AI isn’t just making data catalogs smarter; it’s redefining how organizations manage metadata across their lifecycle. From connecting to data (Crawl), to enriching it with context (Curate), to making it truly accessible and actionable (Consume), AI is now embedded at every layer. This blog explores how AI transforms each stage, providing real-world examples and capabilities that extend far beyond traditional catalogs.
According to Gartner, AI data catalogs “automate various tedious tasks involved in data cataloging, including metadata discovery, ingestion, translation, enrichment, and the creation of semantic relationships between metadata.” While this highlights key capabilities, it only scratches the surface of what modern AI-powered catalogs can achieve.
It’s essential to note that while automation plays a crucial role, AI in a data catalog extends far beyond simply automating tasks.
AI infuses catalogs with intelligence, detecting complex patterns, learning from user behavior, personalizing experiences based on user role, and enabling secure, actionable insights in real-time. This intelligence permeates every stage of the metadata lifecycle, transforming catalogs from static repositories into dynamic, adaptive systems that continuously learn and evolve.
In this blog, we take a broader, more holistic view of how AI is redefining the entire metadata lifecycle. Rather than focusing on isolated features, we explore how AI transforms each critical stage, from Crawl (intelligent connection and ingestion), through Curate (contextual enrichment and governance), to Consume (insightful search, understanding, and action).
What is an AI-powered data catalog?
Traditional data catalogs indexed your metadata. AI-powered catalogs do much more: they curate, customize, and activate metadata in motion. They don’t just sit passively waiting for metadata to be ingested and tagged. Instead, they learn from usage patterns, automate stewardship, and tailor discovery based on individual personas.
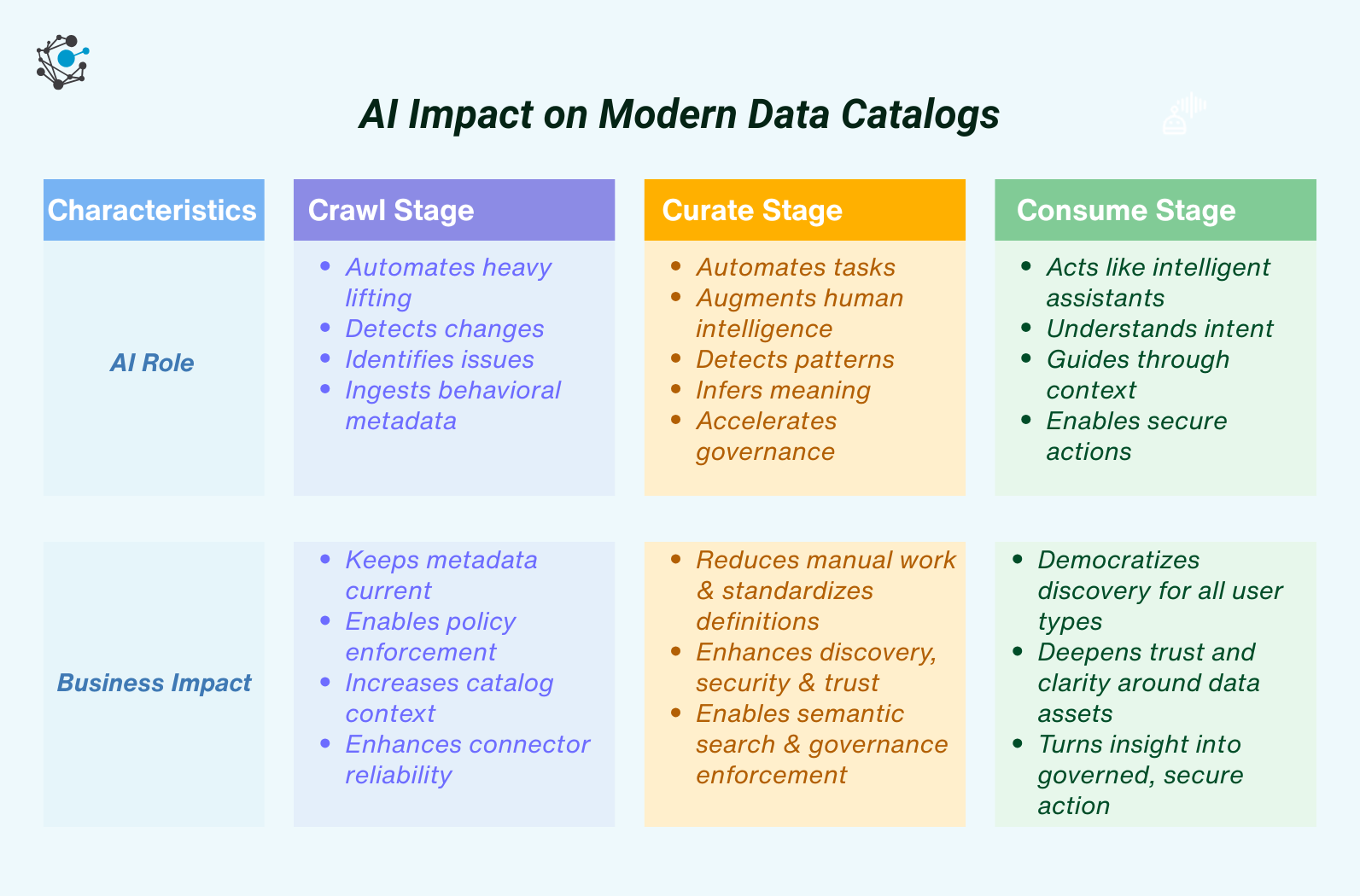
To unpack this transformation, we’ll use a three-stage lifecycle lens: Crawl, Curate, & Consume.
Let’s explore how AI impacts each of these stages.
How AI improves the 'crawl' stage for data catalogs
Before you can curate or consume data, you need to capture it entirely, accurately, and continuously. This is where the Crawl stage comes into play. Traditionally, it meant running static crawlers or relying on manual triggers. But in modern data environments, that simply doesn’t scale. AI changes that.
