
By adopting aggressive metadata analysis across your complete data management environment, you can reduce the time-to-delivery of new data assets to users by as much as 70% through 2024.
This is according to Gartner’s Market Guide for Active Metadata Management, and it really drives home the potential value of active metadata management.
But what is active metadata management?
That’s what we’re going to answer in this blog, as well as:
- Why does active metadata matter?
- Active metadata benefits
- How OvalEdge supports active metadata management?
By the end of this article, you’ll have a clear idea of what it is, and why you need it. As well as practical examples of how it could affect your business.
If you need help managing your active metadata, book a demo to see how OvalEdge can help.
What Is Active Metadata?
The term ‘Active Metadata Management’ has increased in popularity thanks to Gartner, which defines it as:
“The continuous analysis of all user, system, and infrastructure reports and data governance that enable alignment and exception cases between data and their actual experiences”
If you’re new to the term, but this definition sounds familiar, that’s because it’s essentially talking about data catalogs.
Essentially, it involves cataloging your data by collecting metadata and ensuring it's current and up to date.
This includes data like name, description, relationships to other data, etc, and can be used to improve company processes, comply with regulations, build new apps, and much more.
There are two ways in which metadata is made active: automatic and human-curated, and you need a combination of the two to get the most value.
Automatic
This is when you automatically extract active metadata from the source system, and analyze the data. This will happen when you first connect to a source, but you also need to monitor for changes and update metadata accordingly.
This type of metadata can be categorized in four ways:
- Technical - Names, descriptions, columns, etc
- Lineage - Where it comes from, where it goes, etc
- Relationships - Creating diagrams and models representing how the data is connected
- Usage - Who’s consuming the information, where they’re using it, and how are they're using it
The idea is that all these things can be extracted or calculated automatically, without manual intervention.
Human curated
If someone creates a table, we can automatically pull in the data metadata, but someone needs to manually enter who created it, why they created it, etc.
Basically, we also need to capture the context surrounding the data, which requires human input.
This allows anyone else who uses the data to better understand several things:
- What’s the value?
- How is it helping the business leverage the value of the data?
- Use cases it is and isn’t used for
The automatic has less value without the human-curated metadata, and vice versa. This is why both are done through the same workflows and ecosystem, bringing the human aspect and tech together to create the most value.
Why does active metadata matter?
If data governance is an airplane, then active metadata management is the engine that powers it.
But not only can it power an airplane, it can also power a car, a boat, a helicopter, and more. These are a few other things active metadata can power:
- Data quality
- Data access
- Data literacy
- Data operations
- Data engineering
This is because all these things rely on active metadata to function, or at least make the process much easier and faster.
Essentially, active metadata creates efficiency by capturing the information and context that makes data so valuable. It’s also the reason you can search and find the data you need, rather than every task feeling like you’re looking for a needle in a haystack.
Active metadata management benefits
Improved data quality
As we’ve already touched on, data quality is a huge reason to use active metadata management. Without a high level of data quality,
This is critical because decisions made based on data analysis can only be as good as the quality of the underlying data. Poor data quality will lead to inaccurate insights, misguided decisions, wasted resources, and even reputational damage.
Active metadata management ensures that metadata is continuously updated and accurate, which leads to improved data quality.
For example, if a data source changes, the metadata can be updated to reflect the changes, which helps avoid errors and inconsistencies.
Increased efficiency
Efficient data management is important for organizations to effectively collect, store, process, analyze, and utilize their data. Inefficient data management can cost you time, money, security, and compliance!
Active metadata management improves efficiency by making it easier to find, access, and manage your data company-wide. For example, if data is properly labeled and classified with metadata, it can be easily located, retrieved, and used for analytics, saving time and effort.
Compliance
It’s impossible to talk about data in 2023 without talking about compliance. Whatever industry you’re in, you’ll inevitably have data laws and regulations you need to adhere to.
But you can’t be compliant if you don’t know which of your data is sensitive.
Active metadata management helps organizations comply with regulations by providing better visibility into the data environment, enabling data lineage tracking, and improving data governance.
This includes sensitive classification data like PII, confidential, top secret, etc., which can be done automatically or added manually.
For example, if you’re a financial services company, the Sarbanes-Oxley Act (SOX) requires companies to maintain accurate and complete financial data.
Active metadata management helps you comply by providing visibility into the lineage of financial data and by ensuring that financial data is properly classified and labeled.
