.png)
What happens when the data you depend on isn’t accurate, consistent, or complete?
-
Business logic fails
-
Forecasts shift without explanation
-
Customer records don’t match across systems, and
-
Teams start validating every report manually because no one fully trusts the numbers anymore.
This isn’t a rare edge case. It’s becoming the norm.
According to the Annual State of Data Quality Survey by Monte Carlo, 2023, data downtime has nearly doubled year over year, driven by a 166% increase in time to resolution for data quality issues, meaning organizations are spending more time finding and fixing bad data than using it.
The consequences extend far beyond operational inefficiency. According to Forrester’s 2023 “Data Culture & Literacy” survey, over one-quarter of global data and analytics practitioners estimate their organizations lose more than $5 million per year due to poor data quality, and 7% report losses exceeding $25 million per year.
If the cost of bad data is this high, preventing it becomes non-negotiable.
In this blog, we’ll break down what data quality testing really means, how it works in modern data environments, and how organizations can move from reactive firefighting to proactive, automated data reliability.
What is data quality testing?
Data quality testing ensures that data is accurate, reliable, and ready for use in decision-making processes. This testing involves validating the integrity, consistency, and completeness of data across multiple stages, from ingestion to post-load verification.
By applying systematic checks and automated tools, businesses can prevent errors and inconsistencies that could impact analytics, operational processes, or compliance.
The goal is to ensure that data remains error-free, compliant with standards, and aligned with business objectives, ultimately enabling informed, data-driven decisions.
When and where to test data quality in pipelines
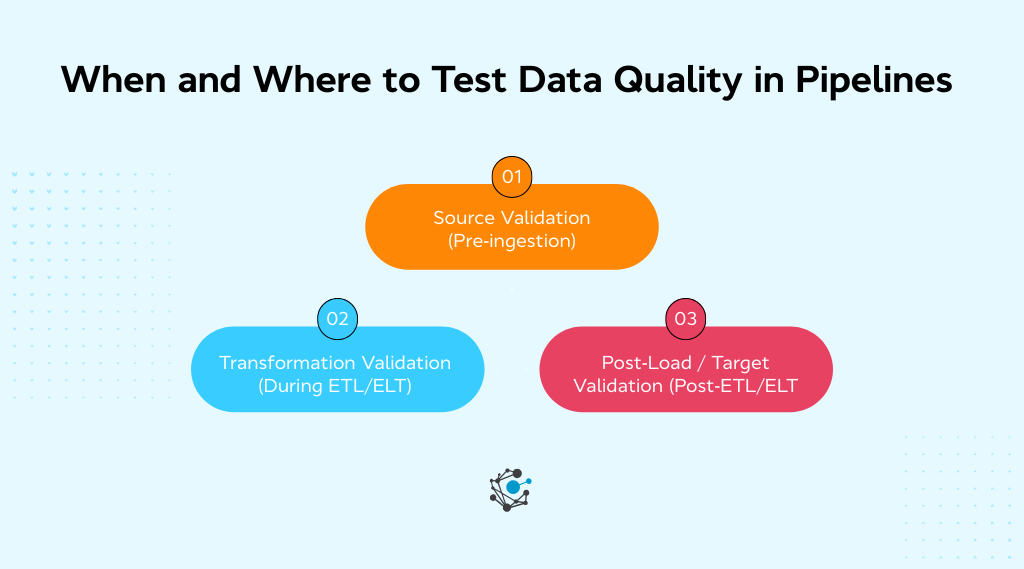
Detecting data quality issues early is critical to preventing costly mistakes or misinformed decisions downstream. Data quality testing needs to be applied at different stages throughout the data pipeline.
By addressing quality at key points, from ingestion through transformation to final loading, businesses can catch errors early, ensure compliance, and maintain confidence in the data.
There are three major stages where data quality testing should be applied
-
Source validation
-
Transformation validation, and
-
Post-load validation.
Source validation (pre-ingestion)
Source validation is the first line of defense in the data pipeline. This occurs before any data enters your processing or storage systems. At this stage, raw data is typically sourced from databases, APIs, external files, or third-party services.
