AI is reshaping how data teams automate lineage and understand data flows across distributed systems. While open-source tools are driving much of this progress, their capabilities vary widely, especially when it comes to integration breadth, governance support, and usability at scale.
This blog unpacks how AI is being used across leading open-source lineage solutions, where these tools shine, and where they tend to fall short. It also examines the deeper challenges teams face when operationalising lineage across modern, multi-system environments, and what to consider when open-source alone isn't enough.
Data lineage tools are indispensable for organizations aiming to maintain transparency, compliance, and efficiency in managing increasingly complex data ecosystems. These tools offer automated tracking of data flows, transformations, and usage across diverse platforms, particularly in AI-driven environments.
As data volumes and architectures grow more complex, data lineage has become essential. It underpins trust in pipelines, enables faster root-cause analysis, and supports regulatory compliance. But delivering accurate, scalable lineage is challenging, requiring deep integration across orchestration layers, databases, file systems, and BI tools, each with its own quirks.
Open-source lineage tools have emerged to tackle this complexity. Built for extensibility and collaboration, they offer flexible architectures that slot into modern data stacks. Increasingly, they also leverage AI to automate dependency discovery, uncover undocumented transformations, and predict downstream impact.
This blog explores 12 open-source tools that stand out in this space. Each meets two core criteria:
-
They're released under a valid OSI-approved open-source licence.
-
They offer tangible support for lineage capture, whether through native features or integrations.
Some focus on metadata ingestion and visualisation, while others prioritise interoperability or AI-powered enrichment. Together, they reflect the current frontier of open-source lineage innovation.
Related Post: 5 Core Benefits of Data Lineage
Which Platforms Provide Traceability and Lineage for AI Data?
Several platforms specialize in providing traceability and data lineage for AI data, ensuring that AI models and datasets remain transparent, auditable, and compliant:
- OpenLineage + Marquez: An open-source lineage standard and implementation that supports end-to-end metadata tracking with extensible APIs. This platform integrates with modern data tools such as Apache Airflow, Spark, and dbt to trace AI data processes transparently.
- Acceldata: Known for real-time lineage combined with intelligent monitoring, Acceldata leverages AI agents to detect pipeline issues and trace the root cause, making it highly effective for AI data governance.
- IBM MANTA: Provides automated and detailed lineage visualization, especially effective in complex AI workflows and large data ecosystems.
