data at a staggering rate in the era of big data. Gone are the days when BI involved targeted data sets; instead, data analysis has become industrialized.
And for a good reason. Advances in AI and other technologies enable data-driven insights to inform and influence every aspect of a business, providing companies with countless opportunities to gain a competitive edge.
However, for this process to work, users must trust the data available to them, and for that, they need to know where it came from, where it's been, and where it's going. And when you can't trace the lineage of your data, you can't determine its quality.
At the same time, maintaining data privacy compliance has become a top priority for companies in every sector. However, understanding where PII information has been and who has accessed it is necessary for the task.
The modern data ecosystem is a minefield. It’s a complex web of systems and processes that users can only navigate successfully with a dedicated governance tool.
1. Lack of trust in data products: Data-driven organizations only succeed when everyone is onboard and working towards a common goal. Yet, users are becoming increasingly disillusioned with data products because, without accurate lineage, there is no proof that they are what they claim to be.
2. Never-ending data quality issues: When you can't trace the origin and flow of data, you can't improve its quality. As a result, an absence of lineage leads to ongoing data quality issues.
3. Regulatory compliance: Data privacy compliance is just one of the many regulatory compliance statutes that impact businesses in every sector. Auditors need proof of data lineage to ensure it's been handled correctly
Related Post: Benefits of Data Lineage
Types of Data Lineage: Granularity Levels
There are three core techniques for data lineage or types of data lineage: tracking at the system, object, and column levels. These represent the main data lineage approaches organizations use to ensure visibility and trust across their data ecosystem.
1. System level: Tracking data lineage at the system level enables data teams to see how data moves through various systems, from ERP systems to data warehouses to reporting systems.
The benefit of tracking data lineage at this level is that data architecture teams can quickly understand the overall state of data lineage in the organization. It's like a high-level overview.
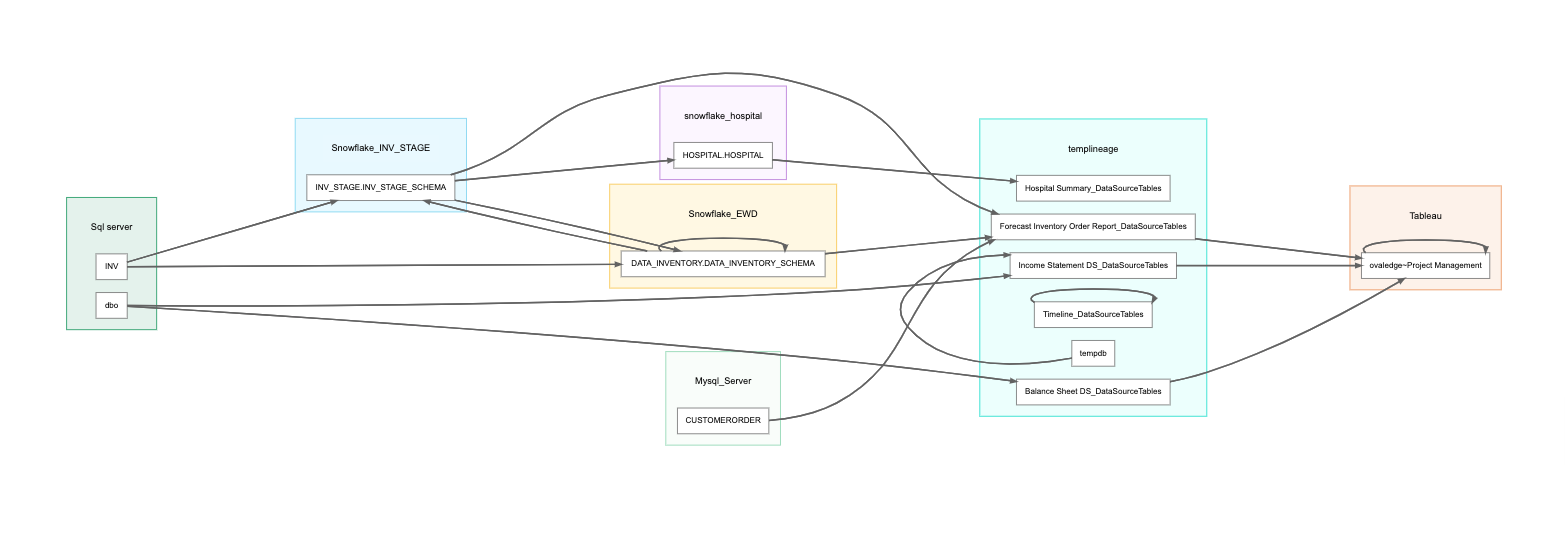
Tracking Data Lineage at the System Level
2. Object level: In OvalEdge, tables and report files are considered objects. The OvalEdge GUI depicts the lineage at the object level, which helps users communicate with the right people if there is a problem with the quality of data downstream.
