
.png)
Data discovery replaces fragmented visibility with a structured, repeatable workflow that transforms scattered data into governed, analysis-ready assets. By defining scope, inventorying sources, validating access, assessing quality, classifying, preparing, analyzing, and documenting data, organizations shift from reactive audits to proactive governance. Clear ownership and continuous documentation ensure sustainable visibility, stronger compliance, and more reliable analytics outcomes.
Your teams know the data exists, but no one has a clear, documented view of where it lives, who owns it, or whether it meets quality standards. Data spreads across cloud platforms, SaaS tools, databases, and shared drives faster than teams can track it.
Data discovery steps bring structure to that chaos. They define a repeatable data discovery process that helps organizations locate, evaluate, classify, prepare, and document their data assets. Instead of reacting to audits or analytics failures, teams follow a clear workflow that builds visibility and governance from the start.
In this guide, we'll walk through how data discovery works, the practical steps in data discovery, and how organizations operationalize a consistent data discovery workflow. You'll also learn common execution challenges and best practices to run discovery effectively across teams and systems.
What are the data discovery steps?
Data discovery steps define a structured workflow for moving from fragmented data visibility to governed, analysis-ready assets.
Instead of jumping straight into dashboards or audits, teams follow a coordinated sequence: define scope, inventory systems, assess quality, classify data, prepare it for use, and document findings for long-term governance.
The goal is not exploration for its own sake. It is building repeatable visibility that supports data quality, analytics, compliance, and operational reliability.
Organizations rarely start discovery without a trigger. Common drivers include:
-
Compliance audit preparation
-
Cloud migration initiatives
-
New analytics programs
-
Data governance launches
-
Security risk assessments
|
Here’s a fact: These triggers are also why discovery is moving out of the ‘IT side project’ bucket. In 2024, 83.2% of organizations reported appointing a CDO or CDAO, which reflects how seriously leaders now treat visibility, ownership, and governance. |
8 data discovery steps to follow
Discovery brings structure to these moments of urgency. Instead of reacting system by system, teams follow a coordinated data discovery workflow that builds visibility, accountability, and context.
What once felt chaotic becomes manageable. Data stops being scattered files and disconnected dashboards and starts becoming a documented, governed asset base that the business can confidently rely on.
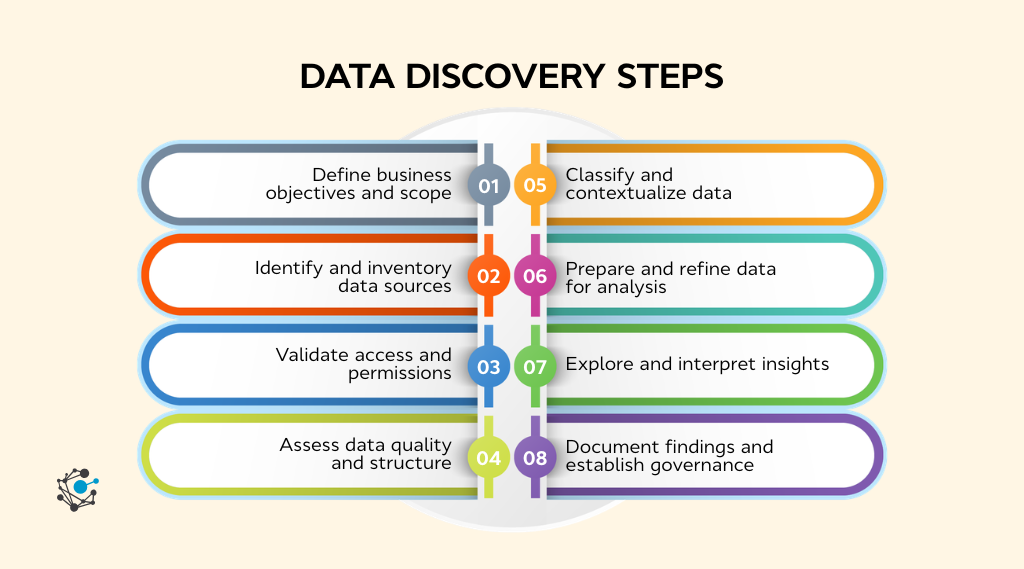
Step 1: Define business objectives and scope
The first step in data discovery is alignment. Teams clarify why discovery is happening and what success looks like.
This includes identifying stakeholders, regulatory requirements, and measurable outcomes. A compliance-led discovery will focus on sensitive data and reporting controls. An analytics-led discovery will focus on quality, completeness, and usability.
