


As businesses scale, disconnected data and unclear context lead to inconsistent insights, duplicate metrics, and broken trust in analytics. Metadata bridges this gap by explaining what data means, where it comes from, and how it’s used. It strengthens governance, improves lineage visibility, and ensures compliance across systems. The result is cleaner data, faster decisions, and trusted analytics. With OvalEdge, organizations move from fragmented data management to unified, metadata-driven governance.
Ever opened a report and thought, “Where did this number come from?” Teams everywhere face the same problem: plenty of data, but not enough understanding. One dashboard shows sales are up, another shows a drop, and suddenly, everyone questions the numbers.
The real issue isn’t the data itself. It’s the lack of context, and that’s exactly what metadata provides.
Metadata explains your data. It tells you what each number means, where it came from, who owns it, and how it’s used. Without it, data becomes noise.
According to Gartner, poor data quality costs companies around $12.9 million each year, much of it due to missing or misunderstood metadata.
As businesses scale, disconnected data and unclear context lead to inconsistent insights, duplicate metrics, and broken trust in analytics. Metadata bridges this gap by explaining what data means, where it comes from, and how it’s used. It strengthens governance, improves lineage visibility, and ensures compliance across systems. The result is cleaner data, faster decisions, and trusted analytics. With OvalEdge, organizations move from fragmented data management to unified, metadata-driven governance.
Ever opened a report and thought, “Where did this number come from?” Teams everywhere face the same problem: plenty of data, but not enough understanding. One dashboard shows sales are up, another shows a drop, and suddenly, everyone questions the numbers.
The real issue isn’t the data itself. It’s the lack of context, and that’s exactly what metadata provides.
Metadata explains your data. It tells you what each number means, where it came from, who owns it, and how it’s used. Without it, data becomes noise.
According to Gartner, poor data quality costs companies around $12.9 million each year, much of it due to missing or misunderstood metadata.
In this blog, we’ll break down data versus metadata in simple, practical terms, including what they are, how they differ, and why both matter for trusted analytics and governance. When teams understand their data through well-managed metadata, they make faster, clearer, and more confident decisions.
What are data and metadata?
Think about flipping through an old photo album. The pictures are your data; they capture details and moments. The notes or dates written beside each photo are your metadata. Without those notes, you still have the pictures, but you lose context about where or when they were taken.
The same principle applies in business. You may have accurate data, but no metadata to explain it.
Data is the raw information your organization collects, such as sales numbers, customer clicks, inventory counts, or sensor readings. It tells you what happened, but not how or why.
Metadata describes that data. It explains where it came from, what each field means, who owns it, and when it was last updated. It adds structure and traceability that make data understandable and trustworthy.
When data and metadata work together, your organization gains consistent definitions, clear ownership, and transparent lineage. This clarity strengthens governance, improves decision quality, and creates actionable insights that everyone can trust.
What is Metadata in Data Management?
-
Metadata management refers to the processes and technologies that organize, enrich, and operationalize metadata data about data so that information across systems is searchable, understandable, and reliable.
-
Automated, AI-driven metadata management keeps lineage, ownership, and data quality information up to date, enabling faster data discovery and better governance.
Data vs metadata: core differences
Here’s where things often get messy. Teams spend hours debating report numbers or tracing where a dataset came from, not because the data is wrong, but because the context around it isn’t clear. That’s the real difference between data and metadata.
Data shows you what’s happening in your business: the numbers, events, or outcomes. Metadata explains the story behind those numbers: how they were collected, where they originated, and who’s responsible for them.
Both are critical, but their roles are not the same.
|
Aspect |
Data |
Metadata |
|
Purpose |
Used to analyze and make decisions |
Adds meaning, structure, and traceability to data |
|
Change Rate |
Constantly updated as business evolves |
Changes when data definitions, ownership, or systems do |
|
Governance Role |
Managed by data producers and consumers |
Overseen by governance or stewardship teams |
|
Business Value |
Drives insights and outcomes |
Builds trust, consistency, and compliance |
While data shows what happened, metadata explains how, where, and why it happened. One cannot be trusted without the other.
In other words, Data is the collection of raw facts or figures such as sales numbers, customer clicks, product details that serve as the foundation for analysis.
