Enterprises are struggling to scale analytics, AI, and governance through traditional centralized data delivery models. This blog explains how a data product operating model helps organizations improve domain ownership, governance consistency, discoverability, and operational accountability. It explores the relationship between data products, federated governance, metadata, and self-service analytics while outlining practical implementation steps for enterprise teams.
Enterprises are generating more data than ever, yet many still struggle to scale analytics, AI initiatives, governance, and self-service access. Traditional centralized data delivery often creates bottlenecks: data teams are overloaded with requests, governance slows access, and business units rely on inconsistent metrics.
As organizations expand across finance, sales, customer operations, and supply chain, these limitations become more visible. Duplicate pipelines, unclear accountability, poor discoverability, and fragmented governance erode trust.
According to Salesforce’s Connectivity Benchmark Report 2024, 81% of IT leaders say data silos hinder digital transformation, underscoring the urgency for change.
This complexity is driving the adoption of a data product operating model, where data is managed as reusable, governed, business-aligned products with defined ownership.
This guide explores what a data product operating model is, why enterprises are adopting it, how it supports scalable governance and self-service analytics, and the practical steps organizations can take to operationalize governed data products across distributed teams and domains.
What is a data product operating model?
A data product operating model is the organizational, governance, and delivery framework that defines how data products are created, owned, governed, published, consumed, and improved. It is not only a technical architecture.
It is the way people, processes, policies, platforms, and accountability come together so data can be managed like a reusable business asset. If you are still mapping out the building blocks, our guide to data product design covers how individual products get structured before they roll up into an operating model.
Data product operating model vs centralized data teams
Traditional centralized data teams typically manage engineering, governance, and data delivery through a request-driven model. While this approach can work for smaller environments, it often becomes difficult to scale as analytics, AI, and self-service demands increase across business domains.
A data product operating model shifts ownership closer to the business domain. Domain teams manage the data products aligned with their operational context, while central teams provide shared governance standards, platforms, and enablement capabilities. This approach supports faster delivery, clearer accountability, and more scalable governance.
|
Area |
Centralized data model |
Data product operating model |
|
Ownership |
Central data or IT team |
Domain-oriented ownership |
|
Delivery |
Request-driven backlog |
Product-oriented lifecycle |
|
Governance |
Central approval bottlenecks |
Federated governance standards |
|
Reuse |
Often inconsistent |
Designed for reuse |
|
Discovery |
Depends on tribal knowledge |
Metadata-driven catalog and marketplace |
|
Accountability |
Shared or unclear |
Assigned product and domain owners |
The operational difference is significant. Centralized teams primarily focus on fulfilling requests, while data product teams focus on delivering reliable, reusable, and governed data products that consumers can easily discover and trust.
Core principles of a data product operating model
A strong operating model is built around a few practical principles.
-
Domain ownership: It means business domains are accountable for the data they understand best. Finance owns finance definitions, customer teams own customer context, and supply chain teams own supply chain logic.
-
Data-as-a-product thinking: It means data is managed with consumers in mind. It needs clear documentation, quality expectations, access rules, ownership, lifecycle management, and feedback loops.
-
Federated governance: It balances local ownership with enterprise-wide consistency. BCG’s 2024 report on federated data governance explains that decentralized governance places more accountability on domain owners while aligning data management with business needs and operational context.
-
Self-service platform enablement: It gives teams common tools for cataloging, lineage, access requests, workflow automation, quality monitoring, and collaboration.
-
Metadata-driven discoverability: It makes data products searchable and understandable. Without strong metadata management best practices, self-service analytics becomes guesswork.
These principles work together operationally. Domain teams own and improve the product, governance teams define standards, platforms automate workflows, and consumers use certified data products with greater confidence.
How data mesh influences the operating model
Data mesh has strongly influenced the data product operating model. It promotes domain ownership, data-as-a-product thinking, self-service platforms, and federated governance to help organizations scale data operations more effectively.
However, data mesh cannot succeed through architectural principles alone. Organizations still need operational clarity around ownership, governance, access management, quality monitoring, metadata management, incident resolution, and lifecycle accountability.
This is where the data product operating model becomes important. Data mesh defines the architectural and organizational philosophy, while the operating model provides the execution framework that translates those principles into day-to-day workflows, governance standards, roles, and operational accountability.
Why enterprises are adopting data product operating models
Enterprises are adopting data product operating models to improve scalability, accountability, and governance as data usage expands across analytics, AI, and business operations. Traditional delivery models often struggle to support growing demands across distributed teams and domains.

