
Understanding the framework of rapidly deployable cloud data warehouses for flexible, short-term analytics.Pop-up data warehousing delivers fast, on-demand analytics by centralizing only metadata and retrieving data only when queried. Enabled by modern cloud computing and governance, it removes pipeline delays, lowers cost, and supports AI through rich contextual metadata. OvalEdge and askEdgi strengthen this model by unifying discovery, enforcing governed access, and powering temporary, query-driven compute that aligns analytics with business speed.
If you work with data long enough, you start to notice a pattern. Almost every request that comes into a data team sounds simple, but the moment you try to answer it, you run into the same barriers: missing pipelines, delayed access, and systems that do not talk to each other. This leads to stakeholders waiting longer than they should.
It is no surprise that teams get frustrated, because traditional data warehouses were built for fixed reporting models, not fast-moving questions. When answering a question means building pipelines, shaping models, and keeping systems running, even basic requests take far too long to answer.
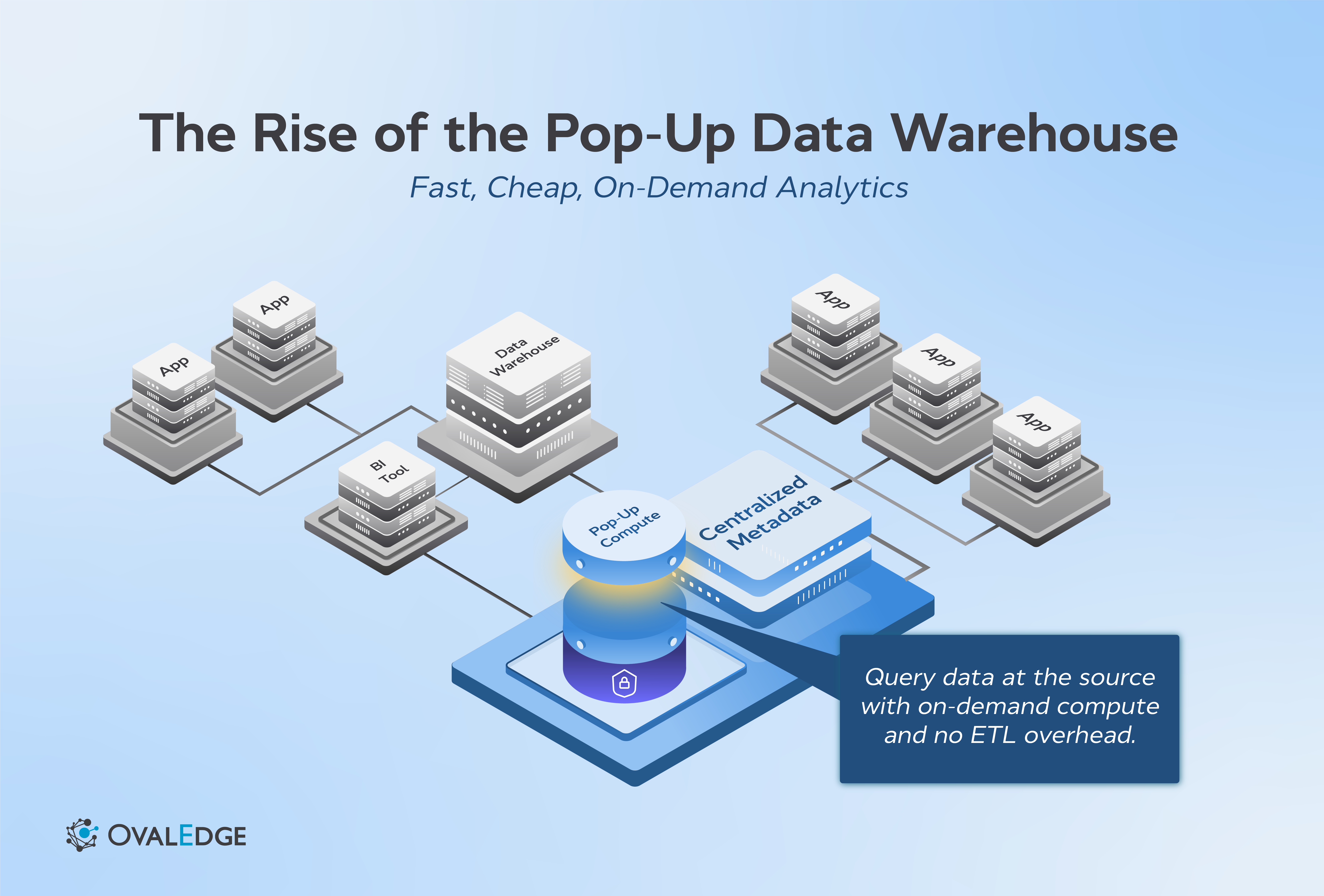
This is why the idea of a pop-up data warehouse is gaining momentum. Instead of moving all the data in advance, it collects only the metadata and retrieves real data only when someone runs a query. The system spins up the compute it needs, answers the question, and moves on.