Metadata, on the other hand, is “data about data,” providing context such as source, format, and ownership that helps organize, interpret, and govern data efficiently.
Key attributes that differentiate data and metadata
The easiest way to tell data and metadata apart is by their behavior and purpose.
-
Creation: Data is created through business activity, such as transactions or customer interactions. Metadata is created to describe or manage that data.
-
Consumption: Data is used in analytics and reporting. Metadata is used by systems, catalogs, and governance tools to make that data understandable and traceable.
-
Change frequency: Data changes constantly. Metadata only changes when the structure or definition of that data evolves.
-
Governance: Data must follow rules and policies, while metadata documents those rules and keeps them consistent across systems.
In short, metadata is the structure that makes data meaningful.
How to identify when you’re dealing with data or metadata
A simple way to tell the difference is to ask yourself:
“Does this information describe something, or is it the thing itself?”
|
For example:
|
If your team often struggles to trace where a metric came from or what a field name means, you’re dealing with missing metadata. This is where modern data governance platforms like OvalEdge make a difference.
Take Bedrock, a leading real estate firm. Their teams struggled with inconsistent metrics across dashboards. Each department had its own version of “total property value.” With OvalEdge, they automatically mapped data lineage across systems, showing exactly how that metric flowed from its source table through ETL pipelines, warehouses, and reports. They could instantly see who defined it, where it lived, and how it was being used.
That clarity eliminated confusion, reduced rework, and helped leadership make faster, more confident decisions.
When your data and metadata work in sync, you don’t just have numbers; you have trusted insights that drive business growth.
How Does Metadata Impact Data Management?
Metadata significantly impacts data management by:
- Enhancing data quality and integrity through clear definitions and standards that ensure consistency.
- Facilitating data search and retrieval by enabling quick location of relevant datasets via metadata tags and keywords.
- Optimizing storage and performance by identifying redundant or obsolete data that can be archived or deleted.
- Supporting collaboration through clear insights into data structure and usage, improving team productivity.
- Driving AI and analytics by providing essential context needed for machine learning model training and predictive insights.
Types and forms: data types vs metadata types
You’ve probably noticed that not all data in your organization looks the same. Understanding their different forms is what helps teams make sense of information instead of drowning in it. Once you recognize the types of data and metadata you’re dealing with, you can manage, discover, and govern your information far more effectively.
Your organization deals with various data forms:
- Structured data: Organized in tables and records (e.g., sales transactions).
- Semi-structured data: Has markers but not strict schema (e.g., JSON logs).
- Unstructured data: Videos, emails, PDFs, and other formats lacking predefined structure.
Different types of metadata support these:
- Descriptive metadata explains dataset content, making it searchable.
- Structural metadata defines data organization and relationships.
- Administrative metadata manages ownership, permissions, and updates.
- Technical metadata provides details on schema, formats, and lineage.
- Business metadata translates technical info into business terms like KPIs.
| Read More: Types of metadata |
Types of data: structured, semi-structured, and unstructured
Every organization works with a mix of data types. The way data is organized determines how easy it is to use and trust.
-
Structured data is the easiest to handle: think tables, customer records, or financial reports. It’s highly organized and easy to query. For instance, Walmart uses structured point-of-sale data to track daily transactions across thousands of stores.
-
Semi-structured data is flexible. It doesn’t live neatly in rows and columns but still carries markers that define what’s inside. JSON logs, XML files, and event streams all fall here. Netflix, for example, uses semi-structured data to track viewing behaviors, feeding algorithms that recommend what you watch next.
-
Unstructured data is the wild one with videos, PDFs, emails, or even voice notes. It’s everywhere, but difficult to process without context. IDC estimates that over 80% of enterprise data is unstructured, meaning most organizations are sitting on valuable insights they can’t fully use.
That’s where metadata comes in. It gives structure and understanding to all these data forms.
Types of metadata: descriptive, structural, administrative, technical, and business
Metadata is “data about data,” but each type serves a unique role in helping teams organize, discover, and govern information.
-
Descriptive metadata explains what a dataset is about, including the title, summary, or keywords that make it searchable.
-
Structural metadata defines how information is arranged or linked. It’s like a blueprint that connects data tables, schemas, or pages.