First, AI automates heavy lifting: running scheduled crawls without human intervention, detecting changes and triggering re-crawls, and troubleshooting failed connector jobs.
However, AI goes beyond automation. It makes data catalogs smarter by continuously detecting changes, identifying data source-specific issues, and ingesting both behavioral and structured metadata.
This richer foundation powers everything downstream: governance, search, policy enforcement, and analytics.
Here’s a snapshot of where AI delivers value at this stage:

These align closely with the top features of a modern data catalog, where connectivity, metadata extraction, and automation are foundational. Let’s break these down with real use cases:
1. Automated & scheduled metadata ingestion
AI orchestrates crawling dynamically, adjusting frequency based on data volatility, system load, and user activity.
For example, a Snowflake warehouse might be crawled daily, while an infrequently used SAP system is scanned weekly.
This ensures metadata stays up to date without overwhelming systems or requiring manual effort.
2. Active metadata detection
Going beyond tables and schemas, AI captures dynamic metadata: access patterns, permission changes, behavioral signals. If access to a sensitive dataset suddenly spikes, the catalog detects it, enabling proactive policy enforcement before an incident occurs.
3. Deeper, intelligent metadata extraction
AI adapts to source-specific structures. In Salesforce, for instance, it extracts record types, object-level permissions, and more, far beyond what static crawlers capture.
This deepens context and reduces the time analysts spend deciphering systems.
4. Connector intelligence & fault handling
When connectors fail (e.g., schema drift, API changes), AI detects the root cause and suggests (or applies) fixes. This enables self-healing data ingestion and maintains metadata flow with minimal human oversight.
What modern AI data catalog news and trends show for 2026
Modern enterprises increasingly demand real-time cataloging, observability, and improved data‑usage monitoring - pushing the evolution of AI-powered data catalogs beyond static metadata inventories. A recent shift shows catalogs integrating data‑observability, anomaly detection, and usage analytics to transform how organizations govern and trust their data.
According to recent data catalog news:
-
AI data catalog tools now often include automated metadata enrichment, semantic classification, anomaly detection, and usage‑pattern analytics — bringing improved visibility into data quality and health.