You can quickly find everyone affected by a problem through impact analysis and inform and educate them about it. Object-level data lineage tracking is essential to building trust in data.
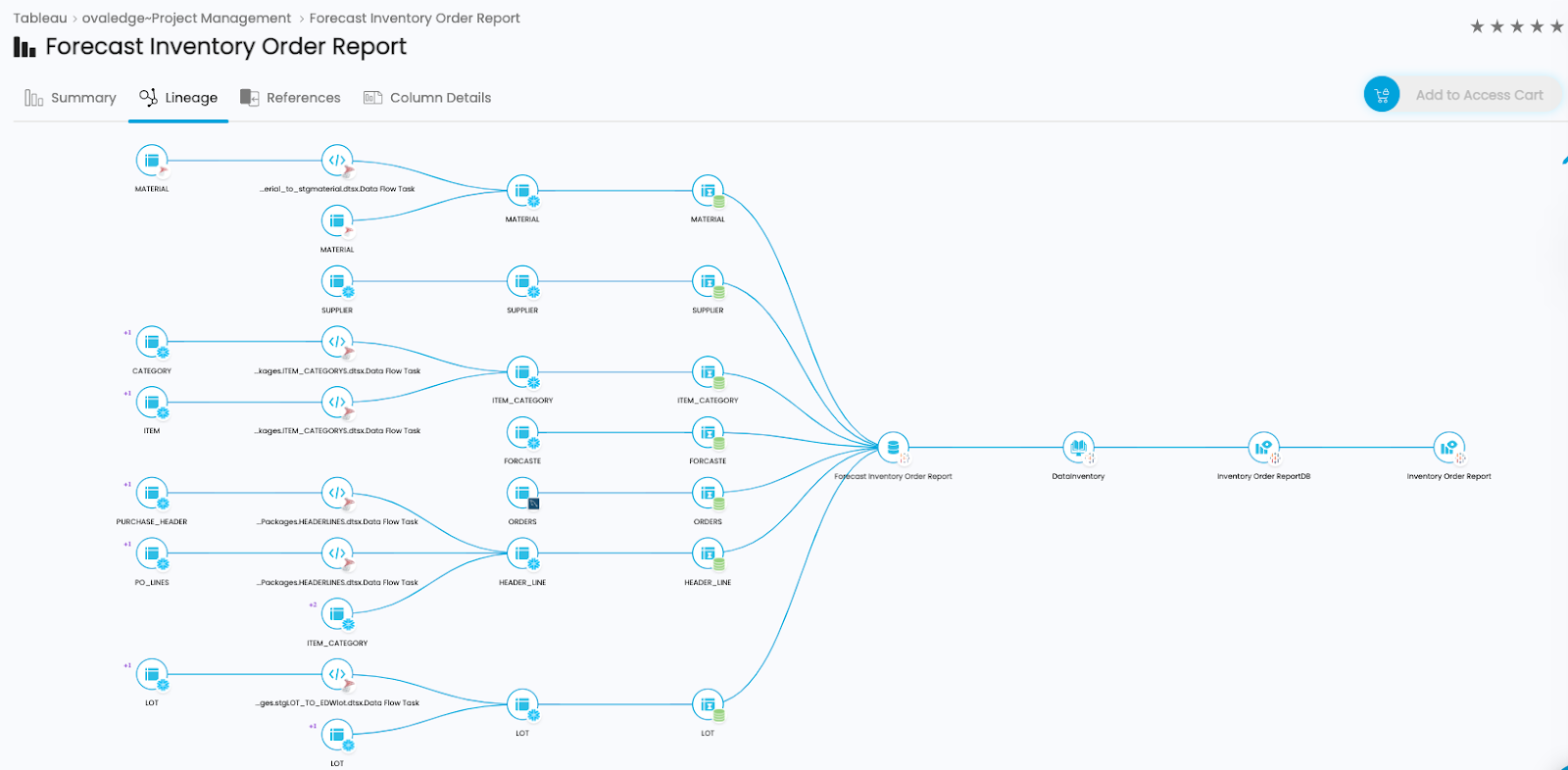
Tracking Data Lineage at the Object Level
3. Column level: All table columns, file columns, and report attributes are connected and displayed in OvalEdge. Column-level tracking is vital for compliance and impact analysis because it enables users to drill down to precise data points.