Active vs. Passive Metadata: What’s the Difference?
While both active and passive metadata are crucial components of data management, they serve different purposes and have distinct roles in metadata management systems. Let’s explore the key differences:
Active Metadata:
-
Definition: Active metadata refers to metadata that is continuously updated and dynamically reflects the state of the data within a system. It is involved in real-time data operations and provides insights into data lineage, quality, usage, and access.
-
Key Characteristics: Active metadata is automatically collected, updated, and utilized in processes like data analysis, data governance, and decision-making. It’s actionable and tied to the real-time changes in the data ecosystem.
Passive Metadata:
-
Definition: Passive metadata is metadata that is static and does not change unless manually updated. It typically describes data in terms of its basic attributes, such as file names, data types, and structure.
-
Key Characteristics: Passive metadata is typically used for storage and management purposes. It is not actively involved in data governance or operational processes and does not reflect real-time changes to data.
Key Differences:
-
Real-Time Updates: Active metadata is updated in real time as data changes, while passive metadata requires manual updates.
-
Interactivity: Active metadata can trigger actions (like data quality checks or policy enforcement), whereas passive metadata is more of a reference tool.
-
Use Cases: Active metadata is used for operational data governance and analytics, while passive metadata is used for basic data management and organization.
The 4 Characteristics of Active Metadata
Active metadata is not just any data descriptor; it’s a dynamic, critical element of modern data management systems. Here are the four key characteristics that define active metadata:
-
Real-Time Data Tracking
-
Active metadata constantly tracks the changes, movement, and usage of data across the organization. It keeps itself updated as the data evolves and ensures that the most recent metadata is available to all stakeholders.
-
Example: If a data source is updated or a new data asset is created, active metadata ensures that the new metadata is immediately available to the users without manual intervention.
-
-
Data Lineage Insights
-
One of the core elements of active metadata is its ability to provide data lineage. This means that it can trace the complete journey of the data, from its source to its destination, and highlight all the transformations and operations the data has undergone.
-
Example: Active metadata will allow you to trace the path of financial data across different systems and processes, helping ensure transparency and maintain data integrity.
-
-
Contextual Information
-
Active metadata isn’t just concerned with the technical details of the data. It also captures the context surrounding the data, such as the data’s purpose, the business units it impacts, and the processes it supports.
-
Example: A marketing dataset might have metadata that includes not only its schema but also context about its intended use (e.g., customer segmentation) and the team responsible for it.