-
Organizations are using such catalogs to support self‑service analytics, compliance, and data observability — not just discovery and governance.
-
The rise of hybrid data ecosystems (on-premise + cloud + streaming) has increased demand for catalogs that automatically adapt and unify metadata across environments.
These trends show that “ai data catalog” is no longer a buzzword — it’s foundational for modern data architecture, especially where data volume, variety, and regulatory demands intersect.
Why AI data monitoring and cataloging improvements matter
Integrating AI‑powered cataloging with data monitoring and observability enables organizations to detect data issues proactively — such as schema changes, data drift, or unauthorized data access — and link those insights directly to metadata, lineage, and governance workflows. This elevates a catalog from a passive directory to an active guardrail for data health and compliance.
Such improvements are especially relevant for companies that handle sensitive data or operate under strict regulatory frameworks — because they permit a unified view of data assets, their usage, and their data quality over time, supporting both operational integrity and governance requirements.
Where and how to evaluate an AI‑enabled data catalog
If you’re exploring solutions (for example from OvalEdge), when you “evaluate the AI technology company OvalEdge on data cataloging,” consider the following dimensions:
-
Depth of automation: Does the catalog support automated ingestion, enrichment, and metadata updating?
-
Semantic intelligence: Does it provide classification, tagging, usage-based recommendations, semantic relationships, and search?
-
Data observability integration: Does it support monitoring usage, detecting anomalies, tracking drift, and combining that with metadata for active governance?
-
Scalability across hybrid environments: Can it handle on-prem, cloud, data lakes, streaming sources and merge metadata seamlessly?
-
Governance, compliance, and collaboration: Does it embed governance workflows, access controls, and allow collaboration across technical and business teams?
With OvalEdge’s AI-based catalog, you get those capabilities — delivering comprehensive metadata management, rapid onboarding of data assets, and AI‑ready data discovery across environments.
What’s next - the evolving landscape of AI-powered data catalogs
Emerging research and solutions — including academic prototypes — indicate the next generation of AI data catalogs will incorporate LLM-driven semantic search, hierarchical global catalogs, natural-language queries, and intelligent suggestion of relevant datasets. For example, recent work like LEDD (Large Language Model‑Empowered Data Discovery in Data Lakes) demonstrates how large‑scale data lakes can be cataloged and searched semantically.
This implies that in the near future, “cataloging” will not just mean listing metadata — but providing contextual, intelligent data discovery, dynamic schema linking, and automatic dataset recommendations based on user intent.
Organizations adopting AI-enabled catalogs today will find themselves better positioned for AI, ML, and data‑driven applications — because the catalog becomes not just a resource, but an active component of data infrastructure and data intelligence.
How AI improves the ‘curate’ stage for data catalogs
If Crawl gathers signals, Curate turns them into usable knowledge, enriching, organizing, and making it trustworthy. Traditionally, this involved heavy manual work, including documenting lineage, tagging fields, and assigning owners.
AI not only automates these tasks but also augments human intelligence, detecting patterns, inferring meaning, and accelerating governance.
Related post: Data catalogs and data governance: Explained
Here’s a snapshot of where AI delivers value at this stage:

1. Auto-lineage generation (technical & business)
AI parses SQL, pipeline configs, and dashboard metadata to generate end-to-end lineage, connecting KPIs to source systems. This demystifies data transformations and reduces documentation debt for engineering teams.
2. Glossary term recommendations
When defining a term like “LTV,” the system surfaces similar existing terms, recommends standard descriptions, and auto-tags the domain. That ensures a consistent, high-quality vocabulary across teams.
3. Similarity & classification
AI detects semantic duplicates (e.g., “customer_email” and “email_id”) and sensitive fields, such as PII, not only in names but also in structure and usage. This helps automate tagging, masking, and deduplication.
4. Automated steward assignment
Using metadata interactions, edit history, and query logs, AI suggests likely owners or domain experts, removing the need for top-down assignments.
5. Data quality rule suggestions
AI recommends null checks, uniqueness rules, and drift thresholds inferred from actual data patterns. This turns observability into action, helping teams catch issues early.