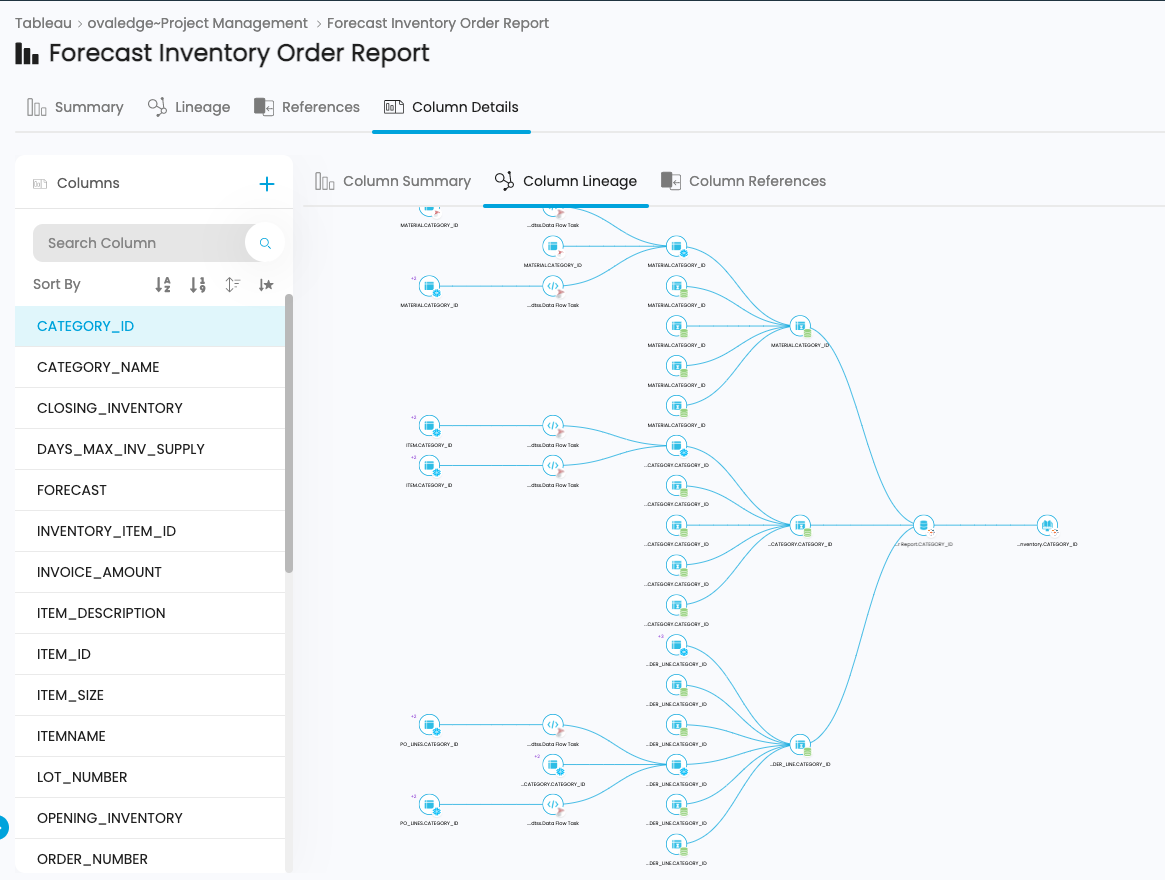
Tracking Data Lineage at the Column Level
Related Post: 3 Data Privacy Compliance Challenges that can be solved with Data Governance
Data Lineage Implementation Techniques
Granularity levels describe what you're tracking. Implementation techniques describe how you capture and build that lineage. Here are the most common approaches, each with different trade-offs in accuracy, cost, and coverage.
Manual Documentation
The most basic approach: teams map data flows through interviews, spreadsheets, and process diagrams. It requires input from data engineers, BI analysts, data stewards, and business users who know how data moves through their systems.