For ad hoc requests and short-lived analysis, this approach cuts through the usual delays and makes analytics feel closer to how the business actually operates.
Markets that mirror this pop-up pattern are already scaling quickly.
In fact, serverless data warehouses are expected to reach an estimated value of USD 21.83 billion by 2033, driven by pay-per-use, on-demand analytics workloads.
In this post, we’ll explore how pop-up data warehousing works, why it matters now, and where it fits in a modern data strategy, including how metadata platforms like OvalEdge help support this shift.
Download our whitepaper on agentic analytics to understand the framework of rapidly deployable cloud data warehouses for flexible, short-term analytics.
Why a pop-up data warehouse?
A pop-up data warehouse is a temporary, rapidly deployable cloud data warehouse for short-term analytics and select projects. It spins up on demand, scales compute and storage elastically, and shuts down when the workload ends.
Teams use it for proof-of-concept analytics, migration staging, AI experiments, campaign or event reporting, and recurring monthly or yearly analyses that don’t justify permanent pipelines. This approach reduces upfront cost, speeds data validation, and lets organizations test platforms before committing to permanent architecture.
Most analytics requests inside a business fall into this short-lived category. They are simple questions that support real decisions but do not warrant new pipelines or a full warehouse buildout. Common examples include:
-
A quick view of last year’s churn by region
-
A short-term exposure check before a merger or contract
-
A one-time summary of overtime or departmental spend
These requests are important, but they rarely justify weeks of engineering work or new ETL builds. That gap between urgency and complexity is exactly where pop-up warehousing shines.
By working only with the data needed for the moment, a pop-up warehouse removes the usual slowdown. It retrieves the relevant datasets, processes the request with on-demand compute, and resets itself when finished.
This keeps engineering teams unblocked and gives business users a faster way to validate ideas, run exploratory analysis, and get answers without burdening existing systems.
|
Stat: According to Mordor Intelligence, the broader cloud data warehouse market itself is expanding quickly, growing from about USD 11.78 billion in 2025 to a projected USD 39.91 billion by 2030, at a CAGR of roughly 27.6%, which reflects how rapidly elastic, cloud-native analytics is being adopted. |
How a pop-up data warehouse works
A pop-up data warehouse plugs into all of your data sources, but it avoids the traditional step of moving everything into one central location. Instead, it waits until someone actually needs the data. The magic is in how it coordinates metadata, permissions, and temporary compute to deliver answers quickly without adding long-term overhead.
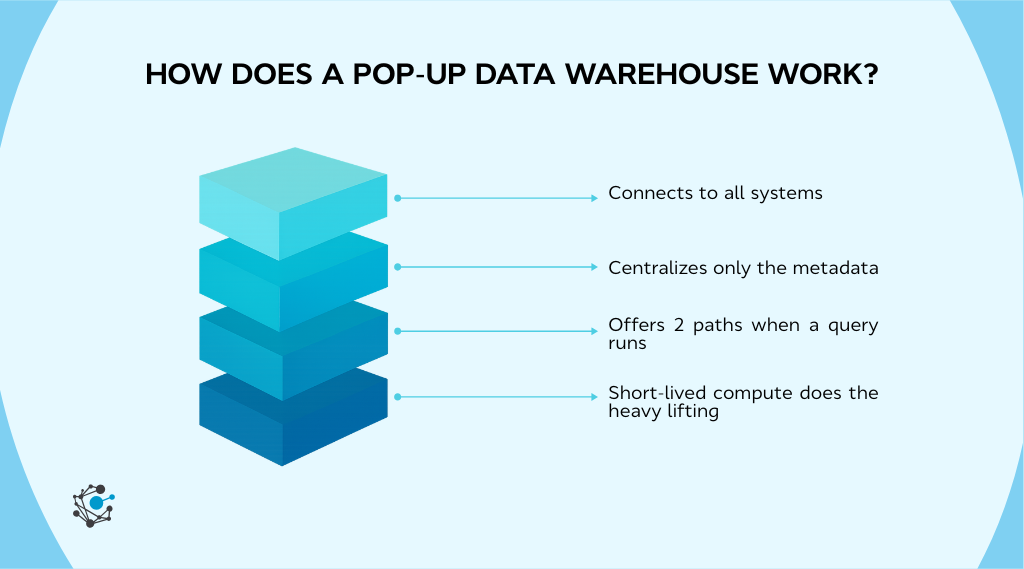
Here is how the workflow plays out in practice:
-
Connect to all systems: The platform links to databases, SaaS applications, files, documents, and any other enterprise sources. This connection is lightweight. Nothing is copied by default. The goal is simply to understand what data exists and how to reach it when needed.