Without a clear scope, discovery expands endlessly. Defined objectives keep the data discovery process disciplined and efficient.
Step 2: Identify and inventory data sources
Once goals are clear, teams create a data inventory. This step focuses on visibility, not automation. Organizations document structured, semi-structured, and unstructured sources, including:
-
Operational databases
-
SaaS platforms
-
Cloud storage
-
Data lakes
-
Department-level spreadsheets
By documenting ownership, system location, and general purpose, teams lay the foundation for a coordinated data discovery workflow. Visibility reduces blind spots and prevents redundant work across departments.
Step 3: Validate access and permissions
Discovery does not require centralizing every dataset into one platform. It requires secure and appropriate access. Teams confirm connectivity, define permissions, and ensure that authorized users can retrieve the datasets required for evaluation and analysis.
In distributed or federated environments, this step becomes especially important. Accessibility must support collaboration without compromising governance.
When access controls are clearly defined, data preparation and data analysis can move forward without bypassing compliance standards or creating shadow processes. Secure access keeps the data discovery process practical and aligned with existing systems.
Step 4: Assess data quality and structure
With access in place, attention turns to data quality. This is where the data discovery process shifts from inventory to evaluation. Teams examine datasets for missing values, duplicate records, inconsistent formats, and schema misalignment. They assess whether the data is complete enough to support its intended use case.
Poor quality data undermines analytics, reporting, and governance efforts. Structured quality assessment at this stage prevents costly rework later in the workflow. Instead of discovering issues during dashboard creation or executive reporting, teams address them early in the data discovery steps.
By validating structure and consistency before moving into deeper analysis, organizations ensure that the rest of the workflow builds on reliable inputs rather than unstable foundations.
Step 5: Classify and contextualize data
At this stage, teams focus on organizing information in a way that supports governance and usability. That typically involves:
-
Identifying regulated or sensitive data
-
Applying business-friendly labels that reflect purpose and usage, and regulatory sensitivity
-
Assigning clear ownership and stewardship
-
Aligning datasets with specific business use cases
Classification strengthens metadata management and makes future access decisions far easier. When teams understand whether a dataset contains customer information, financial records, or operational metrics, they can apply the right controls without guesswork.
|
Stat: This governance angle is also becoming a leadership priority, not just a best practice. Deloitte’s Chief Data Officer Survey found data governance was the top priority for the year ahead at 51%, which aligns with why classification and context belong in the core workflow. |
This is also where structured documentation platforms such as OvalEdge play a meaningful role. By centralizing metadata, documenting ownership, and supporting organized data cataloging, teams build accountability into the data discovery workflow without creating unnecessary complexity.
Step 6: Prepare and refine data for analysis
Data preparation ensures that what has been discovered can actually support reporting, dashboards, and analytics. Teams clean inconsistent records, standardize formats, and resolve transformation gaps that may prevent reliable analysis.
This stage often surfaces small inconsistencies that could create major issues later, such as mismatched date formats or inconsistent naming conventions across systems.
Data preparation acts as the bridge between discovery and data visualization. It transforms inventoried and classified assets into datasets that analysts can confidently work with. When this step is rushed or skipped, insights become unreliable and decision-making suffers.
Step 7: Explore and interpret insights
Discovery delivers value when teams begin exploring and interpreting what the data reveals. At this stage, collaboration becomes critical. Teams typically:
-
Use dashboards and visualization tools to surface patterns
-
Compare findings against original business objectives
-
Validate assumptions with cross-functional stakeholders
-
Identify gaps that require further refinement
Data analysis at this point transforms documented and prepared datasets into actionable insights. Analysts may uncover trends that influence strategy, operational improvements, or compliance adjustments. Business teams contribute context that technical teams may not immediately see.
When exploration happens in isolation, insights can remain siloed. When teams collaborate, discovery becomes a shared capability rather than a technical exercise.
Step 8: Document findings and establish governance
The final step completes the structured sequence and ensures that the effort does not disappear after the initial initiative.
Teams formally record metadata, confirm stewardship responsibilities, and maintain documentation for audit readiness and future reuse. They capture context and maintain light lineage references to track how data moves across systems.
This documentation feeds directly into data catalogs, governance workflows, and access controls. When structured properly, it prevents future rediscovery cycles and reduces dependency on institutional memory. Platforms like OvalEdge help operationalize this documentation by centralizing metadata and ownership assignments so that discovery outputs remain accessible long after the project ends.
At this stage, governance stops being an abstract concept. It becomes embedded in daily operations. The data discovery steps come full circle, transforming scattered assets into a documented, governed, and reusable foundation for analytics and decision-making.