-
-
Actionability
-
Unlike passive metadata, which is static, active metadata is highly actionable. It triggers workflows and data processes, such as enforcing data access policies, quality checks, and compliance requirements, based on real-time data conditions.
-
Example: Active metadata can trigger an alert if a data source with sensitive PII is accessed by unauthorized users, ensuring immediate action is taken to secure the data.
-
Related: The importance of Data Governance in Banking and Financial Services
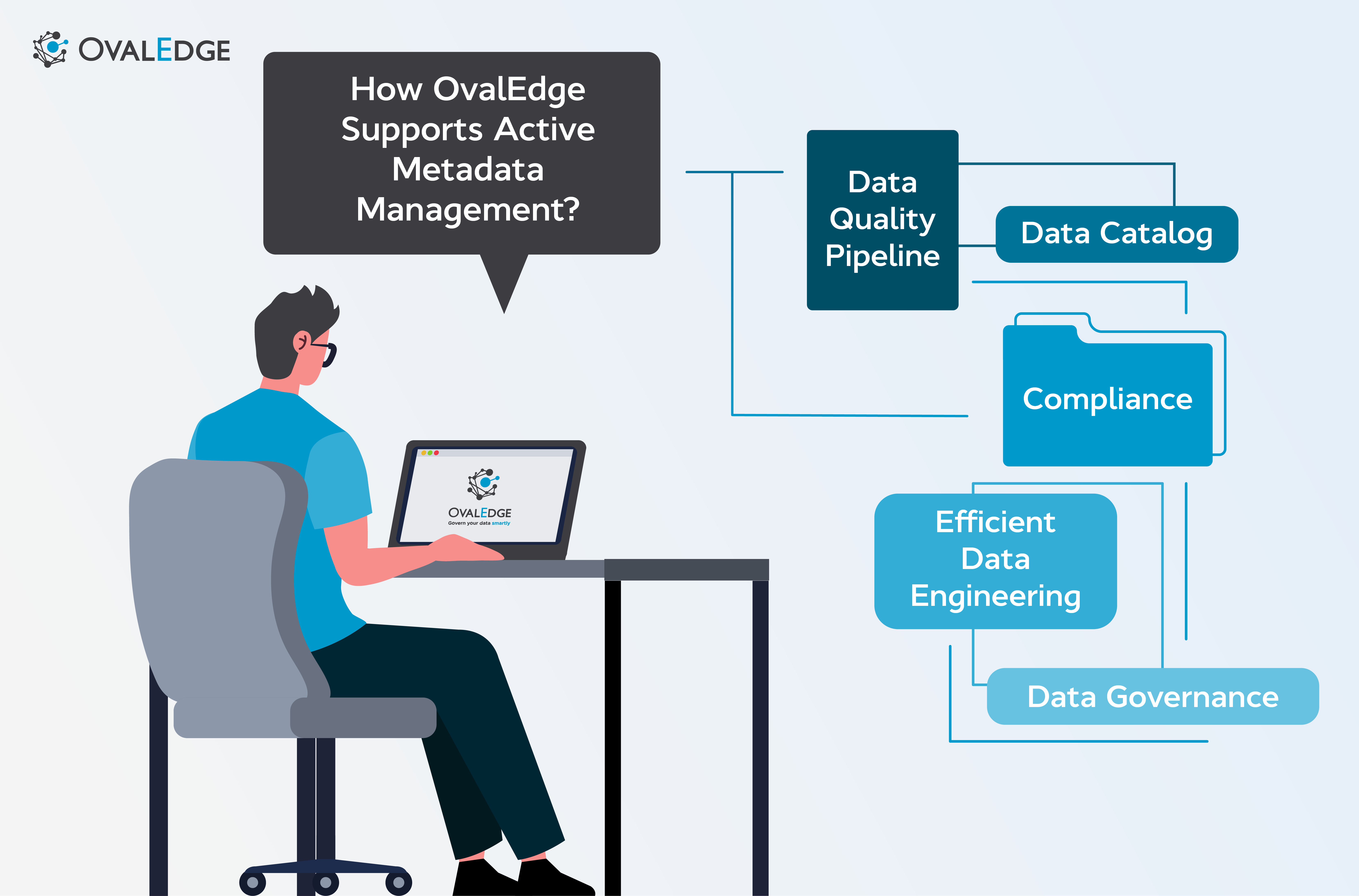
How OvalEdge supports Active Metadata Management?
All of these things have been a priority to us as we’ve built and developed OvalEdge, making active metadata management both easy and effective for our customers.
We connect all your data sources via API’s, creating active metadata for every piece of data. This includes external sources like Jira, ServiceNow, AWS, and many more.
Data Catalog
The OvalEdge data catalog is our one-stop-shop for all your data. As we covered at the start, the data catalog is what most people mean when they talk about active metadata management. That’s because this is the primary way you view your metadata.
Through our data catalog, you can do the following:
- Find accurate definitions
- Understand relationships
- Study data assets
- View data lineage
Basically, this is your starting point for active metadata management, and will help you to plan and understand everything else you can do with your data.
Data quality pipeline
We’ve explained how important data quality is to your company, so you’re probably not surprised to hear that OvalEdge helps you with your data quality pipeline.
You need effective and robust business processes supporting your data quality, and we help you at every stage of the data quality improvement lifecycle:
- Identify: Define and collect data quality issues, including where they occur and their business value.
- Prioritize: Prioritize data quality issues, ranking them according to their value and impact on the business.
- Analyze for Root Cause: Conduct root cause analysis to identify the source of data quality problems.
- Improve: Improving your data quality through automatic fixes, process changes, master data management techniques, or manual fixes.
- Control: Apply data quality rules to avoid issues in the future.
Efficient Data Engineering
One of the biggest opportunities you have when maintaining high quality active metadata is the ability to use this data in your engineering. You can build/expand apps and tools to help both your customers and your business.
It also encourages collaboration within the business by making the data more available, and helps you improve data literacy across the company.
We also give you the tools to do impact analysis, define workflows, and carry out orchestration tasks.
Compliance
The regulations like GDPR, CCPA, and others require organizations to keep customers' PII encrypted and with utmost care. Additionally, they must have the ability to delete it from all their systems when requested by the customer.