Manual lineage is useful in highly specific compliance scenarios where every step needs human verification. The downside is that it's time-consuming, error-prone, and nearly impossible to maintain as your data environment grows.
Best for: Small environments, early-stage governance programs, or legacy systems with no automation support.
Pattern-Based Lineage
This technique analyzes metadata table names, column names, data values, and structural patterns to infer lineage relationships without reading transformation code. If two tables share a column name with similar values, the tool connects them in a lineage map.
Pattern-based lineage is technology-agnostic, which is a major advantage. It works across systems without needing access to the underlying code. The limitation is precision: complex transformations that obscure direct relationships are harder to map accurately.
Best for: Organizations with diverse data environments or limited transformation visibility.
Parsing-Based Lineage (Code Scanning)
Parsing-based lineage reverse-engineers transformation logic by reading SQL queries, ETL scripts, Python code, and pipeline definitions to trace exactly how data moves and changes. It's the most accurate technique for end-to-end lineage because it follows the actual logic not inferences.
This is how automated lineage tools like OvalEdge work: they parse source code across databases, ETL jobs, data warehouses, and reporting systems to build comprehensive lineage automatically. The trade-off is that parsers need to understand every language and tool in your stack, which gets complex in heterogeneous environments.
Understanding the full data lineage benefits organizations expect from lineage programs helps set realistic implementation goals and avoid the over-engineering trap that slows most early-stage deployments.
Best for: Organizations that want accurate, automated, end-to-end lineage across complex multi-system environments.
Tagging-Based Lineage
Some transformation engines tag or annotate data as it moves through pipelines. Tagging-based lineage tracks those annotations from source to destination. This works well when your transformation environment is consistent and centralized, but falls apart in hybrid or multi-tool environments where not all data passes through the tagging system.
Best for: Closed or self-contained data environments with a single dominant transformation tool.
Query History Tracking
This approach captures lineage by monitoring query logs, the actual queries users run against databases and warehouses. By analyzing which tables and columns are read or written to, you can reconstruct data flows over time.
It's particularly useful in BI-heavy environments where the primary lineage signal is user queries and report generation. The limitation is that it captures usage lineage, not transformation logic, you see where data was read, but not necessarily how it was transformed.
Best for: Data warehouse and BI environments where query patterns drive most of the lineage picture.
Choosing the Right Data Lineage Technique
No single technique works for every environment. Most enterprise data teams end up using a combination, layering automated parsing for core systems with pattern-based inference for legacy tools and manual documentation for edge cases.
Here's a simple decision framework:
If you have a complex, multi-system environment with ETL pipelines, data warehouses, and BI tools, parsing-based lineage is your primary approach. Invest in an automated tool that can parse across your full stack.
If you're dealing with legacy systems that don't expose transformation logic, pattern-based lineage fills the gaps by inferring relationships from metadata.
If you operate in a regulated industry and need column-level audit trails for PII, column-level lineage combined with automated parsing is non-negotiable. You need to trace individual data fields, not just tables.
If you're early-stage or piloting a governance program, start with manual documentation to map your most critical data flows, then automate from there.
The goal isn't perfect lineage everywhere; it's comprehensive lineage where it matters most: regulated data, business-critical pipelines, and anything that feeds executive reporting.
|
Technique |
Accuracy |
Automation Level |
Best Environment |
Key Limitation |
|
Manual documentation |
Depends on contributors |
None |
Small, early-stage |
Does not scale |
|
Pattern-based |
Medium |
High |
Legacy, diverse stacks |
Less precise for complex transforms |
|
Parsing-based |
High |
High |
Multi-system enterprise |
Requires parser for each tool |
|
Tagging-based |
High (where applied) |
Medium |
Single-tool environments |
Breaks in multi-tool stacks |
|
Query history |
Medium |
High |
BI and warehouse environments |
Captures usage, not transformation logic |
Data Lineage Best Practices
Implementing data lineage effectively depends on your organization's current maturity level. Most teams move through four stages: reactive (fixing problems after they occur), passive (documenting lineage manually for specific audits), active (automated lineage across core systems), and governed (lineage embedded in every data workflow as a continuous operational capability).
Start with high-impact use cases, not comprehensive coverage: Attempting to instrument every system at once stalls most lineage programs. Start with the data pipelines that feed regulated reports, executive dashboards, or AI models. Prove value in a narrow scope, then expand. Early wins build the organizational support needed for broader adoption.