-
Administrative metadata tracks ownership, permissions, and when data was last updated.
-
Technical metadata digs into schema, file formats, and lineage, showing how data moves across systems.
-
Business metadata translates technical details into everyday terms, defining KPIs, business rules, and data classifications everyone can understand.
When all these types come together, metadata becomes the bridge between IT systems and business decisions.
Mapping data types to metadata types for real-world use
Here’s how different metadata types work behind the scenes to make various data forms usable and trustworthy:
|
Data Type |
Supporting Metadata Types |
Real-World Example |
|
Structured Data |
Technical, Business, Administrative |
In a CRM, metadata defines customer tables, field rules, and ownership, ensuring data accuracy and consistency across dashboards. |
|
Semi-Structured Data |
Structural, Technical, Descriptive |
Netflix tags event logs with metadata that helps analysts identify where a streaming session started, how long it lasted, and which recommendation drove the view. |
|
Unstructured Data |
Descriptive, Administrative, Business |
In marketing, campaign videos carry metadata about keywords, content type, and usage rights, making creative assets easy to find and reuse. |
One powerful real-world example of this mapping in action comes from Delta Community Credit Union (DCCU). Before OvalEdge, different departments used inconsistent definitions and had limited visibility into where data lived or how it was used.
By using OvalEdge’s metadata catalog and business glossary, DCCU connected structured, semi-structured, and unstructured data assets with clear ownership, lineage, and definitions. Business users could finally search for datasets using familiar terms, like “member growth” or “loan approval rate”, instead of technical table names.
As Dr. Su Rayburn, VP of Information Management & Analytics at DCCU, put it, OvalEdge became “a water-cooler where people collaborate and have meaningful data conversations”. That shift transformed metadata from static documentation into an active collaboration tool that improved trust, discovery, and governance across the organization.
When data and metadata types work together, your organization moves from managing information to mastering it, building a foundation of clarity, accountability, and confidence in every insight.
The role of metadata in making data useful
Metadata is the foundation of trustworthy analytics. It transforms raw data into something your teams can actually use, understand, and rely on. In simple terms, metadata gives data its meaning; it explains what it is, where it comes from, who owns it, and how it’s used.
Without metadata, even the most sophisticated data warehouse is like a library with no catalog. You might have the right information, but no clear way to find or trust it.
How metadata adds context, meaning, and accessibility
Metadata makes data searchable, explainable, and shareable. Think about how you find photos on your phone; you use dates, locations, or faces to search. That’s metadata at work, helping you make sense of thousands of files instantly.
In business, metadata does the same thing. It helps analysts and business users search using familiar words like “Q4 revenue” or “customer churn” instead of cryptic file names or SQL table codes.
| For example, when metadata powers a data catalog, you can type “marketing campaign ROI” and instantly find approved datasets, complete with details like ownership, lineage, and freshness. This saves time, reduces duplication, and ensures teams make decisions from the same trusted data source. |
That’s what makes metadata so valuable. It’s not just documentation; it’s what turns scattered information into accessible knowledge.
Metadata’s role in data discovery, governance, and documentation
Metadata also plays a vital role in data discovery, governance, and documentation. It records where data lives, who manages it, and how it moves across systems, ensuring every asset can be traced and audited.
This traceability is essential for compliance with standards like GDPR, HIPAA, and SOC 2, where organizations must demonstrate data lineage, ownership, and access control.
A great real-world example comes from Bayview, a financial services company that modernized its data ecosystem with OvalEdge. The firm faced challenges with multiple data sources, inconsistent definitions, and a lack of transparency in its reporting.
By using OvalEdge’s metadata catalog and business glossary, Bayview established a single source of truth across its departments. Teams could now search for datasets using business-friendly terms, view end-to-end lineage, and collaborate confidently with data owners.
OvalEdge also automated key governance workflows, ensuring every dataset had clear definitions and compliance visibility.
For Bayview, metadata wasn’t just a layer of documentation; it became the framework for reliable, governed, and audit-ready data.
When data becomes useless without metadata
Now, let’s flip the perspective. Imagine migrating your company’s data to a new cloud warehouse, but none of the fields are labeled, and no one remembers who owns what. You’ll find tables named “data_final_v3” or “report_test_old,” but no one can tell which one powers your dashboards.