Although multiple solutions are available for data encryption and access control, finding PII (Personally Identifiable Information) data across hundreds of databases, archived storage, and data lake is a major challenge.
Our data privacy compliance tools simplify this, and by using a centralized repository for all your active metadata, it’s so much easier to stay on top of these regulations.
Related: How Chief Data Officers overcome three key challenges they face
Data governance
It’s not just external compliance that matters to your company. It’s important to consistently adhere to your own internal standards and data policies.
This is why data governance is so critical!
OvalEdge is a feature-rich data governance solution, supporting you to manage and maintain your active metadata, the way you want.
We do this with a combination of features and tools, including:
- Data classification: Help your team find, organize, and secure relevant data by classifying data into functional and security categories
- Business glossary: Create a common vocabulary across your business, making the data more accessible to everyone
- Metadata change management: Your metadata is changing all the time, so it’s vital to know exactly what’s changed, and who changed it
- Data access control: Strict access controls ensures that only the right people can access the right data
FAQs
1. What is Active Metadata Management in simple terms?
Active metadata management refers to the continuous process of collecting, analyzing, and maintaining metadata to ensure it is up-to-date, accurate, and accessible. It helps organizations enhance data governance, improve data quality, and ensure compliance by providing insights into data usage, lineage, and relationships across systems.
2. How does Active Metadata Management improve data quality?
Active metadata management improves data quality by continuously updating metadata, ensuring that any changes to data sources are reflected in the metadata. This reduces errors and inconsistencies in the data and ensures that users are always working with the most accurate and reliable data available.
3. What are the main benefits of Active Metadata Management?
The key benefits of active metadata management include:
-
Improved Data Quality: Ensures metadata is accurate and up-to-date, which leads to higher-quality data.
-
Increased Efficiency: Automates metadata management and makes data easily accessible for analytics, saving time and resources.
-
Compliance: Helps organizations comply with data privacy regulations like GDPR and HIPAA by tracking and managing sensitive data.
-
Better Data Governance: Provides visibility into data usage, lineage, and relationships, ensuring adherence to data governance policies.
4. How does Active Metadata Management support compliance?
Active metadata management supports compliance by enabling organizations to track data lineage, identify sensitive data, and ensure proper classification. It also provides a complete audit trail, making it easier to adhere to regulatory requirements such as GDPR, HIPAA, and CCPA by maintaining accurate records of data handling practices.
5. What are the differences between automatic and human-curated active metadata?
-
Automatic Metadata: Metadata is automatically extracted from data sources and continuously updated to reflect changes. It includes technical metadata, lineage, relationships, and usage.
-
Human-Curated Metadata: Involves manual input from data owners or stewards to capture the context and meaning of the data, such as the purpose of data, who created it, and its business value.
6. How does OvalEdge support Active Metadata Management?
OvalEdge helps organizations manage active metadata by:
-
Providing a comprehensive data catalog to store, classify, and access metadata.
-
Offering data quality pipelines for identifying, prioritizing, and fixing data quality issues.
-
Supporting compliance by maintaining proper classification of sensitive data.
-
Automating data access control and providing metadata change management to ensure continuous alignment with business needs.
7. Why is a data catalog important for Active Metadata Management?
A data catalog is essential for active metadata management as it provides a centralized repository where all metadata is stored, making it easier for users to find, understand, and use data. It also helps manage data lineage, track changes, and classify data for efficient governance and compliance.
8. What types of data are classified in Active Metadata Management?
Data classified in active metadata management includes:
-
Public data: Available to everyone in the organization.
-
Confidential data: Sensitive data that requires restricted access.
-
PII (Personally Identifiable Information): Data that can be used to identify individuals, which must be handled with extra care to comply with privacy regulations.
-
Restricted data: Highly sensitive data that requires the highest level of security.
9. How does Active Metadata Management integrate with data governance?
Active metadata management plays a crucial role in data governance by ensuring the accuracy, security, and compliance of data across the organization. It supports data governance policies by tracking data lineage, facilitating data classification, and controlling data access.
10. How does OvalEdge automate Active Metadata Management?
OvalEdge automates active metadata management by:
-
Extracting metadata from various data sources via APIs.
-
Providing real-time metadata updates to ensure accuracy and consistency.
-
Automating workflows for metadata discovery, data quality improvements, and compliance tracking.
-
What you should do now
|

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)