-1.png)
Enterprise data warehouses (EDWs) restore trust in analytics by centralizing governed, historical data into a single source of truth. While EDWs excel at consistency, compliance, and performance, they lack agility for rapid exploration. OvalEdge bridges this gap with askEdgi, enabling AI-powered, governed discovery without new pipelines, combining long-term stability with short-term analytical speed.
An enterprise data warehouse (EDW) centralizes structured, validated data from across an organization into a single source of truth for analytics and reporting. It ensures consistency, supports governance and compliance, and optimizes performance for business intelligence. Modern EDWs increasingly use cloud platforms for flexibility and scalability.
Data should make decisions easier. For many enterprises, it does the opposite.
When one dashboard shows growth, but another shows decline, leadership meetings turn into debates about whose data is “right” instead of discussions about what to do next.
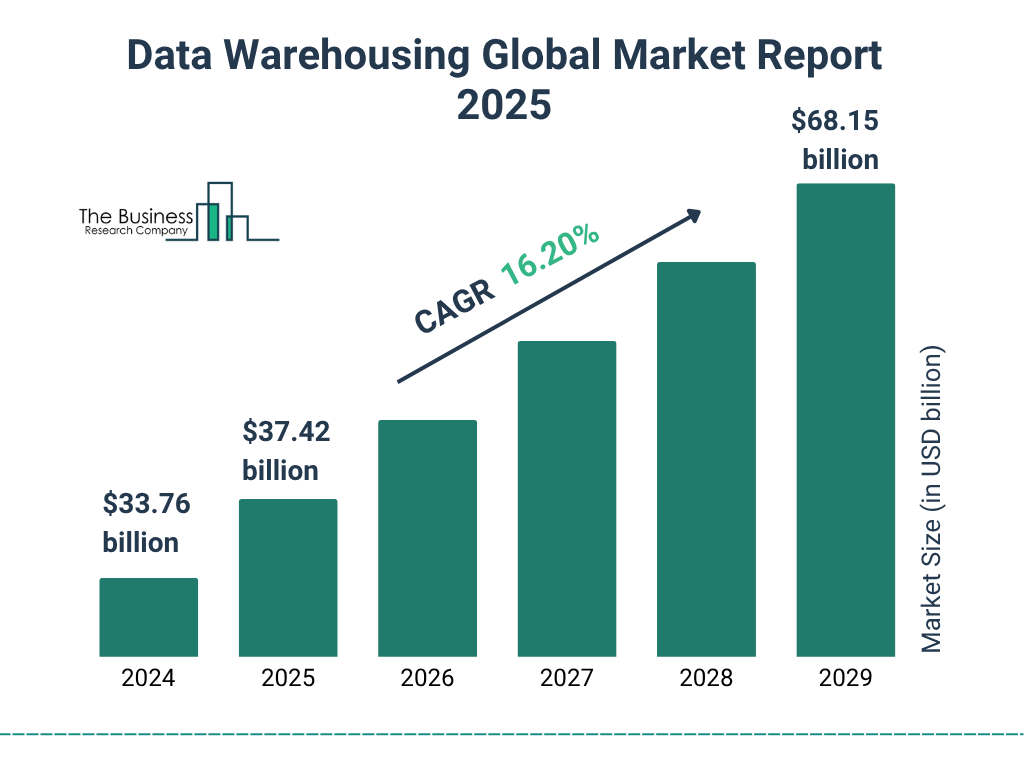
An enterprise data warehouse (EDW) brings order to this chaos. The importance of this foundation is reflected in market growth.
The global data warehousing market, valued at USD 37.42 billion in 2025, is expected to reach USD 68.15 billion in 2029, signaling sustained enterprise investment in governed analytics platforms.
It centralizes structured, validated, historical data into a single source of truth optimized for analytics, reporting, and decision-making. At the same time, modern enterprises increasingly need faster, more agile ways to explore data before committing to long-term pipelines and models.
This is where newer ideas, like a pop-up data warehouse, enter the picture. While EDWs provide stability and governance, tools such as OvalEdge’s askEdgi support rapid, AI-assisted analysis on governed data without persisting or reshaping it. Together, they address both long-term analytics and short-term discovery needs.