That’s the reality for many organizations that overlook metadata. The data exists, but its purpose and trust are lost. Analysts waste hours verifying numbers, audits take longer, and decisions slow down because no one is confident in the data’s accuracy.
This is why metadata is the thread that keeps your data ecosystem coherent and reliable.
When metadata is managed effectively, your organization moves from collecting data to truly understanding it, and that’s where real business value begins.
Challenges in managing data and metadata
Every organization talks about being data-driven, but few actually trust their data enough to make confident decisions. The problem usually isn’t a lack of information; it’s poor management and missing context. Data and metadata must move together for teams to find, understand, and trust what they’re using.
Here’s what most organizations struggle with every day.
Common issues with data management
Managing data sounds simple, but complexity grows fast as systems, tools, and users multiply.
-
Data silos make collaboration difficult because each department stores information in its own systems, creating duplicate datasets and conflicting reports.
-
Poor data quality undermines trust when teams find missing values, outdated records, or inconsistent formats across sources.
-
A lack of standardization creates confusion since different teams collect and label information differently, making it hard to align KPIs.
-
Unclear data ownership leads to neglect because no one is directly responsible for maintaining accuracy or relevance.
-
Data sprawl becomes unmanageable as new applications and cloud services generate more data than teams can track.
-
Security and compliance risks increase when unclassified or unmonitored data is stored without proper access controls or retention policies.
Without clear data governance, these issues pile up and result in a bigger problem; teams stop trusting their own analytics.
Common issues with metadata management
If data tells the story, metadata explains it, and that’s where many organizations lose visibility.
-
Outdated metadata causes confusion when changes in systems or schema aren’t reflected in documentation.
-
Manual updates create inconsistencies because teams rely on spreadsheets or static catalogs that quickly become outdated.
-
Inconsistent definitions break alignment when key terms like “revenue” or “customer” are defined differently across systems.
-
Missing lineage makes traceability impossible since no one can see where a metric originates or how it was transformed.
-
Version control issues add noise as legacy metadata lingers, leading to conflicting documentation.
-
Tool fragmentation limits visibility because metadata from ETL, BI, and cloud systems never syncs in one place.
-
Ownership blind spots slow updates when there’s no designated steward or maintenance cycle to keep metadata current.
When metadata is poorly managed, discovery slows, reports contradict each other, and compliance audits become a nightmare.
Striking the right balance between data volume and metadata quality
Collecting more data doesn’t always lead to better insights. What matters most is maintaining high-quality metadata that gives your data context, structure, and meaning.
The best-performing organizations automate how they capture, catalog, and govern metadata instead of relying on manual updates. That’s where a unified platform like OvalEdge helps; it automatically maps data lineage, connects systems, and syncs metadata definitions across your environment.
By balancing growing data volumes with consistent, well-managed metadata, you create an ecosystem that is accurate, compliant, and trusted, not just a warehouse of disconnected information.
Best practices for building a strong data and metadata strategy
If your organization is collecting tons of data but still struggling to make sense of it, you’re not alone. Many teams find themselves with great tools, endless dashboards, and still, too much confusion.
A strong data and metadata strategy doesn’t start with more technology. It starts with structure, ownership, and a simple goal: helping people trust the data they work with every day.
Let’s look at the key practices that make this happen.
1. Integrate metadata management into data governance
Good data governance and metadata management should always go together. You can’t govern what you don’t understand.
Start by defining clear ownership. Every dataset should have someone responsible for keeping it accurate and up to date. This accountability is what keeps data from drifting into chaos.
Next, link your governance policies, like classification, retention, and access rules, directly to metadata. When governance and metadata move together, compliance and visibility improve automatically.
The organizations that do this well don’t just have policies; they have living systems that enforce them.
2. Design a metadata repository that works like a map
A metadata repository is your organization’s data map. It tells everyone what data exists, where it lives, how it connects, and who uses it.
A great metadata catalog should:
-
Let users search using everyday business terms, not just technical ones.
-
Show data lineage clearly so teams can trace how metrics are built.
-
Display ownership and update details right where users need them.
-
Integrate seamlessly with BI tools, ETL pipelines, and cloud storage systems.