-
Centralize only the metadata: Instead of relocating data, the system brings together information about the data. This includes tables, fields, lineage, classifications, business terms, and permission rules. With this metadata in one place, users can discover what they need, understand how it fits together, and see who is allowed to access it.
-
Query run: When a query runs, two paths are possible:
-
If the data already lives in a warehouse, the pop-up model uses the compute from that system. It avoids duplication and takes advantage of existing performance and optimization.
-
If the data is not already centralized, the system pulls in only the required slices of data into a temporary cache. It then uses on-demand compute to process the request.
-
-
Short-lived compute does the heavy lifting: Once the query finishes, the temporary environment is cleared. No long-term storage, no lingering pipelines, and no maintenance tasks for engineering teams. It behaves like a tent that appears when needed and folds away as soon as the job is done.
This approach gives teams the flexibility of a full warehouse without the commitment of building one for every use case. It keeps analytics fast, controlled, and scalable, allowing the organization to centralize data only when there is a clear reason to do so.
Why now? The technology breakthrough
A pop-up data warehouse would have been nearly impossible to run a decade ago. The tools simply were not fast enough, and pulling data on demand introduced too much lag for real analysis. The shift happened because core technologies matured to a point where this model is not only possible but practical.
Here is what changed:
-
Network speeds: Modern networks can move data far faster than before, which means retrieving information from remote systems no longer feels slow or disruptive. This makes on-demand access a realistic workflow instead of a bottleneck.
-
Cloud compute: Cloud platforms can spin up compute resources instantly and shut them down just as quickly. This flexibility is what allows pop-up warehouses to handle work only when needed, without paying for idle infrastructure.
-
In-memory query engines: Engines that process data directly in memory can evaluate complex queries in seconds. This removes the traditional dependency on pre-built pipelines, since compute can handle raw or semi-structured data far more efficiently.
-
AI-powered code generation: Generative AI tools, when driven by rich metadata, can create the SQL or API calls needed for analysis on demand. This reduces the manual effort of data modeling and cleansing because the AI leverages the existing lineage, definitions, and quality metrics already housed within the metadata layer.
It essentially writes the pipeline code instantly, tailored to the specific query, removing the need for a persistent, pre-built model for every ad hoc request.
With these advances, computing and storage have become fluid resources rather than fixed assets. Data no longer needs a permanent home to deliver value. Instead, metadata takes the lead role by guiding where the data lives, how it should be used, and who is allowed to access it. This shift is what makes the pop-up architecture both timely and effective.
|
Also read: Complete Guide to Data Warehouse Migration in 2026 |
Security and governance without friction
Many organizations want to give teams broader access to data, but hesitate because of the risks involved. Questions come up quickly, such as “Who is allowed to see sensitive fields?”, “How do you prevent accidental exposure of PII?”, or “ How do you ensure compliance without slowing everyone down?”
A pop-up data warehouse approaches these challenges through metadata-driven security, which makes data governance both stronger and easier to manage. Here is how it works:
-
Classification: Metadata identifies which assets contain sensitive or regulated information, how each should be handled, and what rules apply. This classification happens at scale and remains consistent across all sources.
-
Access policies: A user cannot query data that they are not approved to see. Permissions are enforced at the metadata layer, preventing unauthorized access before any data is retrieved.
-
Users interact with metadata first: Users can explore tables, definitions, and lineage without viewing actual values. This gives them full visibility into what exists while keeping sensitive fields protected.
-
Governed workflows: When someone requests access to restricted data, the system routes the request through a predefined approval process. All steps are logged, creating a complete audit trail.
-
Data only moves when the rules allow it: Once access is approved, only the required data is fetched, and only for the duration of the analysis. Nothing stays in the system longer than necessary.
By using metadata as the gatekeeper, organizations get a balance that is often hard to achieve. Data stays secure and compliant, while teams still move quickly and explore confidently without unnecessary roadblocks.
Perfect for business + AI
Modern analytics goes far beyond dashboards and SQL queries. As organizations adopt AI, the need for context becomes even more important. AI systems rely on clear definitions, ownership, policies, and semantic relationships to generate accurate and trustworthy insights.