Ensuring the quality of this incoming data is crucial because any errors or inconsistencies at this stage can propagate throughout the entire pipeline, impacting everything from analytics to business decisions.
Here are a few common checks during source validation:
Field completeness
It is essential to ensure that all required fields are present and populated. Missing critical data, such as customer names or transaction values, could make the dataset incomplete or unusable.
|
For instance, imagine importing customer data without ensuring that the email address field is always filled. This would hinder email marketing campaigns and customer communication. |
Data formatting
Data formatting errors are a common issue during source ingestion. Ensuring that data adheres to a consistent format (e.g., dates in YYYY-MM-DD format, phone numbers in a standard format) prevents downstream errors.
Inaccurate formatting can trigger issues in data processing steps or result in incorrect visualizations and analyses.
Schema validation
Data should align with the predefined schema or structure expected by the downstream systems. This includes ensuring that data types match, such as ensuring integers are not stored as strings or dates are in a valid format.
|
For example, financial data containing currency amounts must follow the proper data type, such as decimal or float, and should not be entered as text. |
Data enrichment validation
For data pipelines involving third-party sources or API integrations, it’s critical to check the validity and accuracy of the data being enriched. An incorrect API response or outdated data from a third-party service can undermine the entire dataset’s quality.
Effective source validation helps minimize the chances of incomplete or erroneous data entering the system, saving time and resources that would otherwise be spent on cleaning and correcting downstream issues.
Transformation validation (during ETL/ELT)
Once data has been ingested into the pipeline, the next step is transformation, part of the ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) process.
During transformation, raw data is cleaned, standardized, and converted into the format required for storage and analysis. This step is where business rules are applied to refine and enrich the data.
Because this stage involves significant changes to the data, it’s essential to verify that these transformations are performed correctly. A single misapplied rule can result in errors that affect everything from report generation to machine learning model accuracy.
Key aspects of transformation validation include:
Business rule validation
Ensure that business rules are applied correctly to the data.
|
For example, if one of the business rules states that an employee’s age must be over 18, data transformations should validate this rule for every record during processing. If a record is found where the employee's age is below 18, it should be flagged for further investigation. |
Data loss prevention
It is essential to validate that no data is lost during the transformation process. Transformation steps, such as merging multiple datasets or performing aggregations, could potentially lead to data loss if not properly handled.
Ensuring that every row of data is accounted for after transformation is crucial to maintaining data completeness.
Correctness of calculations
Transformation processes often involve calculations or derived values (e.g., summing sales amounts or calculating customer lifetime value). Validating that these calculations are accurate and meet expectations is essential.
|
For instance, if you are calculating the average purchase value, you need to ensure that the formula is correctly applied and that the final results reflect real-world expectations. |
Data standardization
This step often involves converting various formats into standardized values (e.g., transforming address data into a consistent format). Transformation validation ensures that the changes are applied correctly and no inconsistencies arise between different datasets or data points.
By performing thorough transformation validation, organizations can ensure that the data is accurately processed and ready for use in business intelligence or machine learning applications.
Post-load / target validation (Post-ETL/ELT)
After data has been loaded into its final destination, typically a data warehouse, data lake, or analytics platform, post-load validation is crucial. This stage ensures that the data in the target environment is accurate, complete, and consistent with the data source, making it ready for analysis and reporting.
Post-load validation includes the following checks:
Data integrity
One of the key areas to verify during post-load validation is the integrity of relationships between different datasets.
|
For example, if you have a customer table and an orders table, you must ensure that each order record correctly references an existing customer ID. Violating these relationships could lead to “orphan” records, which disrupt analytics and decision-making. |
Completeness checks
After the data has been loaded, it’s vital to verify that all records have been transferred correctly. This involves ensuring that the number of records in the target system matches the number of records processed from the source system.
Missing records due to incomplete loading could result in significant gaps in reporting or decision-making.