Key Takeaways:
1. EDW Creates a Governed Single Source of Truth for Enterprise Analytics
2. Cloud and Hybrid Architectures Are Driving Modern EDW Adoption
3. EDWs Prioritize Trust and Performance, While Lakes/Lakehouses Prioritize Flexibility
4. Strong Governance, Metadata, and Modeling Are Critical to EDW Success
5. Combining EDW Stability with AI-Driven Agility Enables Faster Insights
This guide will help you understand how enterprise data warehouses work, how they differ from other systems like data lakes and lakehouses, and how to design the right strategy for modern analytics.
What is an enterprise data warehouse (EDW)?
An enterprise data warehouse centralizes data from across an organization into a single, trusted source for analytics and reporting. It stores structured, historical data optimized for business intelligence, performance, and governance.
This architecture integrates multiple systems, enforces security and compliance, and supports scalable querying for large enterprises. Modern enterprise data warehouses increasingly use cloud platforms to improve flexibility, cost control, and performance while enabling reliable, analytics-ready insights across the business.
Why do organizations use an enterprise data warehouse?
Enterprises adopt an enterprise data warehouse because it solves multiple analytics challenges at the same time. As data volumes grow and systems multiply, organizations need a reliable way to align metrics, maintain trust, and support decision-making at scale.
At its core, an EDW creates consistency. It brings data from across departments into one governed environment, eliminating conflicting reports and duplicated logic. This foundation enables teams to focus on insights rather than data reconciliation.
Key reasons organizations rely on an EDW include:
a. A single source of truth across business domains, ensuring everyone works from the same validated metrics
b. Clean, structured historical data that supports long-term trend analysis, forecasting, and executive reporting
c. High-performance analytics optimized for complex OLAP queries used by BI tools and dashboards
d. Stronger data governance, including lineage, access control, and auditability
e. Regulatory compliance support, especially critical for industries like finance and healthcare
Governance remains a major driver for EDW adoption. Role-based access, data lineage, and auditing help organizations meet compliance requirements while maintaining trust in analytics outputs.
At the same time, not every analytics question needs permanent ingestion or modeling. This is where askEdgi complements the EDW by enabling fast, governed, AI-powered insights without creating new tables, views, or pipelines. It acts as a pop-up EDW layer for rapid discovery, while preserving the integrity and stability of the core warehouse.
|
Did you know? Gartner forecasts that 90% of organizations will adopt hybrid cloud architectures through 2027, reflecting how EDWs increasingly operate across cloud and hybrid environments rather than purely on-premise systems. |
How EDW differs from data lakes and data lakehouses?
|
Aspect |
Enterprise Data Warehouse (EDW) |
Data Lake |
Data Lakehouse |
|
Primary Purpose |
Trusted, consistent enterprise reporting |
Flexible storage for raw data exploration |
Unified platform combining lake flexibility with warehouse performance |
|
Data Type |
Structured, curated, validated data |
Raw, semi-structured, and unstructured data |
Structured + semi-structured data with governance |
|
Schema Approach |
Schema-on-write (defined before loading) |
Schema-on-read (applied at query time) |
Hybrid (supports schema enforcement with flexibility) |
|
Data Quality |
High – cleaned and modeled before use |
Varies – raw data may require cleaning |
Managed quality with ACID transactions and governance layers |
|
Governance & Compliance |
Strong governance, lineage, and access control |
Limited by default (depends on implementation) |
Built-in governance and transactional support |
|
Performance Focus |
Optimized for SQL, OLAP, and BI dashboards |
Optimized for storage scale and experimentation |
Optimized for BI, ML, and streaming workloads |
|
Best For |
Executive reporting, compliance-heavy industries, historical analysis |
Data science, experimentation, and large-scale raw data storage |
AI, real-time analytics, mixed BI + ML workloads |
|
Flexibility |
Lower (structured and predefined models) |
High (supports evolving data types) |
High with structured controls |
|
Typical Use Case |
Predictable business intelligence workloads |
Exploratory analytics and machine learning |
Hybrid analytics environments need both governance and agility |
|
When to Choose |
When trust, performance, and reporting consistency are critical |
When experimentation and large raw data storage are priorities |
When both advanced analytics and governed BI are required |
Forecasts suggest the cloud data warehouse market alone will grow by nearly $64 billion between 2024 and 2029, highlighting why many enterprises now operate hybrid analytics stacks.