All of this context lives in the metadata layer, which makes a pop-up data warehouse a natural fit for AI-driven analytics.
Gartner predicts that by 2027, 75% of analytics content will use generative AI for enhanced contextual intelligence, and augmented analytics is expected to become the default pattern in business intelligence.
Here is where it adds value:
-
Question-answering systems: AI tools need to understand what data means before they can answer questions reliably. Metadata provides the structure and definitions these systems depend on.
-
Generative analytics assistants: Assistants that write queries or summarize trends need clarity about tables, fields, business terms, and relationships. A pop-up warehouse gives them that context without exposing unnecessary data.
-
Automated metric definitions: Consistent metadata allows AI to generate and validate metrics using shared business rules, reducing confusion around KPIs.
-
AI-assisted governance and data quality: Metadata-driven insights help AI flag quality issues, enforce rules, and guide users toward compliant behavior.
AI does not need immediate access to full datasets to be useful. It needs to understand how data is organized, who owns it, and how it should be used. The pop-up warehouse provides that understanding up front, making it a strong foundation for both business intelligence and AI applications.
Where it fits: A complement, not a replacement
A pop-up data warehouse does not replace the need for a traditional data warehouse. Core operational analytics, such as sales pipeline, support ticket SLAs, still depend on a permanent data warehouse designed for continuous reporting.
In a modern data stack, both models coexist: the traditional warehouse for steady-state delivery, and the pop-up warehouse for agility when the questions don’t justify full modeling.
This is where a pop-up solution like askEdgi becomes especially valuable. It helps users explore the data landscape with clarity and confidence, long before any data is pulled or processed. Some of its strengths include:
-
Unified discovery: Teams can search across all data assets, understand what exists, and locate the right sources without touching actual data.
-
Context-rich understanding: askEdgi surfaces definitions, ownership, quality indicators, and lineage so users know exactly how data should be interpreted.
-
Governed access guidance: It shows who can access what and why, helping users stay within compliance boundaries.
-
Faster decision-making: By answering semantic questions, clarifying terms, and interpreting metadata, askEdgi reduces back-and-forth with data teams.
Together, these capabilities make askEdgi an ideal companion for a pop-up data warehouse strategy, supporting fast analysis while keeping governance and context at the center.
|
Did you know? Similar modern data and AI platforms have already shown tangible benefits. One McKinsey analysis found that shifting to a cloud-native data and AI platform cut time-to-insight for new use cases from 9–12 months down to roughly 2–3 months. |
The industry evolution: Why this is the next step
The shift toward pop-up data warehousing didn’t happen overnight. It reflects a steady progression in how organizations manage data, organize compute, and balance cost with flexibility. Looking back at the major phases of data architecture helps clarify why this model is the logical next step.
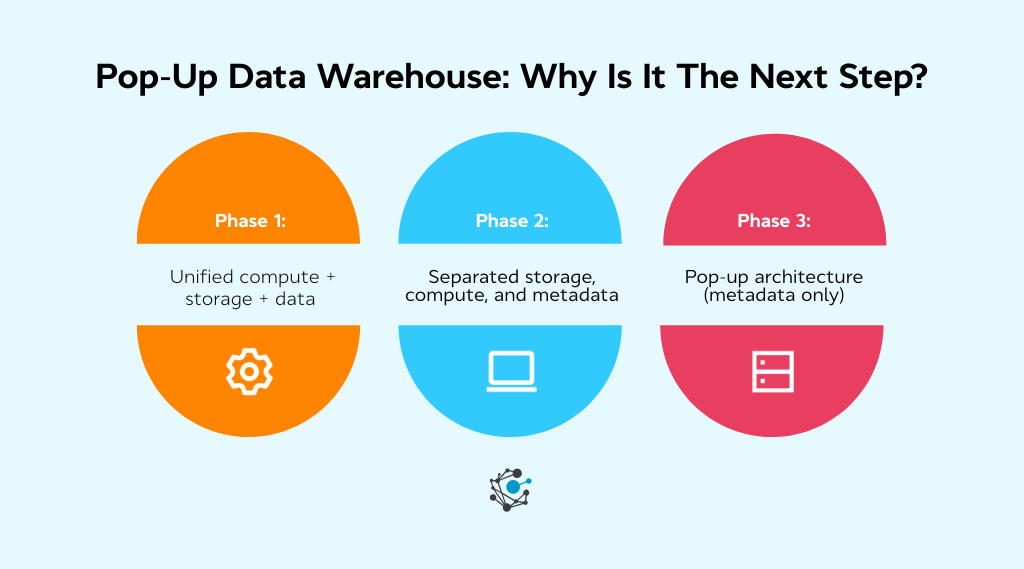
Phase 1: Unified compute + storage + data
The era of large Hadoop clusters and monolithic warehouses marked the beginning of modern data centralization. Everything lived in one place: compute, storage, and the data itself.