Final consistency checks
Ensure that the data in the target environment aligns with what was expected.
|
For instance, data transformations might be applied during the ETL process, so a final consistency check ensures that all data meets the original business requirements and quality standards. This includes cross-checking values and ensuring there are no unexpected anomalies or errors in the target system. |
Performance validation
In addition to verifying the data’s quality, it’s important to ensure that the data pipeline itself is performing efficiently. This might include checking that data loading times are within expected thresholds and that the system can handle large data volumes without performance degradation.
By performing thorough post-load validation, businesses can ensure that their data is both accurate and usable, and that it adheres to the standards necessary for driving business insights.
Effective data quality testing not only ensures the reliability of your data but also optimizes business processes, minimizes risks, and maximizes the value of your data assets.
By systematically applying data quality tests at every stage of the pipeline, organizations can avoid the pitfalls of bad data and leverage high-quality information for accurate, data-driven decision-making.
Common data quality testing techniques & methods
From ensuring accuracy to maintaining consistency, there are several techniques used to verify the integrity of the data at various stages of the pipeline.
Below, we’ll explore some of the most common data quality testing methods, each focusing on a unique aspect of data quality.
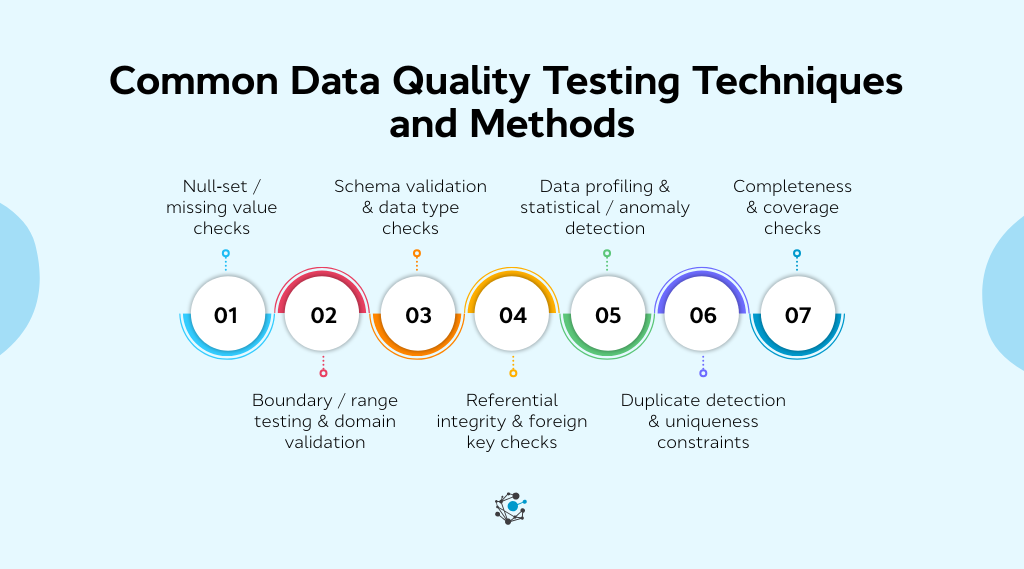
Null-set / missing value checks
Missing or null values are one of the most common and impactful data quality issues. Data pipelines frequently deal with raw inputs from various sources, and missing values can cause significant problems if not addressed.
|
For example, in customer data, missing values for key attributes like "age," "email address," or "purchase history" can severely impact decision-making and analytics, such as targeting personalized marketing campaigns or understanding customer demographics. |
Here are a few key data quality testing methods for handling missing values:
Flagging missing data for review
One common approach is to flag records with missing data for further investigation. While this allows analysts to review and decide how to handle the missing values, it’s a manual approach and can slow down processing.
Imputation
Another method is replacing missing values with imputed values.
|
For instance, in a sales dataset, missing sales amounts can be replaced with the mean or median of surrounding records. Advanced techniques also involve predictive imputation, where missing values are filled using statistical models based on other columns of the data. |
Deletion
In some cases, the simplest solution is to remove rows or columns with missing data, especially when they are few and far between. However, this is only effective when missing data is rare, as deleting data can lead to data loss and reduce the accuracy of insights.