1. Scaling beyond centralized data ownership
Centralized data teams can slow delivery as requests increase across multiple business functions. As organizations expand across cloud, SaaS, and hybrid environments, managing growing data complexity through a single team becomes difficult.
A data product operating model distributes ownership across domains while maintaining shared governance standards. This helps organizations improve delivery speed and reduce operational bottlenecks.
2. Improving domain accountability
Many organizations struggle with unclear ownership across datasets, metrics, and governance processes. This often creates delays in decision-making and inconsistent operational accountability.
Domain-oriented ownership improves clarity by assigning responsibility directly to business-aligned teams. This creates stronger accountability for governance, reliability, and data consistency.
3. Supporting self-service analytics at scale
Self-service analytics becomes difficult when users cannot easily identify trusted and reusable data assets. Poor discoverability and inconsistent documentation often reduce confidence in enterprise data.
Data product operating models improve discoverability through metadata, catalogs, lineage, and certification workflows. This helps users access governed and reusable data products more efficiently.
Key roles in a data product operating model
A data product operating model depends on clearly defined ownership and governance responsibilities. Without operational accountability, organizations often struggle with inconsistent governance, low adoption, unclear escalation paths, and fragmented decision-making across data products.
The most effective operating models establish a cross-functional structure where business, governance, and technical teams collaborate throughout the entire data product lifecycle.
-
Data product owner: Responsible for defining the product vision, aligning the product with business goals, and ensuring long-term value delivery. This role typically owns adoption, lifecycle accountability, stakeholder alignment, and overall trust in the data product across the organization.
-
Data product manager: Focuses on execution and coordination across the product lifecycle. Responsibilities include prioritization, roadmap planning, consumer alignment, delivery management, and communication between business, governance, and engineering teams.
-
Data steward: Manages operational governance responsibilities such as metadata management, glossary alignment, policy enforcement, access governance, quality monitoring, and governance compliance support.
-
Data producers: Responsible for source system reliability, data generation processes, and pipeline stability. They help ensure data products are delivered consistently and support downstream analytics and reporting requirements.
-
Data consumers: Include analysts, AI teams, business users, and application teams that consume data products for reporting, analytics, operational decision-making, and AI initiatives. Their feedback helps validate product usability, trust, and business relevance.