|
Also read: Data Lakehouse Architecture: Unifying Analytics in 2026 |
Core architecture and components of an EDW
A well-designed enterprise data warehouse is not a single system but a set of tightly connected layers that work together to deliver trusted, high-performance analytics.
Each layer plays a distinct role, and weaknesses in any one of them tend to show up quickly, usually as slow dashboards, unreliable metrics, or frustrated users.
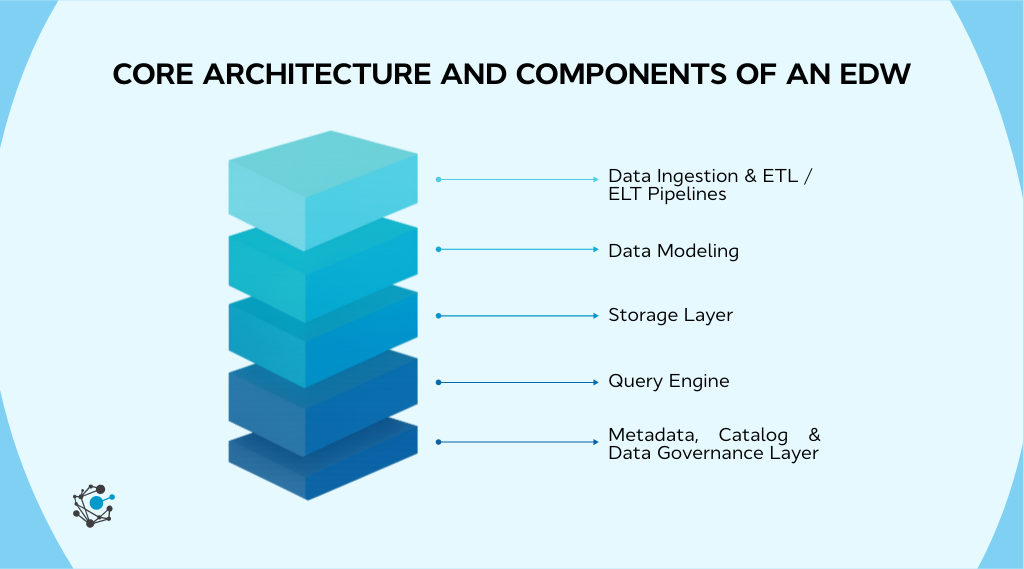
1. Data ingestion & ETL/ELT pipelines
Everything starts with ingestion. EDWs pull data from a wide range of sources, including ERP systems, CRMs, SaaS applications, operational databases, and event logs.
The goal is simple: bring data into the warehouse in a reliable, repeatable way.
Traditionally, this process followed ETL, transforming data before loading it into the warehouse.
Cloud-based EDWs increasingly favor ELT, where raw data is loaded first and transformed inside the warehouse.
This shift improves flexibility and scalability, but it also raises the bar for governance and data quality.
Pipeline work also eats up more time than most teams expect.
In a 2024 TDWI survey, 50% of organizations said project teams spend over 61% of their time on data integration, pipeline development, and preparation, which explains why EDW programs often slow down without strong automation and standards.
2. Data modeling
Once data is ingested, modeling gives it structure and meaning. This is where raw tables turn into analytics-ready assets.
Star schemas simplify querying by organizing data around fact tables and dimensions, making dashboards faster and easier to understand.
Snowflake schemas further normalize dimensions to reduce redundancy and improve storage efficiency.
Data marts tailor models to specific business domains like finance, sales, or marketing.
Good modeling improves query performance, reduces BI complexity, and reinforces governance.