6. Domain & relationship inference
The system links related assets across tools and infers domains, such as Finance or Marketing, from usage and structure. This powers semantic filters, improves search, and streamlines policy scoping.
How AI improves the ‘consume’ stage for data catalogs
The final data journey stage is where knowledge meets utility. Data users (analysts, stewards), and business users interact with the catalog to search, understand, and take action.
Traditionally, this was limited to keyword search or static views. Now, AI enables catalogs to behave like intelligent assistants, understanding intent, guiding through context, and facilitating secure actions.
Here’s a snapshot of how AI transforms the Consume stage:

Search: From keywords to context
AI enables conversational, context-aware search. Ask, “Show me customer data used in Q1 dashboards,” and get precise results powered by glossary terms, metadata, and usage. Filters adapt by role: marketers see domain/popularity filters, engineers see system-level details.
AI guides users to the most relevant and trusted data, empowering all personas and enhancing data literacy.
Understand: Simplified, smart metadata
Metadata views adapt by persona: business users receive definitions and owners, while developers view the schema and lineage. Missing context triggers smart prompts (e.g., “What does LTV mean here?”), routed to the right steward to keep curation collaborative. Lineage views are dynamic, showing only paths relevant to the user’s query.
Act: From insight to execution
Users take action directly in the catalog. If access is restricted, AI suggests the correct owner and automatically fills in the request.
Live integrations enable users to query data naturally (“How many customers churned last month?”) without requiring SQL. Governance is embedded, AI recommends masking policies and flags missing access controls, ensuring safe and seamless data use.
Real-world impact
Organizations using AI-powered catalogs report faster time to insight, improved data trust, reduced compliance risk, and higher user engagement. By automating manual tasks and personalizing experiences, AI enables teams to focus on strategic data utilization rather than tedious upkeep.
Conclusion: The future is AI-native cataloging
While many catalogs today offer AI-powered features like search or glossary suggestions, true transformation occurs only when AI is deeply embedded across the entire metadata lifecycle, from ingestion to insight.
At Crawl, AI automates and enriches metadata collection, inferring meaning from usage and context beyond technical scans. In Curate, it accelerates classification, identifies stewards, and turns stewardship into an intelligent, shared workflow. In Consume, AI redefines discovery and action, empowering natural language search, dynamic lineage, and role-aware insights that guide users, not just inform them.
This shift transforms catalogs from static inventories into adaptive intelligence systems that continuously learn from usage, improve through interaction, and bridge the gap between data and decision.
In a world where data volume and velocity keep accelerating, AI-native catalogs aren’t a luxury. They’re a necessity. Organizations embracing them deliver trustworthy, contextual, and immediately usable data to every user, at every moment. Not just faster, but smarter.
FAQ's
Q1: What is the difference between a traditional data catalog and an AI data catalog?
An AI data catalog automates metadata ingestion, enrichment, classification, and semantic relationships - whereas traditional catalogs mainly store static metadata and require manual upkeep.
Q2: Can AI-powered data catalogs support data monitoring and observability?
Yes - modern AI catalogs increasingly combine cataloging with data monitoring, enabling anomaly detection, usage‑pattern tracking, and data quality alerts tied to metadata.
Q3: Why is semantic intelligence important in a data catalog?
Semantic intelligence enables classification, auto‑tagging, natural language search, and automatic suggestions — making data discovery easier and more intuitive across large, complex datasets.
Q4: What should I check when I evaluate a vendor like OvalEdge for cataloging?
Check for automated ingestion/enrichment, semantic tagging, observability features, hybrid environment support, governance workflows, and ease of collaboration across teams.
Q5: Will AI data catalogs help for future AI/ML projects?
Absolutely - they help surface high‑quality, well‑documented, and trustworthy datasets with lineage, context, and metadata — ideal for training, analysis, and model building.
Deep-dive whitepapers on modern data governance and agentic analytics

OvalEdge Recognized as a Leader in Data Governance Solutions

.png?width=1081&height=173&name=Forrester%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.