These roles collaborate through shared governance workflows and operational processes. Product owners define priorities, stewards maintain governance standards, engineering teams support reliability, and consumers contribute feedback that helps improve product quality and adoption over time.
How to build a data product operating model
Building a data product operating model requires clear ownership, standardized governance, and scalable self-service workflows across domains. The goal is to help teams manage trusted and reusable data products while maintaining enterprise-wide consistency and operational control.
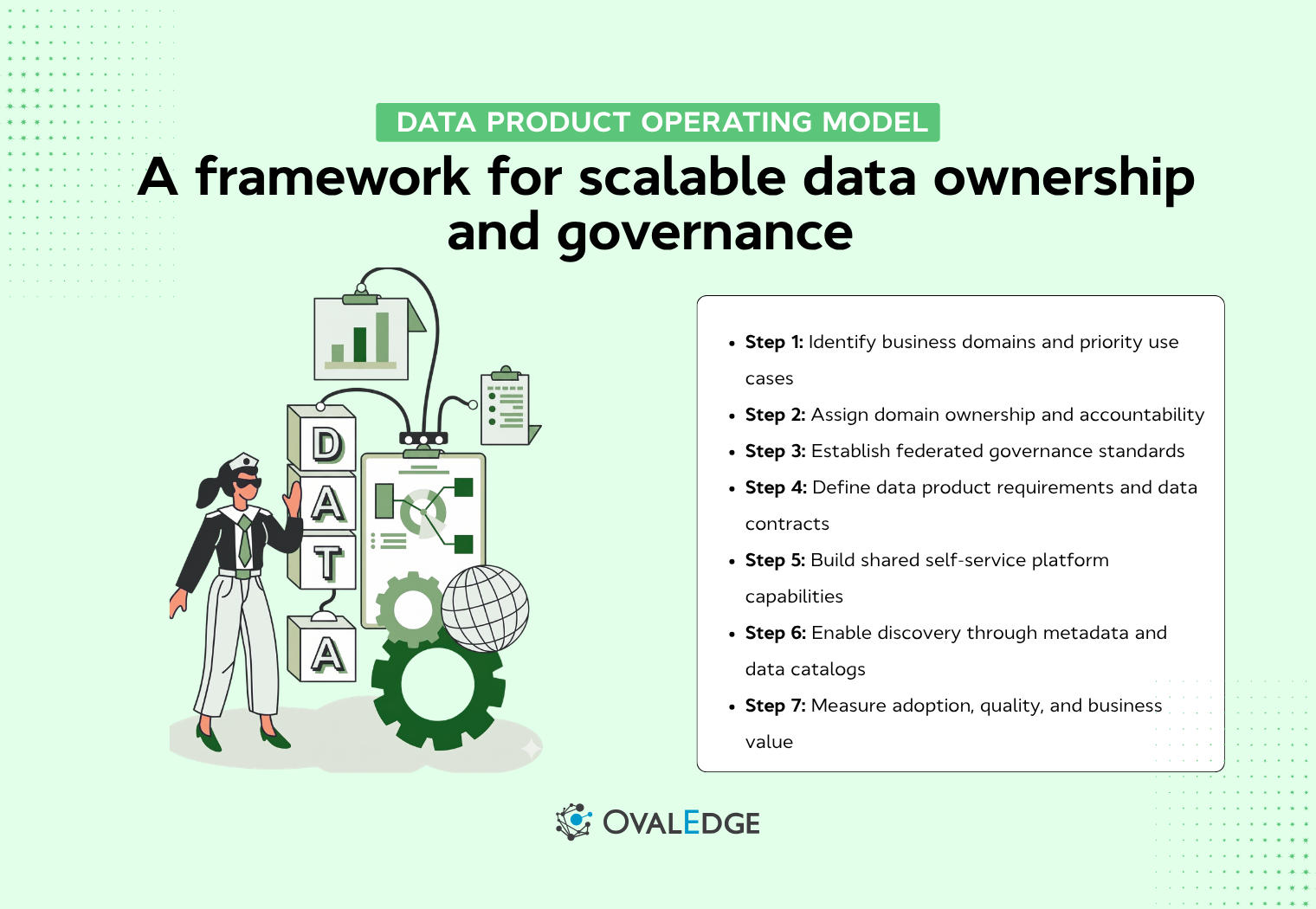
Step 1: Identify business domains and priority use cases
The first step is identifying business domains where data ownership naturally belongs. Domains should reflect operational functions such as finance, customer, sales, operations, marketing, or supply chain instead of technical systems or databases.
This approach improves accountability because business teams already understand the context behind the data they generate and consume. For example, finance teams are best positioned to manage revenue metrics and forecasting logic, while customer operations teams better understand customer engagement and support data.
Organizations should avoid trying to transform every domain at once. The most effective operating-model initiatives begin with high-value use cases where governance issues, reporting inconsistencies, or analytics bottlenecks already exist.
Common starting points include:
-
Executive reporting
-
Customer analytics
-
AI and ML initiatives
-
Regulatory reporting
-
Supply chain analytics
|
For example, customer analytics is often an ideal starting point because sales, marketing, and support teams frequently maintain different customer definitions across systems. A governed customer data product helps standardize metrics while improving consistency across reporting and analytics workflows. Looking at a few data products examples can help teams picture what a finished product looks like before they commit to a domain. |
Starting with a few domains also allows organizations to validate governance processes, ownership models, and metadata standards before scaling further.
Step 2: Assign domain ownership and accountability
Clear ownership is foundational to a scalable data product operating model. Without defined accountability, organizations often face unresolved quality issues, inconsistent reporting, and delayed governance decisions.
Each domain should define ownership for:
-
Data quality
-
Access approvals
-
SLA management
-
Policy enforcement
-
Escalation workflows
-
Metadata maintenance
A key distinction here is separating technical ownership from business accountability. Engineering teams may manage infrastructure and pipelines, but business-aligned owners remain responsible for product definitions, reliability expectations, and lifecycle decisions.
|
For example, a finance data product owner may oversee revenue definitions and reporting consistency, while engineering teams manage pipeline freshness and operational reliability. If reporting discrepancies appear before a quarterly business review, ownership clarity ensures the right teams investigate and resolve issues quickly. |
Clear ownership also improves trust because analysts and business users know who maintains and governs each data product.