How teams operationalize the data discovery workflow
A well-designed data discovery workflow only works when the right people carry it forward. Discovery is not owned by one department. It requires coordination across technical, governance, and business teams to move from visibility to usable insight.
Operationalizing the data discovery workflow is complicated by the reality that most environments are not purely cloud or purely on-prem.
In fact, cloud analytics and data management deployments account for about 36% of all projects, which means many teams are working in hybrid environments where visibility, connectivity, and access controls must be orchestrated across diverse systems.
In practice, successful organizations define responsibilities clearly so that each stage of the data discovery process has an accountable owner. While titles may vary, the roles often look like this:
-
Data engineers manage connectivity, validate access, and assess structural quality so that datasets are technically usable.
-
Data stewards focus on classification, metadata accuracy, and documentation standards to ensure consistency and accountability.
-
Compliance and risk teams verify regulatory alignment, confirm sensitive data handling, and flag exposure risks early.
-
Business stakeholders validate context, confirm relevance to use cases, and ensure discovery aligns with operational goals.
This cross-functional structure prevents discovery from becoming either too technical or too theoretical. Clear ownership checkpoints reduce duplication and confusion.
When disagreements arise over classification or access, defined escalation paths resolve them quickly instead of stalling progress. Structured collaboration keeps the data discovery workflow aligned with both technical realities and business priorities.
Discovery becomes sustainable when responsibility is explicit and documented rather than assumed. When roles are vague, workflows slow down, and when accountability is clear, discovery moves forward with confidence.
However, even well-coordinated teams encounter friction once execution begins. Process gaps, unclear ownership, and inconsistent documentation often surface at this stage, which is where disciplined workflows become even more important.
Common challenges in executing data discovery steps
Even when organizations follow defined data discovery steps, execution rarely runs the first time perfectly. The structure may be sound, but day-to-day realities introduce friction that slows progress and weakens outcomes.
Several issues tend to surface repeatedly:
-
Lack of clear ownership slows decisions and creates hesitation around classification or access approvals. When no one feels accountable, discovery stalls.
-
Undefined objectives cause scope creep. Teams continue cataloging and assessing data without knowing what “done” actually looks like.
-
Fragmented documentation limits reuse. If findings sit in disconnected files or informal notes, future teams must start from scratch.
-
Over-reliance on manual tracking increases the likelihood of errors, outdated records, and inconsistent metadata.
-
Resistance to cross-team collaboration keeps visibility siloed, which undermines the very purpose of a coordinated data discovery workflow.
These obstacles are common, but they are manageable. When the steps in data discovery are consistently applied, friction decreases, and momentum builds.
|
Expert insight: These issues show up across industries, even in regulated reporting programs. Deloitte found 57% cited data quality as the top challenge, and 81% cited documentation and sign-off as a top challenge, which maps directly to why ownership, documentation, and governance break down in practice. |
The real question is whether your organization has guardrails strong enough to prevent those challenges from derailing the entire workflow. Sustainable discovery depends on reinforcing the right habits, which leads directly to the best practices that keep the process efficient and repeatable.
Best practices for running an effective data discovery workflow
Running discovery once is easy. Running it consistently, across teams and over time, is where real discipline shows up.
Organizations that treat the data discovery process as a structured operational habit rather than a one-off initiative see stronger governance, better analytics reliability, and far fewer last-minute compliance scrambles.
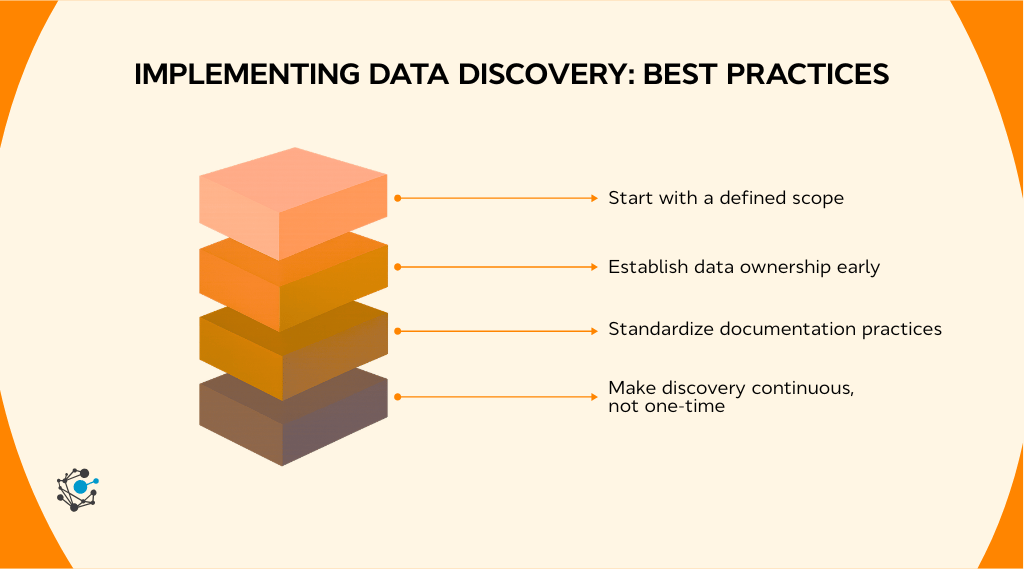
Start with a defined scope
Every effective discovery effort begins with a clearly framed question.