- Collibra: Offers comprehensive lineage with governance integration, tracking data transformations critical in AI pipelines.
- Atlan: Delivers metadata management with automated lineage extraction from data tools like Snowflake and dbt, supporting collaborative AI data governance.
- Secoda: A user-friendly lineage platform ideal for teams beginning data lineage initiatives, with automated lineage extraction and visualization.
These platforms equip organizations to track AI data throughout its lifecycle, enhancing governance and compliance efforts while enabling scalable AI initiatives.
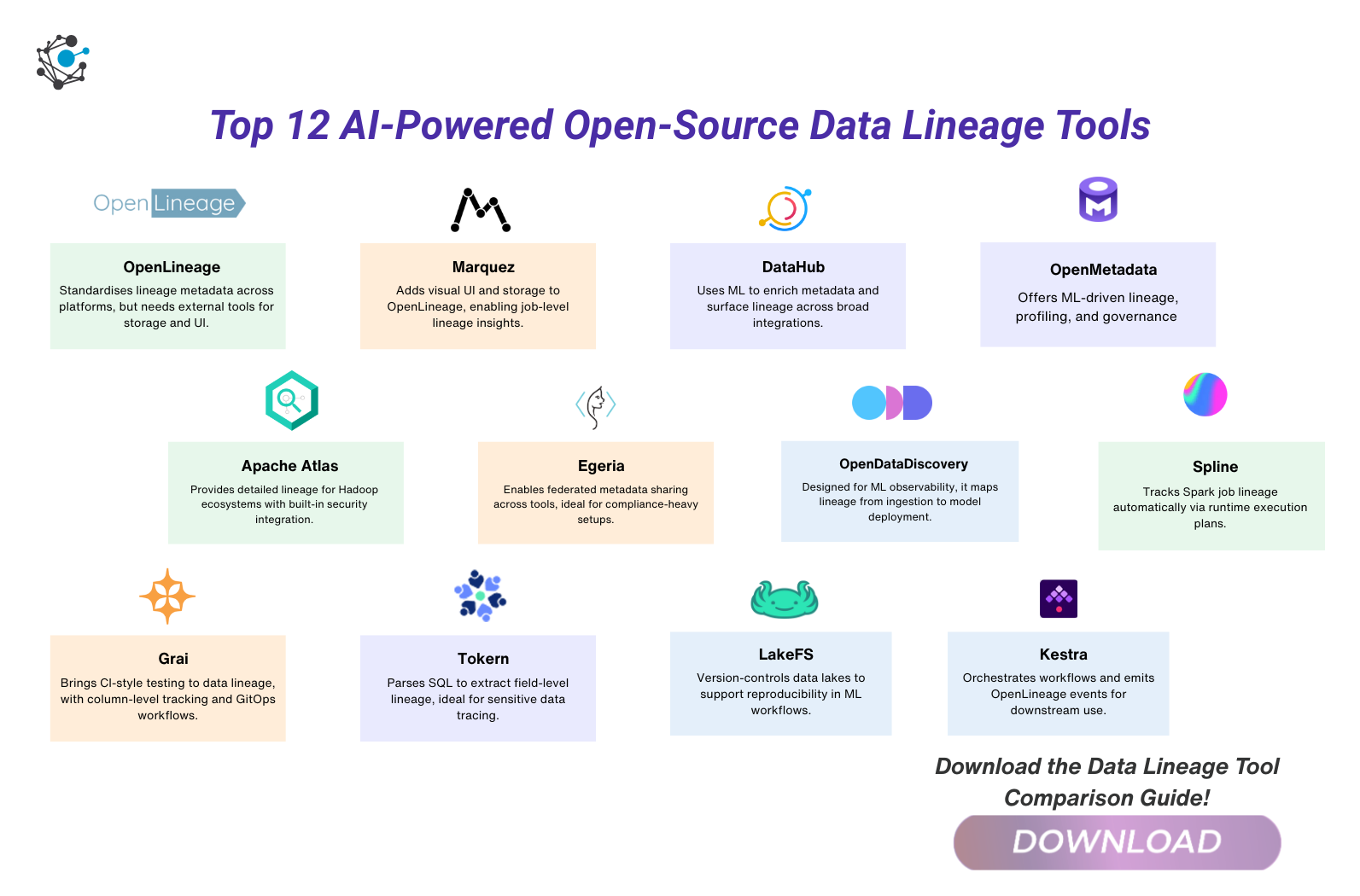
Top 12 AI-powered open-source data lineage tools
1. OpenLineage
OpenLineage
is a standard for capturing and transmitting metadata about data pipelines. It provides a vendor-neutral framework for emitting lineage events but does not include its own storage or visualisation layer. Instead, it acts as the backbone for tools like Marquez, which consume and present the data.
While not AI-powered directly, it enables AI capabilities by structuring lineage metadata consistently across platforms.
Key Features:
-
Open Specification - Standardises lineage metadata for interoperability.
-
Ecosystem Backbone - Powers tools like Marquez, Kestra, and DataHub.
-
Real-Time Event Model - Captures lineage as pipelines run.
Biggest Limitations:
-
No Visual UI - Requires external tools (e.g. Marquez) for lineage visualisation.
-
Not Plug-and-Play - Needs integration effort to emit events correctly.
-
No Native AI Capabilities - Acts as an enabler rather than a feature-rich solution.
2. Marquez
Marquezs the reference implementation of OpenLineage, adding a metadata store and visual UI. It captures job-level and dataset-level lineage from orchestration tools and exposes them via APIs and a web interface. Its AI value lies in producing structured lineage datasets for further analysis.
Key Features:
-
Native OpenLineage Support - Collects and serves OpenLineage events.
-
Visual Explorer - Navigate datasets, jobs, and run-level lineage.
-
Airflow & Spark Support - Direct integration for popular orchestrators.
Biggest Limitations:
-
Operational Setup - Needs dedicated deployment and upkeep.
-
Minimal Governance Features - Lacks policy, role, or compliance tooling.
3. DataHub
Originally built at LinkedIn, DataHub is a general-purpose metadata platform that includes lineage, search, and schema history. It uses machine learning to suggest owners, enrich metadata, and rank search results, bringing practical AI into metadata discovery and curation.
Key Features:
-
Column-Level Lineage - Tracks transformations across datasets and fields.
-
ML-Driven Metadata - Auto-suggests owners, terms, and descriptions.
-
Broad Integration - Connectors for Kafka, dbt, Snowflake, Redshift, and more.
Biggest Limitations:
-
Complex Deployments - Kubernetes and Kafka-based setup requires DevOps investment.
-
Infra Heavy - High memory and compute needs at scale.