Prioritize automation over manual documentation: Manual lineage documentation does not scale. As pipelines multiply and schemas change, keeping hand-maintained records accurate becomes a full-time effort with no end. Invest in automated parsing tools early. The setup cost is higher, but ongoing maintenance becomes sustainable instead of a permanent burden.
Implement column-level lineage for regulated data first: System-level and object-level lineage give you architecture visibility. Column-level lineage gives you compliance capability. For any data subject to GDPR, HIPAA, SOX, or BCBS 239, field-level tracking is not optional. Start at column level for PII and regulated datasets before expanding to everything else.
Establish naming conventions and metadata standards before scaling: Pattern-based lineage and automated parsing depend on consistent naming across tables, columns, and pipelines. Organizations that expand lineage tracking without first standardizing naming end up with fragmented maps full of inferred connections that are hard to trust. Define your metadata schema before connecting your tenth system.
Connect lineage to data ownership: Lineage without ownership is a map with no contact information. When a downstream impact is detected, teams need to know who to notify. Connecting lineage to a data catalog that assigns ownership to every data product turns lineage from a read-only reference into an actionable governance tool.
Treat lineage as a change management requirement, not a one-time project: Every schema change, new pipeline, and tool migration creates lineage gaps if not accounted for. The organizations that maintain accurate lineage long-term treat it as part of their change management process: no new pipeline goes live without lineage being captured, and no system is deprecated without downstream impact being assessed first.
Common Challenges in Data Lineage Implementation
Heterogeneous environments make comprehensive coverage difficult
Most enterprises run data across dozens of systems: legacy ETL tools, modern cloud warehouses, BI platforms, streaming pipelines, and increasingly AI/ML workflows. Each has different metadata formats, query languages, and API accessibility. A lineage tool that covers Snowflake and dbt perfectly may have no connector for a legacy Informatica job or a custom Python pipeline. Coverage gaps produce incomplete lineage maps that create false confidence: teams think they have full lineage when entire sections of the data estate are undocumented.
Lineage breaks when data exits governed systems
One of the most common lineage failures occurs when data is exported to Excel, loaded into a custom application, or moved through a system that the lineage tool does not support. At that point, the tracked chain ends. Organizations need explicit policies for managing lineage at system boundaries, including what happens when data enters and exits tools outside the governed environment.
Maintaining accuracy as environments change
Schema changes, pipeline refactoring, and new tool additions all create lineage drift: a state where the documented lineage no longer reflects actual data flows. Without automated updates triggered by environment changes, lineage accuracy degrades quickly. This is the primary reason manual lineage programs fail at scale.
Organizational adoption beyond the data engineering team
Lineage tools are often built by engineers for engineers. Compliance teams, business analysts, and data stewards need different views of lineage: business-context framing, regulatory mapping, and plain-language impact explanations rather than technical pipeline graphs. Tools that only expose technical lineage limit organizational value to the group that built it.
Column-level lineage complexity in transformation-heavy environments Column-level lineage requires the tool to understand every transformation at the field level: when a column is renamed, derived from multiple sources, or partially masked. In complex ETL environments with hundreds of transformations, building accurate column-level lineage requires deep parser support for every language and tool in the stack. This is achievable with the right platform, but organizations that underestimate this complexity often settle for object-level lineage when compliance actually requires column-level.
How to Build and Visualize Data Lineage
Building data lineage is a two-part challenge: capturing lineage signals and making them visible in a way teams can actually use.