Step 3: Establish federated governance standards
Federated governance helps organizations balance domain autonomy with enterprise-wide consistency. Fully centralized governance models often create bottlenecks, while fully decentralized governance leads to fragmented standards and disconnected workflows.
A federated model allows central governance teams to define enterprise-wide policies while domains manage operational execution locally.
Organizations should standardize governance areas such as data classification, access controls, metadata requirements, naming conventions, data quality policies, and compliance workflows.
|
For example, a healthcare organization may define centralized policies for sensitive patient data while allowing individual business domains to apply governance controls within their operational workflows. Similarly, financial institutions often maintain centralized compliance standards while enabling local stewardship across business units. |
This structure improves scalability because domains can operate independently without bypassing governance requirements. It also improves interoperability because teams follow shared metadata and policy standards across the organization.
Federated governance becomes especially important for AI initiatives, where organizations need consistent lineage, quality controls, and policy visibility across multiple domains.
Step 4: Define data product requirements and data contracts
Data products should include clear operational definitions so producers and consumers understand reliability expectations, governance requirements, and usage standards. This is closely tied to scalable data product lifecycle management, since requirements, versioning, and change management all play out over a product's full life.
Data contracts become especially important when multiple domains depend on shared datasets. They define expectations around schema stability, update frequency, quality standards, and change-management workflows.
|
For example, if a sales team changes transaction data structures used by finance reporting or AI systems without communication, downstream workflows may fail unexpectedly. Data contracts help manage schema changes, notifications, version management, and escalation processes, reducing operational disruptions across domains. |
Step 5: Build shared self-service platform capabilities
Distributed ownership requires shared platform capabilities that simplify how teams publish, manage, and access data products across domains. Without common platforms, organizations often struggle with disconnected workflows, inconsistent tooling, and duplicated governance efforts.
Organizations should provide capabilities such as data catalogs, workflow automation, observability, access governance, and policy management. These platforms help standardize operational processes while allowing domains to manage products independently.
|
For example, centralized enablement platforms allow teams to publish data products through consistent workflows while helping users request access, monitor usage, and collaborate more efficiently. Automation also reduces manual stewardship and governance overhead across growing data environments. |
Step 6: Enable discovery through metadata and data catalogs
Discoverability is critical for increasing data-product adoption across analytics and AI teams. If users cannot quickly identify trusted assets, they often recreate datasets or rely on disconnected reporting workflows.
Metadata-driven discovery helps users understand business context, ownership, certification status, usage relevance, and approved definitions before consuming a product.
For example, a finance analyst searching for recurring revenue metrics should immediately identify the enterprise-approved dataset instead of comparing multiple undocumented tables.
|
Practical insight: OvalEdge’s data catalog capabilities help enterprises improve discoverability, ownership visibility, business context, and certification workflows across distributed data environments. Want to improve trusted data discovery across domains? Book a demo with OvalEdge to explore metadata-driven governance and marketplace-style discovery workflows. |
Step 7: Measure adoption, quality, and business value
A data product operating model should be continuously measured and refined. Without measurement, governance initiatives often become documentation exercises instead of scalable operational frameworks.
Organizations should track KPIs such as product adoption, reuse rates, SLA compliance, metadata completeness, data quality scores, governance adherence, and consumer satisfaction.
|
For example, high search activity with low product usage may indicate weak documentation or low trust. Frequent SLA breaches may highlight ownership gaps or reliability issues. |
Continuous measurement helps organizations improve governance maturity and long-term operational performance.
Technology stack for data product operating models
Technology does not replace operating discipline, but it makes the model scalable. Enterprises need platforms that connect governance, discovery, observability, access, and collaboration across distributed domains.

1. Data catalogs and data marketplaces
Data catalogs centralize metadata and make data assets searchable across the organization, while data marketplaces improve how governed data products are discovered and consumed. Together, they help users identify trusted and reusable datasets more efficiently.
A strong catalog should provide business context, ownership visibility, lineage, quality indicators, usage insights, and certification status. This helps users understand whether a dataset is reliable before using it for reporting, analytics, or AI initiatives.
Data marketplaces further improve self-service analytics by supporting product-style discovery, standardized access workflows, and reusable consumption patterns. Instead of searching through disconnected tables, users can quickly identify certified data products aligned with their business needs.
2. Active metadata and automation
Active metadata connects metadata to workflows. Instead of documenting assets manually and letting the catalog go stale, active metadata supports automated classification, enrichment, relationship discovery, stewardship workflows, and governance automation.