4. OpenMetadata
OpenMetadata is a full-featured metadata platform covering lineage, quality, profiling, and governance. It uses ML for tag suggestions, relationship inference, and anomaly detection. Lineage graphs span services and show detailed table and column dependencies.
Key Features:
-
ML-Assisted Metadata - Automates tagging and suggestions.
-
Interactive Lineage Views - Table and column-level tracing with service context.
-
Built-in Testing & Policies - Link lineage with quality checks and approvals.
Biggest Limitations:
-
Steep Learning Curve - Broad capabilities demand time to learn.
-
Feature Gaps in ML - Some AI-powered features are still maturing.
5. Apache Atlas
Apache Atlas is a well-established metadata and governance tool, originally developed for Hadoop ecosystems. While it doesn’t use AI directly, it supports detailed lineage capture and integrates with Apache Ranger for fine-grained security and compliance.
Key Features:
-
Lineage & Classification - Visualise data flow and define metadata types.
-
Security Integration - Works with Apache Ranger for policy enforcement.
-
Extensible Model - Supports glossary, types, and custom entities.
Biggest Limitations:
-
Hadoop-Focused Roots - Best suited for Hadoop, with limited modern cloud support.
-
Cumbersome UI - Less intuitive than newer platforms.
6. Egeria
Egeria, backed by the Linux Foundation, provides a framework for federated metadata exchange. It focuses on stitching lineage across tools and environments. Its benefit to AI lies in providing unified metadata across hybrid ecosystems, essential for reliable AI/ML traceability.
Key Features:
-
Federated Lineage - Aggregates lineage across platforms.
-
Open APIs & Models - Built on open standards for interoperability.
-
Enterprise Orientation - Designed for compliance-heavy, regulated environments.
Biggest Limitations:
-
Complex Setup - Federation architecture increases deployment complexity.
-
Limited UI Capabilities - Basic visualisation, better suited to backend integrations.
7. OpenDataDiscovery (ODD)
ODD is a discovery and lineage tool developed with ML-first use cases in mind. It captures full-stack lineage (from ingestion through model training) making it valuable for teams focused on ML observability.
Key Features:
-
ML Pipeline Lineage - Tracks transformations, training, and deployment paths.
-
Plugin-Based - Extendable to multiple modern tools.
-
User-Friendly UI - Visual lineage across pipeline stages.
Biggest Limitations:
-
Early-Stage Project - Limited community and enterprise readiness.
-
No AI Enrichment Yet - Focuses on visibility, not prediction or inference.
8. Spline
Spline tracks lineage for Apache Spark jobs by capturing runtime execution plans. It’s lightweight and automatic, ideal for teams needing technical-level lineage for Spark applications. While it doesn’t use AI directly, the metadata it produces supports downstream AI operations.
Key Features:
-
Spark Native Integration - Captures lineage with zero code changes.
-
Compact UI - Visualises execution flow and dependencies.
-
REST API Access - Exposes lineage data for integration.
Biggest Limitations:
-
Spark Only - Doesn’t support other engines like SQL or dbt.
-
Limited Business Context - Focuses on technical flows, not semantic meaning.
9. Grai
Grai brings DevOps-style practices into data lineage. It tracks column-level lineage and lets teams test the impact of changes before merging them, similar to unit tests for data pipelines. AI is on the roadmap for impact analysis and semantic understanding.
Key Features:
-
GitOps Workflows - Test lineage in CI pipelines.
-
Column-Level Lineage - Trace schema changes across environments.
-
Developer-Friendly - Lightweight CLI and API-first approach.
Biggest Limitations:
-
Young Ecosystem - Limited integrations and features compared to mature platforms.
-
Small Community - Fewer contributors and support resources.
10. Tokern
Tokern, a minimalist, SQL-based lineage tool built to parse queries and extract field-level flows. It’s especially useful for sensitive data tracing like PII detection. While not AI-powered itself, it exports clean metadata that downstream AI systems can analyse.
Key Features:
-
SQL Parsing Engine - Works with BigQuery, Snowflake, Postgres, and others.
-
Privacy Use Cases - Identifies and labels sensitive columns.
-
Open & Lightweight - API-driven, easy to integrate.
Biggest Limitations:
-
No Visualisation Layer - Outputs are tabular or JSON-based.
-
Narrow Scope - Designed specifically for SQL-based platforms.
11. LakeFS
LakeFS isn’t a traditional lineage tool but provides Git-style version control for data lakes. This supports reproducibility and rollback, essential for ML workflows where data drift needs to be traced over time.