This approach offered strong processing power, but it came with a price. Moving every dataset into a single system was slow, expensive, and difficult to scale. For many teams, the architecture became a bottleneck rather than an enabler.
Phase 2: Separated storage, compute, and metadata
Cloud data warehouses changed the landscape by separating compute from storage. This introduced on-demand scalability and reduced the cost of maintaining large clusters. Alongside this shift, data catalogs emerged as dedicated layers for metadata and governance.
Organizations gained more flexibility, but the model still depended on physically centralizing data before it could be used. For fast-moving analytics, that requirement often kept teams waiting.
Phase 3: Pop-up architecture (metadata only)
The pop-up approach represents a natural evolution. Instead of centralizing data, it centralizes only metadata. Computing and data retrieval happen on demand, and they exist only for the duration of a query.
Nothing is permanently stored unless there is a clear reason to do so. This reduces ETL effort dramatically and allows governance to flow from metadata rather than from rigid infrastructure.
Across these phases, the industry has moved from “move everything,” to “govern everything,” to “use only what you need, when you need it.” Pop-up warehousing fits perfectly into this trajectory by offering the flexibility, efficiency, and control that modern analytics requires.
OvalEdge plays an important part in enabling this shift. Its metadata foundation gives organizations a clear understanding of their data landscape, while askEdgi acts as a pop-up data warehouse that retrieves information on demand, provides intelligent context, and guides users to the right data safely.
If you’re ready to explore how pop-up data warehousing and askEdgi can speed up decision-making across your organization, book a demo with the OvalEdge team to see it in action today.
Conclusion
A pop-up data warehouse brings data architecture closer to the way organizations actually operate.
It delivers fast insights without waiting for pipelines, reduces cost by eliminating unnecessary infrastructure, strengthens governance through metadata, and provides the context modern AI systems need to work effectively. What once required long-term engineering effort can now be delivered on demand.
This is exactly the direction platforms like OvalEdge are built to support. By centralizing and enriching metadata, OvalEdge gives teams the visibility and governance foundation required for a pop-up approach.
And with askEdgi acting as a pop-up data warehouse layer, users can explore their data landscape, understand definitions and lineage, and retrieve the information they need in a controlled, temporary environment. The result is an analytics experience that is faster, safer, and far more aligned with business expectations.
As data volumes grow and questions evolve faster than traditional architecture can keep up, adopting a pop-up mindset is becoming less of an experiment and more of a practical necessity. Platforms that combine strong metadata intelligence with on-demand access will define the next phase of analytics.
If you want to see how OvalEdge and askEdgi can help your organization move toward this model, schedule a demo today with our team for a personalized walkthrough.
FAQs
1. What makes a pop-up data warehouse different from virtualization or data federation?
A pop-up data warehouse not only queries distributed data but also creates temporary compute and storage as needed, allowing faster processing, workload isolation, and stronger governance compared to traditional federation tools.
2. Can a pop-up data warehouse support large datasets or complex analytics workloads?
Yes. It scales compute on demand, processes only the required slices of data, and isolates workloads to avoid impacting operational systems. This makes it suitable for large models, heavy transformations, or short-term processing spikes without long-term infrastructure expansion.
3. How does a pop-up data warehouse improve collaboration between business and data teams?
It minimizes dependency on engineering by giving users governed access to metadata first, enabling faster validation of questions and reducing the need for pipeline-building before exploration.
4. Is a pop-up data warehouse suitable for regulated industries?
Yes. Since access rules are enforced at the metadata layer, sensitive fields remain protected, and data moves only with explicit approval. This helps organizations meet compliance, audit, and privacy requirements while still enabling timely analysis across departments.
5. What types of projects benefit most from a pop-up data warehouse?
Short-term initiatives like audits, POCs, migrations, performance investigations, AI experimentation, and rapid strategic analysis are ideal because they require temporary, high-speed access without long-term infrastructure commitments.
6. How does askEdgi enhance the pop-up data warehouse experience?
askEdgi interprets metadata to guide users toward the right assets, understands business context, and provides governed access paths before data is queried. It helps teams get accurate answers faster by combining discovery, context, and controlled on-demand data retrieval.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)