Poor modeling does the opposite, slowing analytics and forcing teams to rebuild logic in every dashboard.
3. Storage layer
EDWs store data differently from operational systems. Most use columnar storage, which allows analytical queries to scan only the columns they need.
This dramatically improves performance while keeping storage costs under control.
Compression, partitioning, and clustering further optimize access to large datasets.
Tiered storage strategies separate frequently queried “hot” data from older historical data, making it possible to retain years of history without sacrificing speed or budget.
This design makes EDWs ideal for long-term trend analysis and historical reporting.
4. Query engine
The query engine is where the warehouse earns its reputation.
Modern EDWs rely on distributed, massively parallel processing engines built specifically for OLAP workloads.
These engines handle complex joins, aggregations, and high user concurrency without grinding to a halt.
Cloud platforms separate compute from storage, allowing organizations to scale performance independently from data volume.
This flexibility is especially important for enterprises with unpredictable analytics demand.
5. Metadata, catalog & data governance layer
Governance is what turns a data warehouse into a trusted enterprise asset. Metadata catalogs capture lineage, ownership, definitions, and usage context.
Role-based access controls protect sensitive data, while auditing supports regulatory and internal compliance.
This governance layer is also where OvalEdge adds unique value. By leveraging governed metadata, askEdgi enables AI-assisted analysis without reshaping or persisting data.
It creates temporary semantic views that deliver EDW-like analytical power only for the duration of a question, reducing architectural overhead while preserving trust and control.
Benefits of Enterprise Data Warehouse
1. Single Source of Truth
An EDW centralizes validated data from across departments into one consistent environment. This eliminates conflicting reports and duplicated logic, ensuring that everyone works from the same trusted metrics for accurate and aligned decision-making.
2. Strong Data Governance
Enterprise data warehouses enforce role-based access, data lineage, auditing, and compliance controls. This strengthens data security, supports regulatory requirements, and builds organizational trust in analytics outputs.
3. High-Performance Analytics
EDWs are optimized for complex SQL and OLAP queries. Columnar storage, indexing, and distributed processing enable fast dashboard performance and support large-scale business intelligence workloads.
4. Historical Data for Strategic Insights
EDWs store structured, long-term historical data. This makes trend analysis, forecasting, and executive reporting more reliable, supporting better strategic planning and long-term business decisions.
5. Scalable Cloud Flexibility
Modern cloud-based EDWs separate compute and storage, allowing organizations to scale resources as needed. This improves cost efficiency, performance control, and adaptability to changing analytics demands.
Types of Enterprise Data Warehouse
1. On-Premise EDW
Traditional data warehouses are hosted within an organization’s own data centers. They offer full control over infrastructure, security, and compliance, but require high upfront investment, ongoing maintenance, and dedicated IT resources.
2. Cloud-Based EDW
Deployed on cloud platforms like Snowflake, BigQuery, or Redshift. They provide scalability, flexible pricing, and a separate compute-storage architecture, making them ideal for modern enterprises seeking agility and cost efficiency.
3. Hybrid EDW
Combines on-premise and cloud environments. Organizations keep sensitive or legacy workloads on-premise while leveraging cloud scalability for analytics. This approach supports gradual modernization without fully migrating existing systems.
4. Logical (Virtual) EDW
Does not physically centralize all data. Instead, it uses data virtualization to query data across multiple systems in real time, creating a unified analytical view without heavy data movement.
5. Real-Time (Active) EDW
Designed to ingest and process data continuously. It supports near real-time reporting and operational analytics, enabling faster decision-making for industries like e-commerce, finance, and logistics.
Key considerations before implementing an EDW
Before committing to an enterprise data warehouse strategy, it’s important to step back and evaluate a few foundational factors.
EDWs are long-term investments, and early decisions around scope, architecture, and governance often determine whether the platform accelerates analytics or becomes a bottleneck.