Key Features:
-
Git for Data - Version, branch, and merge data in object stores.
-
ML Support - Enables repeatable experiments and training sets.
-
Time Travel & Rollback - Restore past states with commit history.
Biggest Limitations:
-
Not a Lineage Graph Tool - Offers data history, not end-to-end lineage.
-
Requires Object Storage - Tailored to S3-like environments.
12. Kestra
Kestra is an orchestrator for complex data workflows, and it natively emits OpenLineage events. It isn’t a lineage visualisation tool itself, but helps generate lineage metadata as pipelines run, especially useful for teams already building DAG-based systems.
Key Features:
-
OpenLineage Emission - Emits lineage metadata directly from workflows.
-
Wide Plugin Ecosystem - Connects with dbt, Airflow, BigQuery, and more.
-
Visual Workflow UI - Design and monitor workflows in a graphical interface.
Biggest Limitations:
-
Lineage is a By-product - Focus remains on orchestration, not metadata governance.
-
Pipeline Refactoring Needed - Tools must be configured to emit lineage.
Comparing AI-powered open-source data lineage tools
Evaluating open-source tools for data lineage isn’t just about feature lists. It’s about understanding which ones can scale with your environment, plug into your workflows, and deliver clarity across your data landscape. Here's a side-by-side comparison of the 12 most relevant open-source lineage tools, including their AI integration levels and strengths across core capabilities:
.png?width=719&height=539&name=Comparing%20top%2012%20open%20source%20data%20lineage%20tools(OpenLineage%20Marquez%20DataHub%20OpenMetadata%20Apache%20Atlas%20Egeria%20OpenDataDiscovery%20Spline%20Grai%20Tokern%20LakeFS%20Kestra).png)
It describes a variety of data lineage solutions, each designed to help organizations understand and manage their data flows as they move through different systems and transformations.
Some platforms, such as OpenLineage + Marquez, provide flexibility and are favored by developers for their open APIs and seamless integration with popular data tools. Others, like Acceldata, stand out for their real-time monitoring capabilities and AI-powered insights, which allow enterprises to quickly detect and resolve issues as data moves through complex pipelines.
IBM MANTA and Collibra are ideal for businesses needing automated and highly detailed lineage mapping, with a strong emphasis on governance, transformation tracking, and compliance for complex data environments.
Meanwhile, Atlan and Secoda offer collaborative and user-friendly features suited for teams that value ease of use, automation, and quick deployment.
Overall, these platforms give organizations the tools needed to select solutions that best fit their operational priorities, compliance requirements, and budget, whether they are fast-paced enterprises, collaborative teams, or those seeking open-source flexibility.
**Disclaimer: The capability evaluations presented above are based on our independent research and product documentation as of Aug 2025. Features, pricing, and positioning may evolve. We recommend speaking directly with individual vendors for the most up-to-date and tailored information
Key challenges in AI-powered open-source data lineage tools
Despite the growing ecosystem of open-source lineage platforms, a deeper comparison reveals clear capability gaps, overlapping focus areas, and inconsistent delivery. Here's what consistently stands out across the board:
AI capabilities are still surface-level
Many tools promote “AI-powered” lineage, but the reality is more conservative. In most cases, AI is limited to metadata inference or pattern-based lineage suggestions. True automation, like context-aware discovery or adaptive learning from usage patterns, remains rare. Manual configuration is still the norm, especially in complex or hybrid data environments.
Column-level lineage is inconsistent
Not all tools offer full support for column-level lineage. While platforms like OpenMetadata, DataHub, and Apache Atlas handle this well, others deliver only partial support or none at all. For teams dealing with regulatory compliance or sensitive attribute tracing, this becomes a critical shortfall.
Without precision at the column level, data lineage becomes more of a visual map than a trustworthy control layer.
Integration coverage varies widely
Some tools shine with broad ecosystem support. OpenMetadata and DataHub, for example, connect with databases, ETL tools, orchestration layers, and BI platforms. But others, like Spline or LakeFS, serve more specialised roles. This variation creates fragmentation risks for teams managing diverse stacks.
Unless your architecture aligns neatly with the tool’s focus, you'll end up stitching solutions together manually.
OpenLineage support is uneven
OpenLineage has emerged as a unifying standard, but not all tools implement it equally. While Marquez acts as the reference implementation, others offer only partial or experimental support. This uneven adoption adds friction when teams expect plug-and-play interoperability.
Relying on OpenLineage as a backbone today still means navigating implementation details carefully.
