.jpg)
Imagine a coworker logs in to the company’s HR portal to see his benefits and can see your salary!! What? Don’t worry, that won’t happen as these applications are built with the expertise of years of business processes. These processes determine who can see and edit what data there.
Suddenly this data is brought into a data lake or a data warehouse. How you set up data access governance here is a mighty challenge. Read more on how to solve it.
Organizations must protect data to prevent adverse events and still make it available for informed decision-making. The mechanism of providing access to the right data to the right people promptly is called data access governance.
Data access governance is a structured framework designed to control and monitor who can access organizational data and under what conditions. Establishing strong Data access governance policies help organizations secure data assets, reduce risks, and comply with regulatory requirements.
At its core, access governance refers to the processes and policies that ensure not only who can access data, but also how and when that access happens. Closely related is data access management, which operationalizes access rules through identity controls, automated provisioning, and monitoring — ensuring that data access policies are applied consistently across systems. Modern access governance frameworks marry both these aspects to create safe and compliant access workflows while supporting business agility.
What is Data Access Governance?
Users can access data through a variety of channels. It can be accessed through an application’s UI, directly from a database or data warehouse, or sometimes when data is still in transit. Data access governance enables users to control, protect, and audit data use to maintain and ensure privacy. It also protects your company’s proprietary information and intellectual property.
As organizations strive for increased analytics, providing data to various project teams, executives, and analysts in a format they can consume is critical. However, there are many common challenges that arise when granting this access and complex reasons why data isn’t freely available.
Rise of Data Platforms
To overcome siloed data and technological challenges, companies started to create data platforms, generally data lakes or warehouses. To populate a data lake, you move all the data from various applications utilizing big data technology. In contrast, you only move selected, critical data for specific use cases into a data warehouse. As organizations create data warehouses and lakes, various access challenges arise.
Access control for enterprise data
It is a critical pillar of data access governance. It involves applying granular role-based, attribute-based, or policy-based controls that ensure employees, partners, and systems have the appropriate level of data access required for their function.
Explore how OvalEdge’s access control features enable precise and scalable management of enterprise-wide data permissions.
Secure data access policies
It establishes guidelines on data usage, authentication, and authorization to prevent unauthorized access and data breaches.
Adopting dynamic, risk-based access policies that leverage automation and AI can improve security while maintaining agility. Learn more about implementing secure data access policies with OvalEdge’s automation and AI-driven governance.
Data Access Management Challenges after Data Platforms
Complex access permissions management
Organizations can use data lakes or similar platforms to aggregate curated data to overcome siloed data and technological limitations. However, it’s not easy to transfer all permissions from all applications into a data lake.
Role-based permissions are designed for each application, often with years of iteration behind their use. Essentially, the practicality of combining everything in a data lake or warehouse is incredibly challenging.
Privacy compliance and regulatory oversight
Organizations must uphold privacy compliance regulations and information security practices to enable users to identify risk areas and implement additional measures to protect confidential data. Many regulatory bodies outside of an organization impose laws around personal data with hefty fines for non-compliance. These laws require data protection and are one reason why access to PII data can’t be given universally.
Data Discoverability Challenges
As modern data platforms host vast volumes of data from multiple sources, it becomes tough to find the right data source.
Related: Data Access Management Basics & Implementation Strategy
How to govern data access in an organization?
It starts with classifying sensitive data, defining clear roles and responsibilities, and enforcing least privilege access. Organizations must continuously monitor access patterns and perform regular audits to detect anomalies and stale permissions.
OvalEdge’s platform supports this with centralized policy management and automated compliance workflows that simplify governance.
What are best practices for data access governance?
Leading practices include:
- Classifying data by sensitivity and business context.
- Implementing role-based and attribute-based access controls.
- Enforcing least privilege and separation of duties.
- Conducting periodic access reviews and audits.
- Integrating access governance with data security and privacy tools.
OvalEdge’s solutions incorporate these best practices through end-to-end data governance capabilities
Why are traditional techniques not enough for data protection in the modern era?
Traditionally, users access data via applications or through a self-service portal. Applications generally have well-defined policies, but data is manually curated for self-service and moved to a data warehouse or data lake. Afterwards, data is divided into various roles and managed by role management tools like OKTA and Active Directory.
Groups are formed that identify individuals with common access requirements needed to support the execution of their organizational roles. Data is accessed via entry into the group, where access opens up in bulk when you are assigned to the group. Anything not covered through this method goes to ad hoc workflows.
However, ad hoc access is often not well managed. Users who don’t have access don’t know what to ask for and from whom. Generally, IT has a form where users can request access to datasets they discovered through emails or searching through individual applications. The user uses this form to write the access request for a whole area or access equal to that of another individual.
Modern Data Access Governance
Here at OvalEdge, we see an emerging trend for automated data access management through policies developed by data governance. The modern method of data access management enables you to tackle the most persistent data access management challenges with a full-circle approach.