Several considerations consistently shape successful EDW implementations:
a. Data volume, growth, and storage costs: Historical data grows faster than expected. Understanding current volumes and future growth helps guide storage architecture, retention policies, and cost optimization strategies.
b. Schema design and modeling strategy: Data models directly impact performance and usability. Well-designed schemas improve BI adoption and query speed, while overly complex models increase maintenance and confusion.
c. ETL and ELT integration complexity: More pipelines mean more engineering effort. Latency expectations, transformation logic, and monitoring requirements should align with real business needs, not assumed ones.
d. Governance, security, and access control requirements: Industries with regulatory obligations must plan for lineage, auditing, role-based access, and data privacy from the start. Strong governance builds trust and prevents rework later.
e. Deployment model: cloud, on-premise, or hybrid: Each option comes with trade-offs in flexibility, cost, scalability, and operational control. The right choice depends on data sensitivity, infrastructure maturity, and modernization goals.
Taken together, these factors help organizations avoid common pitfalls such as overengineering, uncontrolled costs, and low analytics adoption.
A thoughtful evaluation upfront sets the foundation for an EDW that delivers reliable insights and scales with the business.
How to choose the right EDW strategy for your organization?
Choosing an enterprise data warehouse strategy is less about picking a single technology and more about aligning data capabilities with how your organization actually makes decisions.
A well-chosen EDW supports current analytics needs while remaining flexible enough to evolve as data volumes, teams, and use cases grow.
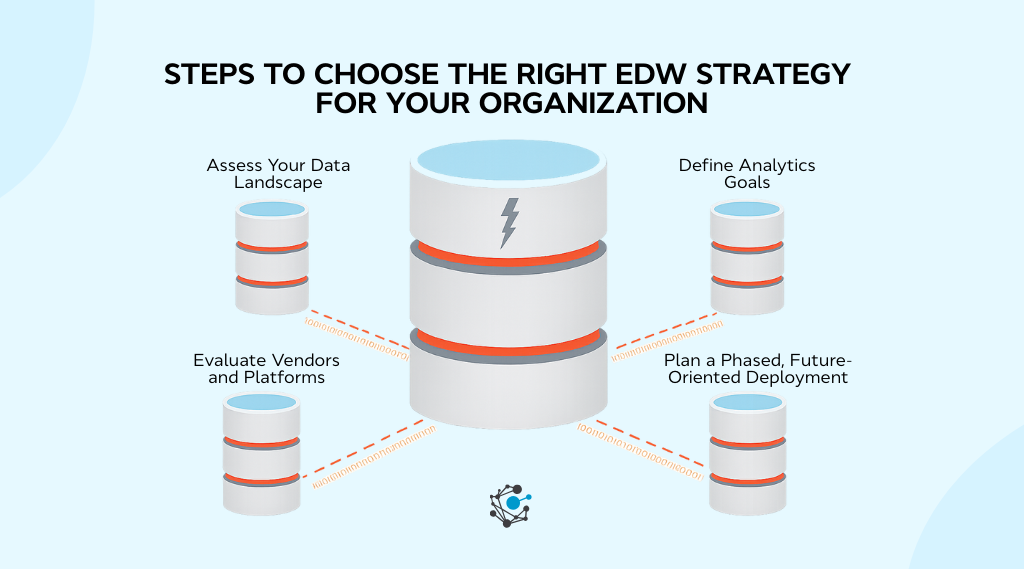
1. Assess your data landscape
Start with a clear inventory of your data sources, volumes, and growth patterns. Identify which systems produce structured data and which generate semi-structured or event-based data.
Understanding latency requirements and data quality gaps early prevents unnecessary complexity later.
Without this clarity, EDW initiatives often overbuild for edge cases or underdeliver on core business needs.
2. Define analytics goals
Next, define what success looks like for analytics. Determine whether the EDW primarily supports dashboards, forecasting, compliance reporting, or executive decision-making.
Align use cases with business KPIs and decision workflows rather than abstract technical goals.
It’s also important to consider how downstream AI or machine learning initiatives will consume warehouse data, even if those efforts come later.
3. Evaluate vendors and platforms
When comparing EDW platforms, focus on fit rather than popularity. Evaluate cloud, on-premise, and hybrid options based on scalability, performance, cost structure, and governance capabilities.