The method used to handle missing values will depend on the nature of the dataset and the specific business context, but each solution must be tested for its impact on data quality and the validity of subsequent analysis.
Boundary/range testing & domain validation
Boundary testing is a critical part of validating numerical or date-based fields in datasets. If left unchecked, invalid values can distort analyses and lead to erroneous conclusions.
|
For instance, a dataset containing customer ages where some records list ages as 150 years old would signal a data integrity issue. |
Here are a few best practices for boundary and range testing:
Validating age ranges
Ensuring that numeric fields like "age" fall within logical boundaries (e.g., age should be between 20 and 70) can prevent outliers from skewing analysis. Similarly, for "date of birth" fields, verifying that the date falls within a reasonable range is essential.
Date validations
Date fields must adhere to specified formats and lie within acceptable ranges.
|
For example, financial transactions should not have future dates, and booking systems should not allow dates in the past when validating event scheduling. |
Threshold testing
For fields like sales revenue or customer balances, range checks can validate whether values fall within predefined thresholds.
|
For instance, ensuring that a product price is not listed as zero or negative can prevent errors in financial reporting. |
Effective boundary and range testing helps identify inconsistencies early in the data pipeline, preventing errors from propagating to downstream systems where they can cause significant issues.
Schema validation & data type checks
Ensuring that data conforms to a specific schema, the structure and types of the fields in a dataset, is a foundational part of data quality testing.
Schema validation ensures that each field adheres to its defined data type (e.g., numeric, string, date) and that the field lengths are within permissible limits. Here’s why schema validation matters:
Data type matching
Data type mismatches can lead to processing errors or inconsistent results.
|
For example, if a numeric field (such as "price") is populated with text, operations such as sum or average calculations could fail. |
Schema validation ensures that all values adhere to their expected data types and are processed correctly.
Field length validation
For text fields like customer names or addresses, it’s crucial to check that the field lengths don’t exceed limits set by the schema. Data integrity can be compromised if the system truncates values or allows excessively long entries, leading to potential errors or data inconsistency.
By incorporating schema validation into your testing framework, you ensure that the data remains structured, compatible with downstream systems, and aligned with business rules.
Referential integrity & foreign key checks
In relational databases, maintaining referential integrity is essential to ensure that relationships between different datasets are consistent. If foreign keys (which link tables together) reference non-existent records or fail to align with primary keys, the result is "orphaned" data, which compromises the reliability of the dataset.
Here are a few key aspects of referential integrity checks:
Foreign key validation
Ensuring that foreign key values in one table match valid primary keys in related tables is one of the most important aspects of data validation.
|
For example, in an order management system, ensuring that each "order" is linked to a valid "customer" record is critical. |
Cascade integrity
In some cases, foreign key relationships require cascading updates or deletions. If a record in a parent table is deleted, all related records in the child table should also be deleted, or a rule should be applied to prevent this action if data is still being referenced.
Preventing orphan records
Referential integrity checks can identify and resolve orphaned records, instances where a child record has no corresponding parent record. This can happen, for example, when a customer record is deleted, but the associated orders are still present in the system.
Ensuring referential integrity is vital for maintaining data accuracy and preventing the propagation of errors that could lead to flawed analyses or operational decisions.
Data profiling & statistical / anomaly detection
Data profiling is the process of analyzing the structure, quality, and relationships within datasets. This technique allows data engineers and analysts to understand the data's distribution, detect anomalies, and ensure that the data is representative of the business context.
Data profiling enhances data quality testing in the following ways:
Statistical profiling
By assessing the mean, median, mode, and distribution of data values, you can identify data quality issues that might not be obvious at first glance.
|
For example, if sales data for a product is consistently much higher than other products in the same category, it may indicate a data error. |
Anomaly detection
Statistical tests can be applied to detect outliers or anomalies.
|
For instance, in financial transactions, a sudden spike in one customer’s spending might indicate fraudulent behavior or data entry errors. |
Data profiling helps uncover these anomalies, which can then be flagged for investigation.