Modern data access expands the traditional method to allow for automation, discoverability, and streamlined ad hoc workflows. The process works like this. You need to build a data catalog, classify the data into various groups, design access policies based on classification, and utilize ad hoc workflows for requests that reside outside of a classification's parameters. Access is managed through policies automatically applied at the data layer.
Centralize metadata in a data catalog
The first step is to create a centralized catalog of data assets. A data catalog like the one used at OvalEdge leverages metadata for easy discoverability without exposing the actual data. Users can search and learn about the data in the ecosystem from many vantage points and request access when needed that will route to the allocated workflow for a quick turnaround. It’s easy, automated, and scalable.
Best practices for data classification
Classification is a critical step for giving role-based access to users. First, you will divide your data horizontally. The straightforward methodology is to classify horizontally based on various business functions, such as Sales, HR, Marketing, Finance, etc. Usually, applications and databases are also tied to specific business functions. With horizontal classification, assigning access owners for various categories becomes easy. For some large applications, access owners can be decided by naming conventions of tables or files.
The second task is to classify the data vertically. Vertical classification divides the data into categories like PII-Generic, PII-Complaint, Confidential, Top Secret, Standard, and Unclassified. All data which is not yet classified will come under Unclassified data. Vertical classification is an intricate process involving these steps:
- The first step for the data/access owners of the horizontally classified data is to make policies determining what data will fall under which category for their department.
- For example, deal size and total revenue within the Sales department could fall under ‘confidential.’ The commission earned by a sales rep on a deal could fall under ‘top secret.’
- Some categories will follow the same conventions across various departments.
- PII-Generic: First name, last name, email
- PII-Compliant: SSN, driver's license number
The next step is to define role-based access policies for all the categories of fully classified data.
Configure and enforce policies based on classifications
Access policies based on classifications can be framed in a data governance committee meeting based on classification groups in a robust access policy framework. You will most likely also need tools to configure this policy framework in a data warehouse or data lake.
Policies will focus on roles and the specific permissions they afford. For example, an HR manager might only have permission to access the metadata of unidentified data but complete data access to PII. You can write as many policies as are required for the different roles in your organization.
One way to keep track of access policies is to make an access matrix that shows which roles can interact with which classifications. The access matrix displays your organization's access policies and adds transparency for who can access what data.
To see an example, download the OvalEdge Access Matrix here.
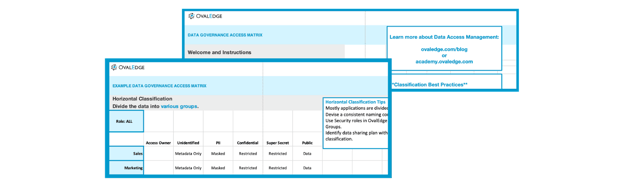
In line with the OvalEdge approach, this access is made available through a self-service portal, slashing the time it takes to retrieve data and the workload on IT.
Ad hoc workflow for continuous classification
New files and tables are created every day, bringing in more unclassified data to your organization. Because of this volume, you need an ad hoc workflow to identify these new tables, files, and reports to send to the appropriate person to confirm the classifications.
Governance Needed When Giving Access to All Data
When considering what governance is needed when giving access to all data, organizations should enforce least privilege principles, implement continuous entitlement reviews, and integrate segregation of duties controls to prevent privilege creep.
These controls must be backed by logging, alerting, and automated access challenge/remediation workflows so that broad access doesn’t weaken data protection.
Data access governance framework
Data access governance is the set of rules and controls that decide who can access which data, for what purpose, and under what conditions. A solid framework makes access predictable, auditable, and safe across data lakes, warehouses, and BI tools.
Core elements of a data access governance framework:
- Data classification: categorize data by sensitivity and business context so policies can be applied consistently.
- Ownership and accountability: assign data owners and stewards to approve access and maintain standards.
- Access controls: enforce RBAC and ABAC with least privilege and separation of duties.
- Access workflows: standardize requests, approvals, time-bound access, and revocation to prevent permission creep.
- Monitoring and audits: log access activity, review entitlements regularly, and maintain audit trails for compliance.
Conclusion
Every organization is different. They are at different places in access governance with unique handling, policies, and procedures already in place. Use the methods outlined in this blog to gain a general idea of how data access governance can be implemented from scratch and introduce what makes sense for the unique needs of your organization.
FAQs
1. What is access governance?
Access governance is the structured framework for controlling and auditing who has access to what data ensuring access rules align with compliance and business requirements.
2. How does data access management differ from access governance?
Data access management operationalizes the governance policies through tools and automation provisioning, de-provisioning, logging, monitoring, and enforcement of access rights.
3. Why is governance needed when giving access to broad sets of data?
Robust governance controls prevent unauthorized access, ensure principles like least privilege are upheld, and enforce auditing/audit trails for compliance.
4. Does data access governance support self-service access requests?
Yes — modern access governance frameworks include self-service workflows with approval processes and automated provisioning.
5. What roles are essential in access governance?
Key roles include access owners, data custodians, compliance officers, and auditors collaborating to validate and monitor who can access sensitive data and why.
What you should do now
|

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)