-
What problem are you solving?
-
What systems matter for this initiative?
-
What does success look like?
When the scope is focused, teams align faster and move with purpose. A tightly defined objective prevents endless cataloging and keeps the data discovery workflow practical. It also makes outcomes measurable, which builds confidence in the process.
Establish data ownership early
Ownership removes ambiguity. When someone is explicitly responsible for a dataset, classification decisions move faster, documentation stays current, and accountability becomes embedded in daily operations.
Early ownership assignments also strengthen metadata management and long-term stewardship. Instead of discovery outputs fading over time, accountable owners maintain relevance and accuracy as systems evolve.
Standardize documentation practices
Consistency matters more than complexity. When teams use standardized templates and shared documentation formats, clarity improves across departments.
Structured documentation supports stronger data cataloging and governance alignment. It reduces confusion when teams revisit discovery outputs months later. It also ensures that insights and context remain usable beyond the original initiative.
Make discovery continuous, not one-time
Data ecosystems do not stand still. New systems are added, regulations shift, and analytics priorities change. Treating discovery as a one-time event guarantees that documentation becomes outdated.
Organizations that embrace iterative data exploration build stronger research data management habits and reduce reactive firefighting. Continuous discovery keeps metadata current, ownership visible, and data quality aligned with business needs.
When these best practices become routine, discovery stops feeling like a disruptive project and starts functioning as an integrated operational discipline. At that point, the workflow no longer depends on urgency or audits to drive action. It becomes part of how the organization understands and governs its data, which is exactly where it belongs.
Conclusion
When data discovery is informal, teams react. When it is structured, teams lead. The gap between those two states shows up in missed insights, compliance risk, and wasted effort.
OvalEdge helps close that gap. By centralizing metadata, clarifying ownership, and embedding governance into daily workflows, OvalEdge turns scattered discovery efforts into a repeatable, accountable system. Instead of chasing spreadsheets and disconnected documentation, your teams gain a single, structured view of trusted data.
If you are ready to replace reactive discovery with a disciplined, governed workflow, schedule a conversation with OvalEdge and see how a structured data discovery framework can bring clarity and confidence to your data environment.
FAQs
1. What is the difference between data discovery and data analysis?
Data discovery focuses on locating, organizing, and evaluating datasets before analysis begins. Data analysis interprets prepared data to answer business questions. Discovery builds the foundation, while analysis extracts insights from that structured and validated data.
2. How long does a typical data discovery process take?
The timeline depends on scope, data volume, and organizational complexity. Small initiatives may take weeks, while enterprise-wide discovery efforts can extend over several months, especially when documentation, ownership alignment, and governance updates are involved.
3. What tools are commonly used for data discovery?
Organizations use data catalogs, metadata management platforms, governance tools, and visualization software to support discovery. These tools help inventory assets, document ownership, manage access controls, and enable structured exploration across distributed data environments.
4. Who should be responsible for managing data discovery initiatives?
Data discovery typically involves data engineers, stewards, compliance teams, and business stakeholders. Responsibility should be clearly defined, with accountability for documentation, quality assessment, classification, and ongoing oversight assigned to specific roles.
5. Can data discovery support cloud migration projects?
Yes. Data discovery helps organizations understand existing systems, dependencies, and sensitive information before migration. This visibility reduces migration risk, prevents data loss, and ensures governance controls remain intact across cloud environments.
6. How often should organizations conduct data discovery?
Data discovery should not be a one-time activity. Organizations benefit from periodic reviews or continuous discovery practices that update metadata, ownership, and documentation as systems, regulations, and business priorities evolve.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)