Understanding data distribution
Profiling allows organizations to better understand their datasets' range, common patterns, and outliers, thus improving the data's usability for analysis. Data engineers can use this insight to develop more effective validation checks or even build predictive models based on data distributions.
Duplicate detection & uniqueness constraints
Duplicate data can significantly impact data analysis, leading to skewed results, wasted resources, and missed opportunities. Duplicate detection is the process of identifying and removing redundant records, ensuring that each piece of data in the system is unique.
Key approaches to duplicate detection:
Exact match detection
One of the simplest methods of duplicate detection is comparing records for exact matches across critical fields (e.g., customer ID, product SKU). This is particularly useful for identifying redundant records that have been entered multiple times due to human error or system glitches.
Fuzzy matching
In cases where duplicates are not exact matches (e.g., spelling variations or missing characters), fuzzy matching algorithms can be employed.
|
For instance, "John Smith" and "Jon Smith" might be detected as duplicates with fuzzy matching, allowing the system to consolidate these entries into one. |
Unicity constraints
Enforcing uniqueness constraints in databases ensures that fields that must be unique (e.g., email addresses or user IDs) do not contain duplicates. This is often implemented as part of the database schema itself but should be validated through regular data quality tests.
Removing duplicates ensures that analyses are based on accurate and unique data, which is critical for reliable reporting and decision-making.
Completeness & coverage checks
Completeness testing is a key aspect of ensuring that all required data is present and accounted for in the dataset. Missing data can lead to biased results or incomplete insights, particularly in large-scale datasets that aggregate information from multiple sources.
Few essentials completeness checks include:
Field completeness
Ensuring that all mandatory fields are populated is a fundamental check.
|
For instance, in a customer database, missing data for crucial fields such as “email address” or “phone number” could affect customer outreach efforts. |
Record completeness
Completeness also refers to ensuring that every expected record is present. If you’re processing transaction data, for example, you need to ensure that all expected records for each transaction period are included in the dataset. Missing records can lead to skewed financial reports.
Cross-source completeness
In complex systems where data is drawn from multiple sources, completeness checks ensure that all expected data has been integrated correctly.
|
For instance, if a sales database is integrated with an inventory database, you need to verify that each sale record corresponds to a valid inventory record. |
By performing completeness and coverage checks, organizations ensure that they have the necessary data for accurate analysis and decision-making.
By applying these techniques systematically, organizations can prevent data errors from propagating through the system, minimize risks, and maximize the value of their data for business insights and decision-making.
Key aspects of data quality testing
Data quality testing is an ongoing process designed to ensure that data used for analysis, decision-making, and machine learning is both reliable and accurate. Inaccurate or incomplete data can result in costly mistakes, from flawed reports to misguided business strategies.
Data quality testing covers several core areas to ensure that the data is fit for its intended purpose.
Data accuracy & validation checks
Data accuracy is foundational to any data-driven process. Accurate data is crucial for ensuring that your insights, decisions, and predictions are based on the correct information.
Accuracy checks involve verifying that data reflects the real-world entities it represents, ensuring that values are both correct and within the expected range.
A common problem in data accuracy is human error or system malfunction that leads to incorrect data entries.
|
For instance, a sales team may mistakenly enter a price as $100 instead of $1,000. Automated validation checks can catch these discrepancies by flagging values that don't match predefined business rules or expected ranges. |
To avoid these accuracy errors, cross-check data with authoritative sources to verify its correctness, such as validating address data with postal services. Apply domain-specific rules (e.g., validating product prices or customer ages) during data entry to prevent errors.
These accuracy checks are critical in ensuring the data is trustworthy and can be used confidently for business processes.
Completeness testing
In any dataset, missing or null data is a common issue that can severely impact data analysis and decision-making. Missing data can skew analysis, particularly in sensitive areas like financial forecasting or customer behavior analysis.
|
For example, if a sales dataset is missing transaction amounts, it can lead to inaccurate revenue reporting. |
Completeness testing aims to identify missing data and handle it appropriately, ensuring that the dataset is as complete as possible.