When that “map” is accurate and easy to use, teams stop wasting time chasing the right data. Instead, they find what they need faster and make decisions with more confidence.
3. Build strong stewardship and clear documentation
Every successful data strategy needs stewardship, real people who ensure the data and its metadata stay meaningful and consistent.
Give data stewards the tools and authority to tag, document, and classify datasets by importance and sensitivity. Keep documentation simple and centralized so it’s easy for others to understand.
This practice does more than improve compliance. It builds a shared language between business and technical teams, helping everyone interpret data in the same way. That’s where trust begins.
4. Automate with active metadata
Manual documentation can’t keep up with today’s fast-moving data ecosystems. That’s where active metadata comes in.
Active metadata updates automatically as data flows through your systems. It captures lineage, tracks usage, and monitors quality in real time, ensuring that what’s documented always reflects what’s actually happening.
Automation makes governance sustainable. Instead of chasing updates, your teams can focus on insights and innovation while metadata quietly keeps everything aligned in the background.
Building a strong data and metadata strategy doesn’t happen overnight, but it starts with a mindset shift, from collecting data to connecting it.
When you combine clear governance, accessible catalogs, dedicated stewards, and automation, data stops being a challenge and starts becoming an advantage.
Metadata vs data: decision framework
By now, you know that data and metadata are inseparable. But if you had to explain the difference to someone in one minute, how would you do it? It really comes down to understanding when each one deserves your focus, because managing both at the right time is what keeps your analytics, governance, and reporting on track.
When to focus on data vs when to focus on metadata
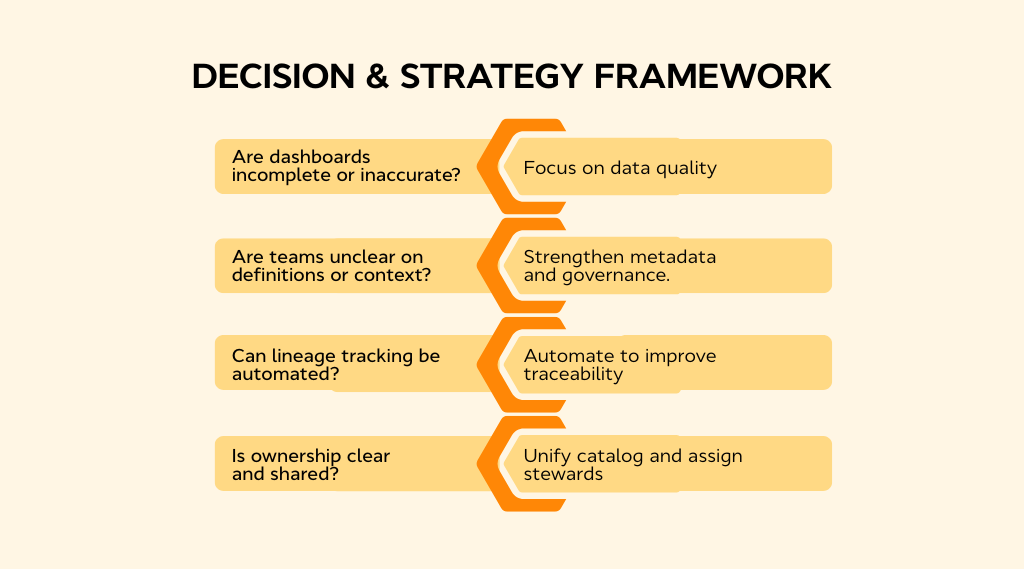
-
If your dashboards are incomplete, inaccurate, or inconsistent, focus on data quality and coverage first; you need solid content before you can describe it.
-
If your teams are wasting time finding the right dataset or arguing over definitions, focus on metadata; that’s a sign of missing context and poor governance.
In reality, both go hand in hand. Clean, connected data means nothing if no one understands it, and great metadata is useless if the data itself is broken. The goal is balance: accuracy on one side, clarity on the other.