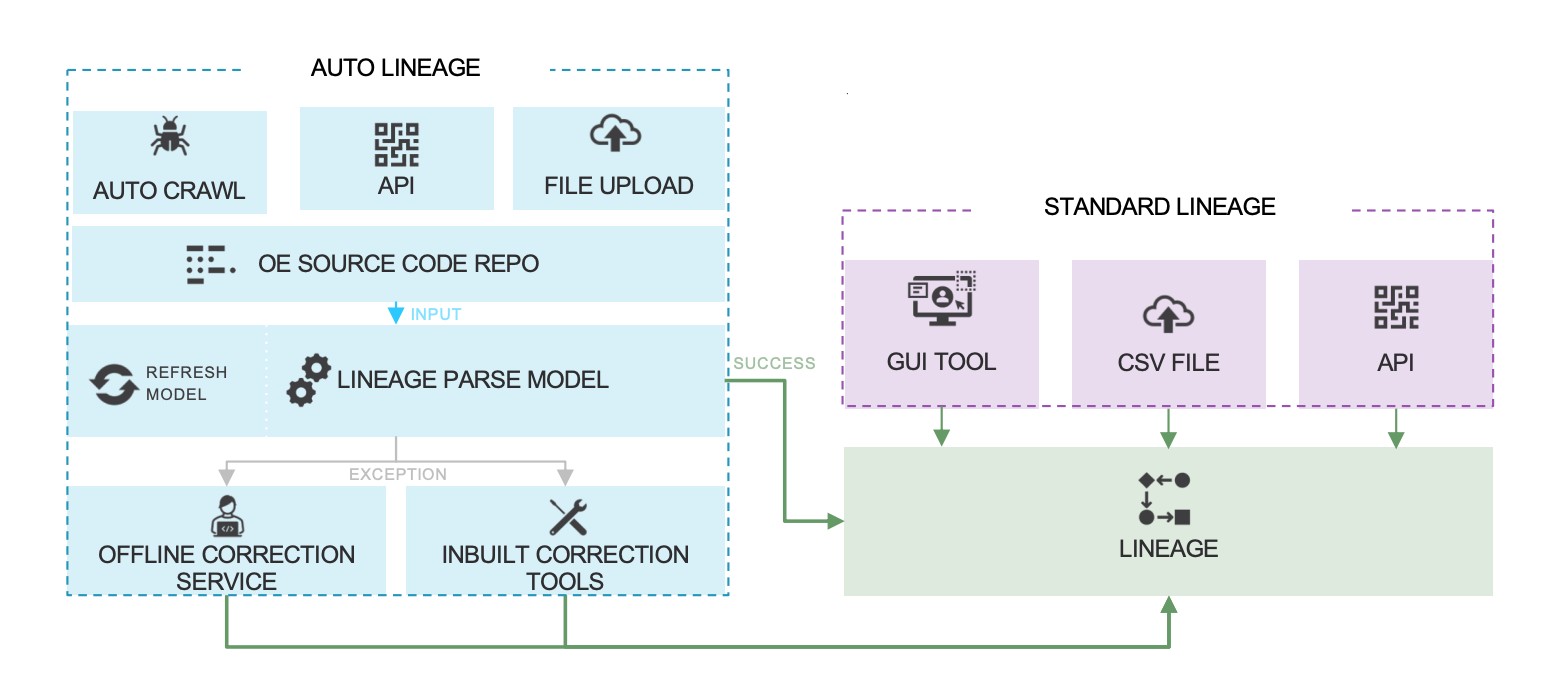
Manual Lineage Building
Some organizations choose to build lineage manually, typically to meet specific compliance requirements where every documented step needs human sign-off. This involves cataloguing data sources, mapping transformation logic by hand, and maintaining those records as systems change.
The reality is that manual lineage building doesn't scale. As data volumes grow and pipelines multiply, keeping documentation accurate becomes a full-time job with no end. Most organizations start manually and transition to automation as their data environment matures.
Automated Lineage Building
Automated lineage tools parse source code across all connected systems, ETL pipelines, SQL databases, data warehouses, reporting tools, and build lineage graphs without manual input. Once a system is connected and parsed, lineage is generated automatically and updated when pipelines change.
The key advantage here isn't just speed. Its completeness. Automated tools capture lineage across every connected system simultaneously, including transformations that happen inside black-box tools that users might never think to document manually.
OvalEdge automates lineage building by connecting to your data ecosystem and running reverse-engineering logic across all supported sources. The result is a continuously updated lineage map at system, object, and column levels accessible through a visual interface that data stewards, analysts, and engineers can all use.
Visualizing Lineage
Lineage visualization turns raw lineage data into something navigable. The most useful visualizations are interactive graphs that let you trace a data element upstream to its source or downstream to all the reports and dashboards that depend on it.
At the column level, this is especially powerful for compliance: you can trace exactly where a piece of personally identifiable information originated, how it was transformed, who accessed it, and where it ended up, the kind of audit trail that GDPR, CCPA, and HIPAA compliance requires.
Conclusion
Data lineage isn't a single thing you implement once. It's a set of practices and techniques that need to match your environment, your compliance requirements, and the maturity of your data governance program.