-
When data is missing in critical fields, it can be flagged for manual review to determine whether the record should be completed or deleted.
-
Statistical techniques like mean or median imputation can be used to fill in missing values, especially when the missing data is small and non-critical. In some cases, predictive imputation using machine learning models can estimate missing values based on patterns in the data.
-
In cases where missing data is significant and cannot be reasonably imputed, entire rows or columns may be deleted to prevent them from skewing the analysis.
Handling missing data efficiently ensures that datasets remain robust and actionable for downstream processes.
Consistency
Data consistency refers to the uniformity of data across different systems, databases, or sources. Inconsistent data can lead to confusion, errors in reporting, and misaligned business strategies.
Data consistency checks ensure that the same data values are represented consistently across all platforms and systems.
|
For example, different departments may store the same data (e.g., customer names, product descriptions) in different formats, leading to confusion. One department may abbreviate "street" as "St" while another spells it out fully as "Street." |
-
Standardization: Implementing data entry standards and using consistent naming conventions across systems helps maintain uniformity.
-
Data integration tools: Data integration tools, like ETL (Extract, Transform, Load) systems, can automatically detect and correct consistency issues during the data pipeline process.
-
Automated monitoring: Setting up automated checks ensures that consistency is maintained as data moves between systems.
Maintaining consistency across all systems is vital for accurate analysis and smooth business operations.
Timeliness
Timeliness is an important aspect of data quality, especially in systems that depend on real-time or near-real-time data. If data isn't updated or ingested quickly enough, the insights derived from it may be outdated or irrelevant, potentially leading to misguided decisions.
|
For example, in industries like e-commerce or finance, delays in data processing can impact decisions. If an e-commerce site’s inventory system isn’t updated in real-time, customers might order products that are out of stock, leading to dissatisfaction and lost sales. |
-
Real-Time data processing: Implementing systems that support real-time or near-real-time data processing helps ensure that decisions are based on the most current information.
-
Data latency monitoring: Use monitoring tools to track data latency and set alerts if the delay exceeds acceptable thresholds.
Timeliness ensures that the data you rely on is as current as possible, supporting better decision-making and operations.
Uniqueness
Duplicate data is a common issue that can seriously impact data integrity and analytical outcomes. Duplicates distort analysis by inflating counts or distorting calculations like averages, totals, or trends. Duplicate records often result from data entry errors or system integration issues.
|
For instance, a customer might be entered twice in a CRM system under different records due to a typo or system bug, leading to duplicate marketing efforts or skewed reports. |
-
Exact match detection: This involves checking for exact duplicates by comparing records for identical values in critical fields such as customer ID or product SKU.
-
Fuzzy matching: For records that may contain slight differences (e.g., spelling variations), fuzzy matching can be used to identify potential duplicates and consolidate them.
-
Unique constraints in databases: Enforcing unique constraints (e.g., unique customer IDs) at the database level ensures that duplicates cannot be inserted in the first place.
Eliminating duplicates ensures the accuracy of reports, improves customer interactions, and reduces waste in operational processes.
Data integrity
Data integrity ensures that relationships between data entities are preserved and correct.
|
For example, in relational databases, foreign key checks verify that references between tables are consistent, ensuring that no orphan records (i.e., records with broken references) exist. |
If a foreign key in one table points to a non-existent record in another table, it can cause errors in reports or data analysis.
|
For example, in a sales database, an order might refer to a non-existent product if the foreign key relationship isn’t properly maintained. |
-
Foreign key constraints: These constraints ensure that a foreign key in one table must correspond to an existing primary key in another table, preserving the integrity of relationships.
-
Cascading updates/deletes: To maintain data integrity, cascading updates or deletions can be implemented so that related data is automatically updated or deleted when the original record is modified.
Referential integrity is crucial for maintaining accurate, trustworthy data relationships across databases.