Checklist: building a unified data–metadata strategy
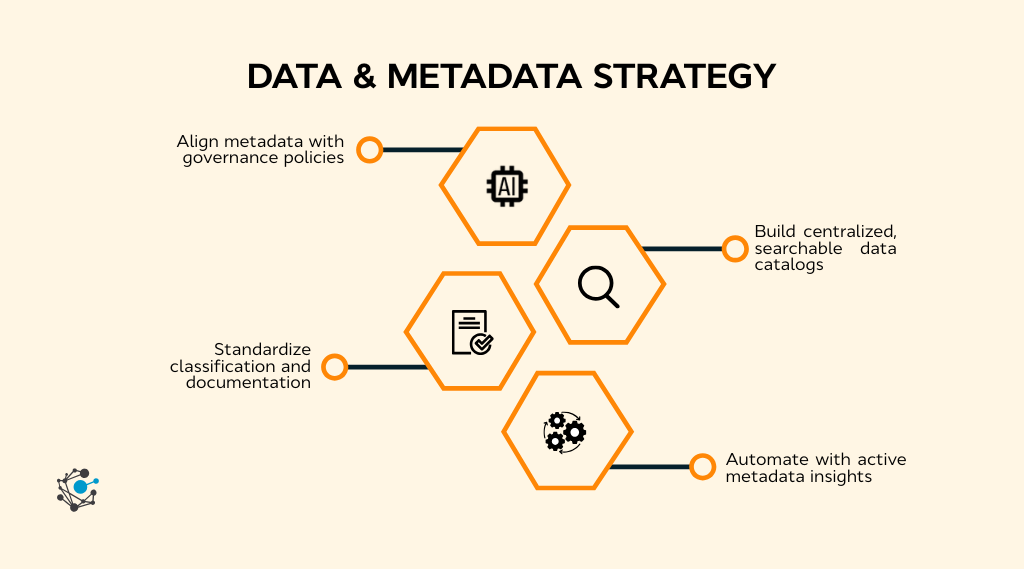
To keep both in sync, make sure you:
-
Maintain a single catalog where all data and metadata live together.
-
Assign clear ownership for updating both.
-
Automate lineage and metadata capture wherever possible.
-
Encourage collaboration between technical and business users.
When these pieces come together, your organization doesn’t just store data; it understands it. That’s the real foundation of confident, governed decision-making.
Conclusion: turning data into understanding
At the end of the day, data without metadata is just noise. You can have the most advanced analytics stack in the world, but if your teams can’t find, understand, or trust the data they’re using, insights lose their value.
Metadata is what gives data its story. Together, they form the foundation of effective governance, compliance, and confident decision-making.
If your organization struggles to connect raw data with real insight, it’s a sign your metadata strategy needs attention. Start by asking:
-
Can your teams quickly find and understand the data they need?
-
Do definitions stay consistent across reports and tools?
-
Can you trace where the data originated and who owns it?
If you hesitated on any of these, you’re not alone. Most organizations face the same challenge: managing data without enough context to make it usable.
That’s where OvalEdge helps bridge the gap. It unifies your data and metadata into one governed ecosystem, so every dataset is traceable, documented, and trusted. With automated lineage, a central business glossary, and built-in governance workflows, OvalEdge helps you transform disconnected data into reliable, insight-ready knowledge.
So before collecting more data, take a moment to give meaning to the data you already have. Explore OvalEdge’s Metadata Management Capabilities, because when your data has context, your business has confidence.
Real-World Examples and Use Cases
Leading firms use unified metadata platforms like OvalEdge to automatically map lineage, standardize definitions, and provide searchable catalogs to all users, which reduces confusion, speeds decision-making, and improves compliance.
FAQs
- What is metadata in data management and why is it important?
Metadata provides context and governance to make data trustworthy, accessible, and usable across systems. - How does metadata management support data governance?
It tracks data lineage, ownership, and usage, ensuring compliance and auditability. - What is the difference between data and metadata?
Data is the raw information; metadata provides information about that data’s origin, structure, and meaning. - How does metadata impact data management?
It improves data quality, facilitates discovery, optimizes storage, and supports advanced analytics. - What are the latest trends in metadata management?
AI-driven active metadata, real-time updates, cloud integration, and automation are transforming metadata management in 2026.
Deep-dive whitepapers on modern data governance and agentic analytics

OvalEdge Recognized as a Leader in Data Governance Solutions

.png?width=1081&height=173&name=Forrester%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.