Maturity and governance are not guaranteed
Even with active communities, many OSS tools struggle with enterprise readiness. Ease of deployment is often moderate at best. Security and governance support is limited or manually configured.
Documentation gaps and reliance on internal champions make long-term sustainability difficult without dedicated engineering time. Active GitHub stars don’t always translate into production-grade support.
Data Lineage Software Insights
Data lineage software automates the mapping and visualization of data flows across an organization, ensuring data quality and compliance with regulatory standards. Features common in leading data lineage software include:
- Automated metadata harvesting from ETL pipelines and data tools
- Interactive lineage visualization at table, column, and transformation levels
- Integration with governance frameworks and compliance monitoring
- Support for enterprise-scale data ecosystems, including legacy systems and AI data workflows
- Searchable lineage diagrams enhancing data discovery and troubleshooting
Actian's Data Intelligence Platform exemplifies such software by providing an interactive lineage graph that traces data transformations and relationships to uphold data quality and regulatory compliance.
Why modern data teams outgrow open-source lineage tools
Open-source lineage tools are a great starting point. They help surface data flows, trace transformations, and prototype lineage across cloud-native stacks. But as an enterprise needs scale, its limitations start to show.
Across systems like SAP, Salesforce, Snowflake, and BigQuery, lineage becomes fragmented. Manual diagrams, disconnected pipelines, and missing dependencies are common. Homegrown scripts struggle to keep up.
Trust in reports erodes. Governance slows down. Teams spend more time fixing lineage than using it.
Even when lineage is technically available, it's often limited to engineering teams. Without business context, glossary alignment, or clear ownership, it can’t support broader needs like impact analysis, sensitive data tracking, or policy enforcement.
At scale, teams don’t just need a lineage tool. They need a lineage platform.
How OvalEdge helps with building lineage
OvalEdge makes lineage scalable by automating the process and embedding it into daily data operations:
-
Parses logic across your entire data stack
Reads SQL, ETL scripts, and BI tools to auto-generate lineage, down to the column level. -
Connects systems end-to-end
Captures flows across ingestion, transformation, and reporting layers with no silos or missing links. -
Tracks sensitive data
Tags and monitors regulated fields across lineage paths to support compliance and mitigate risk. -
Refreshes dynamically
Updates lineage automatically as metadata changes with no manual redraws or outdated diagrams. -
Brings business context into lineage
Overlays glossaries, data quality rules, and access policies directly onto lineage graphs.
The result is a lineage that’s not just technically accurate, it’s operationally usable. Analysts can trace KPIs, engineers can debug pipelines, and stewards can monitor compliance. Lineage becomes a living, governed asset that powers decisions, not just a static diagram pulled out for audits.
Conclusion
AI-powered open-source tools have reshaped how data teams approach lineage. They’re flexible, cost-effective, and improving rapidly, especially in cloud-native environments. But as data estates grow more complex, stitching together multiple tools often leads to more work, not less.
What begins as an agile solution can become hard to govern, scale, or explain. Gaps in lineage erode trust in metrics, slow root-cause analysis, and weaken compliance.
For modern data teams, the real goal isn’t just generating lineage, it’s operationalising it. That means building a lineage that’s end-to-end, dynamic, and enriched with business meaning. Whether you start with open-source or not, your long-term success depends on scaling lineage across people, platforms, and policies.
That’s where platforms like OvalEdge come in, turning lineage from a technical checkbox into a strategic enabler of governance, quality, and confident decision-making.
FAQs
Q1: Which platforms provide traceability and lineage for AI data?
Platforms like OpenLineage + Marquez, Acceldata, IBM MANTA, Collibra, and Atlan offer traceability and lineage solutions specifically designed for AI data environments.
Q2: What are the best open source data lineage tools available in 2026?
Notable tools include OpenMetadata, OpenLineage with Marquez, Apache Atlas, and Egeria, providing robust lineage, governance, and metadata management in open-source formats.
Q3: How do data lineage tools enhance data governance?
These tools automate lineage mapping and visualization, helping organizations track data origins, transformations, and usage to ensure data quality, compliance, and efficient troubleshooting.
Q4: What factors should organizations consider when choosing data lineage software?
Considerations include scalability, integration with existing data tools, automation level, ease of use, and support for AI data workflows and compliance requirements.
Q5: How does AI integration improve data lineage tools?
AI-enhanced lineage tools provide real-time monitoring, anomaly detection, automated root cause analysis, and intelligent data flow tracking, increasing reliability and reducing downtime.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)