Schema and structure validation
Schema validation ensures that the data conforms to the expected structure, including field types, field lengths, and mandatory fields. By ensuring that data follows a predefined schema, businesses can avoid errors that arise from inconsistent or incompatible data formats.
Inconsistent field lengths or incorrect data types can cause issues during data processing, leading to truncation or errors in data analytics.
|
For example, if a field is defined as an integer but contains string values, the database will throw an error during analysis. |
-
Automated schema validation: Use automated testing tools to regularly check if incoming data adheres to the expected schema, ensuring that all field types, lengths, and values are correct.
-
Field-level validation: Ensure that all mandatory fields are present and correctly populated, and that data types match the schema.
Schema validation provides consistency in how data is structured and enables smooth data processing and analysis.
Error logging and remediation processes
When data quality issues are identified during testing, they must be logged for investigation and resolution. Error logging helps track the issues, ensuring they are properly addressed and do not repeat.
Without an effective logging and remediation process, data issues may go unnoticed, leading to bigger problems down the line.
|
For example, missing data might not be flagged, causing errors in reports or analytics. |
-
Automated error logging: Implement automated tools to track errors and log them for future reference.
-
Root cause analysis: Use error logs to identify the root causes of recurring issues and implement corrective measures to prevent future occurrences.
Logging errors and tracking their remediation ensures that data quality issues are quickly identified, addressed, and prevented from impacting future operations.
Each of these testing areas contributes to building a solid data foundation that enhances business decisions, optimizes operational efficiency, and reduces risk. Effective data quality testing is not a one-time activity but an ongoing process that keeps data aligned with business needs and standards.
Conclusion
-
Is your data accurate, consistent, and complete?
-
What happens when data errors go unnoticed in your operations or decision-making?
-
How much revenue or efficiency is lost due to unreliable data?
When data quality is compromised, businesses face significant consequences. Inaccurate or inconsistent data can lead to operational inefficiencies, poor decision-making, and financial losses.
|
For example, errors in customer data can cause marketing campaigns to misfire, while poor financial data can result in misguided investments or compliance risks. Data quality testing is crucial to identify and resolve these issues early, ensuring that data remains reliable, consistent, and actionable. |
By regularly testing data, organizations can prevent costly mistakes, maintain operational efficiency, and make data-driven decisions with confidence.
Struggling with poor data quality impacting your bottom line?
OvalEdge helps you proactively identify and fix data issues before they disrupt your operations.
Book a demo now to see how OvalEdge can boost your data quality and protect your business from costly mistakes.
FAQs
1. What is the difference between data quality and data integrity?
Data quality refers to the accuracy, completeness, and consistency of data. Data integrity, however, focuses on the consistency and reliability of data throughout its lifecycle, ensuring it remains unchanged and trustworthy, especially during storage or transmission.
2. What are the pillars of data quality testing?
The main pillars of data quality testing include accuracy, completeness, consistency, timeliness, and validity. These aspects ensure data is reliable, consistent across sources, complete, and available when needed, supporting effective decision-making.
3. What are the different types of data quality testing?
Common types of data quality testing include validation checks (ensuring data conforms to rules), completeness checks (identifying missing data), range testing (validating numerical data), deduplication (eliminating duplicates), and consistency checks (ensuring uniform data across systems).
4. How often should data quality testing be conducted?
Data quality testing should be a continuous process, integrated into data pipelines. Regular checks should occur at each data ingestion, transformation, and loading stage to ensure ongoing accuracy, consistency, and completeness across systems.
5. What role does automation play in data quality testing?
Automation streamlines the testing process, improving efficiency and reducing human error. Automated tools can quickly identify and flag data issues, ensuring real-time monitoring and resolution without manual intervention, which is crucial for large-scale data operations.
6. Can data quality testing be applied to all types of data?
Yes, data quality testing applies to all types of data, whether structured or unstructured. It ensures that data from databases, spreadsheets, logs, or even IoT devices is accurate, complete, and reliable, regardless of its format or source.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)