Review how well each platform integrates with existing BI tools, data pipelines, and metadata systems.
A platform that aligns with your architecture and operating model will deliver more value than one chosen purely for market visibility.
4. Plan a phased, future-oriented deployment
Successful EDW programs rarely launch all at once. Start with high-impact business domains, then expand in phases as adoption grows. Design the architecture to support modular expansion, new data sources, and future cloud or hybrid evolution.
Building with flexibility in mind reduces risk and keeps the warehouse aligned with changing business priorities.
These steps help organizations avoid common missteps such as overengineering, vendor lock-in, and low adoption. A thoughtful EDW strategy creates a foundation that delivers reliable insights today while remaining flexible enough to support future growth and change.
|
Also read: Complete Guide to Data Warehouse Migration in 2026 |
Key Challenges of Enterprise Data Warehouses
1. Data Integration Complexity
Integrating data from multiple systems, formats, and departments requires complex ETL/ELT pipelines. As sources grow, managing transformations, dependencies, and data consistency becomes time-consuming and resource-intensive, often slowing analytics delivery.
2. High Implementation and Maintenance Costs
EDWs require significant investment in infrastructure, tools, skilled personnel, and ongoing optimization. Cloud scaling, compute usage, and storage growth can further increase operational costs if not carefully managed.
3. Scalability and Performance Bottlenecks
As data volumes and user concurrency increase, query performance may degrade. Poor workload management, inefficient modeling, or improper resource allocation can create bottlenecks that impact dashboards and reporting.
4. Governance and Compliance Complexity
Maintaining data lineage, access controls, auditing, and regulatory compliance across growing datasets is challenging. Weak governance can reduce trust in analytics and expose organizations to regulatory risks.
5. Limited Agility for Rapid Analytics
Traditional EDWs prioritize structure and stability, which can slow experimentation. Adding new data sources or modifying schemas often requires significant engineering effort, reducing responsiveness to evolving business questions.
Conclusion
Enterprise analytics doesn’t fail because organizations lack data. It fails when insights take too long, governance becomes a blocker, or teams are forced to choose between speed and trust. The enterprise data warehouse solves the trust problem, but on its own, it often struggles with agility.
That gap is where OvalEdge’s askEdgi delivers real value. By acting as a pop-up data warehouse, askEdgi enables instant, governed analysis on existing data, without new pipelines, permanent models, or architectural sprawl.
Teams get answers faster while keeping the enterprise data foundation clean and controlled. For organizations looking to move beyond slow, rigid analytics cycles, this combination changes how insights are delivered.
Book a free demo today and explore how OvalEdge helps enterprises turn governed data into faster, more confident decisions without rebuilding their data stack.
FAQs
1. How do organizations decide whether to build an EDW or expand an existing one?
Teams evaluate data growth, reporting demand, and governance needs. If current systems limit scalability or accuracy, expanding or modernizing an EDW becomes the most sustainable long-term path for analytics maturity.
2. Can an enterprise run advanced analytics without a traditional EDW?
Yes. Organizations can use cloud warehouses, lakehouses, or federated query engines. However, EDWs provide consistency and reliability that many advanced analytics workflows still depend on for trusted decision-making.
3. What factors influence EDW performance in large enterprises?
Concurrency handling, query optimization, workload isolation, storage formats, and compute scaling determine performance. Proper resource configuration and workload management are essential for predictable BI and analytics at scale.
4. How does AI assist teams working with EDW environments?
AI tools can explore datasets, interpret metadata, automate documentation, and accelerate discovery, reducing reliance on manual SQL or data modeling while guiding users toward accurate, governed insights.
5. What challenges arise when integrating EDWs with modern cloud ecosystems?
Enterprises often face connectivity limitations, schema drift, inconsistent refresh cycles, and governance gaps. Successful integration requires flexible pipelines, strong metadata management, and architectural alignment across cloud services.
6. How do organizations control EDW costs as data grows?
Teams use tiered storage, workload separation, query monitoring, and lifecycle policies. Right-sizing compute and prioritizing high-value analytics help control spend while maintaining performance.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)