The organizations that get the most value from lineage are the ones that go beyond tracking tables and invest in column-level visibility because that's where compliance lives, where data quality issues hide, and where trust in data is either built or broken.
If you're evaluating how to implement data lineage across a complex enterprise data stack, OvalEdge automates lineage building across connected systems and surfaces it in a visual interface your entire team can use, from engineers tracing transformations to stewards managing compliance.
See how OvalEdge handles data lineage →
FAQs
1. What is data lineage and why is it important?
Data lineage is the process of tracking and recording the flow and transformation of data from its origin to its final destination. It is essential for ensuring data quality, building trust in data products, and meeting regulatory compliance requirements.
2. What are the different types of data lineage?
The main types of data lineage include system-level, object-level, and column-level lineage. System-level shows the flow of data across systems, object-level tracks tables and files, and column-level provides detailed visibility into individual data points for compliance and impact analysis.
3. What is the difference between manual and automated data lineage?
Manual data lineage involves documenting data flows by hand, through interviews, spreadsheets, and process maps. It's low-cost to start but difficult to maintain at scale. Automated data lineage uses tools that parse source code, ETL scripts, and metadata to build lineage without human input, updating continuously as pipelines change. Most organizations use both: automation for comprehensive coverage, and manual documentation for specific compliance or edge-case requirements.
4. What is column-level data lineage and why does it matter for compliance?
Column-level lineage tracks individual data fields, not just tables, as they move through systems. For compliance with regulations like GDPR, CCPA, or HIPAA, this level of granularity is essential. It lets organizations trace exactly where personally identifiable information originated, how it was transformed, and who accessed it, providing the field-level audit trail that regulators require.
5. What is pattern-based data lineage?
Pattern-based lineage analysis analyzes metadata such as matching column names and data values across tables to infer lineage relationships without reading transformation code. It's technology-agnostic, meaning it works across diverse systems regardless of the underlying stack. It's most useful when transformation logic isn't accessible, though it's less precise than parsing-based approaches for complex transformations.
6. How does automated data lineage work?
Automated lineage tools connect to your data systems and parse source code SQL queries, ETL logic, and pipeline definitions to map how data moves and transforms. Once connected, lineage is built automatically and updated as your pipelines change. Tools like OvalEdge reverse-engineer transformation logic across databases, data warehouses, and reporting systems to generate system, object, and column-level lineage without manual input.
7. What is the difference between data lineage and data provenance?
Data lineage tracks the full journey of data origin, transformations, movement, and destination on an ongoing basis. Data provenance refers specifically to the source of a dataset: where it first came from. Lineage is dynamic and continuous; provenance is a fixed historical record. Both are components of a broader data governance program.
8. Which automated data lineage tracking solutions are most accurate?
Accuracy in automated lineage depends primarily on the depth of the parser for each system in your environment. Parsing-based solutions that reverse-engineer transformation code at the field level are the most accurate because they follow actual logic rather than inferences. Enterprise platforms including OvalEdge, Collibra, Informatica, and Atlan offer parsing-based lineage with broad system coverage. For organizations on modern data stacks (Snowflake, dbt, Databricks), platforms with native integrations for those specific systems will deliver more accurate lineage than generic parsers. The most accurate solution for your environment is the one with the deepest native support for the specific tools in your stack.
9. How do you track data lineage across multiple sources?
Tracking lineage across multiple sources requires a platform that connects to every source system and applies consistent lineage capture across all of them. In practice, this means: (1) cataloging all source systems, (2) connecting each one to your lineage platform using native connectors or parsers, (3) defining how lineage signals from different systems are mapped to a unified lineage graph, and (4) establishing a governance process for adding new sources as your environment grows. The most common failure mode is partial coverage where well-governed systems have complete lineage and legacy or custom systems have none, creating invisible gaps that undermine trust in the overall map.
10. How does data lineage improve data governance programs?
Data lineage is the operational foundation that makes governance policies enforceable. Governance defines rules: who owns data, how PII must be handled, which transformations are permitted on regulated fields. Lineage proves those rules are being followed: it shows exactly where a piece of data came from, who accessed it, how it was transformed, and where it went. Without lineage, governance is a set of policies with no verification mechanism. With lineage, compliance teams can audit data flows against policy requirements, identify violations, and provide regulators with the documented evidence chain they require for GDPR, HIPAA, SOX, and BCBS 239 compliance.
What you should do now
|

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)