This reduces manual governance overhead. It also helps teams scale policy enforcement across many domains.
For example, sensitive data can be classified automatically, stewards can be alerted when documentation is missing, and access workflows can reflect policy rules.
3. Lineage, observability, and policy enforcement
Lineage shows how data moves from source systems through transformations to reports, models, and applications. Observability monitors freshness, quality, anomalies, and reliability. Policy enforcement ensures access, classification, and compliance rules are applied consistently.
Together, these capabilities support operational reliability. When a dashboard breaks, lineage helps identify upstream changes. When a quality rule fails, observability triggers an investigation. When sensitive data is requested, policy workflows guide approval.
|
Operational insight: OvalEdge helps organizations improve data quality through automated monitoring, stewardship workflows, policy enforcement, and metadata-driven governance processes. |
For AI and analytics, this visibility is no longer optional. Teams need to know where data came from, whether it can be trusted, and whether it complies with business and regulatory requirements.
Common data product operating model challenges
Implementing a data product operating model requires organizational, governance, and operational changes beyond technology adoption. Many enterprises struggle with scaling ownership, governance consistency, and long-term operational accountability across domains.
-
Unclear ownership across domains: Organizations often struggle to define who owns data quality, access approvals, policy enforcement, and issue resolution. Without clear accountability, governance workflows become slow, and operational trust declines.
-
Governance ambiguity: Overly centralized governance can slow down domains, while loosely managed governance creates inconsistent standards across teams. Federated governance requires clearly defined policies, escalation workflows, and stewardship responsibilities.
OvalEdge supports enterprise data privacy and governance initiatives through classification workflows, access governance, policy management, compliance monitoring, and stewardship automation.
-
Low data product adoption: Many data products remain underutilized because they are poorly documented, difficult to discover, or missing trust indicators such as lineage, certification, and ownership visibility. Users need a clear business context and confidence before adopting reusable data products.
-
Treating data products as one-time projects: Some organizations focus heavily on initial implementation but overlook long-term lifecycle management. As schemas, business requirements, and compliance needs evolve, unmanaged data products gradually lose reliability and relevance.
-
Governance drift across domains: Domains may initially follow governance standards consistently, but diverge over time as workflows evolve independently. Continuous measurement, metadata standardization, stewardship workflows, and executive alignment are necessary to maintain long-term governance maturity.
Successfully implementing a data product operating model requires continuous governance refinement, strong executive alignment, and clear operational accountability across domains.
Organizations that treat data products as long-term business assets are better positioned to scale analytics, AI initiatives, and self-service data access effectively.
How OvalEdge supports data product operating model
OvalEdge helps organizations operationalize governance, metadata management, lineage visibility, and data-product discovery across distributed domains. Its platform supports federated governance models while helping teams manage domain-driven data operations more efficiently.
The platform provides centralized visibility into business context, ownership, lineage, and operational dependencies so users can better understand how data products are created, maintained, and consumed across the organization.
OvalEdge also supports marketplace-style publishing workflows that help organizations make certified datasets, metrics, and analytics assets easier to access and reuse across business teams.
|
Real-world impact of data marketplace adoption In OvalEdge’s European logistics company data marketplace case study, the organization implemented a marketplace-driven data governance approach to improve discoverability and governance consistency across teams. The company faced challenges with fragmented reporting workflows and difficulty identifying trusted datasets across domains. Outcomes of marketplace-style discovery workflows included:
|
OvalEdge’s lineage and governance capabilities also help teams monitor downstream dependencies, improve root-cause analysis, and support compliance monitoring across enterprise data environments.
Conclusion
A data product operating model helps enterprises move beyond overloaded centralized delivery models toward scalable and domain-aligned data operations. It enables organizations to improve operational coordination, reduce reporting inconsistencies, and support analytics and AI initiatives more effectively across distributed teams.
The long-term value comes from building sustainable operating practices rather than relying only on technology or one-time governance initiatives. Organizations that establish clear workflows, consistent standards, and measurable operational processes are better positioned to scale data operations without increasing complexity.
Start with a few high-impact domains, refine governance iteratively, and focus on operational maturity over time.
Platforms like OvalEdge can help organizations operationalize scalable data-product management through governance automation, operational visibility, and marketplace-style data accessibility.
Schedule a demo with OvalEdge to explore how your organization can build scalable, governed, and reusable data products that support long-term analytics and AI success.
FAQs
1. How does a data product operating model improve AI and analytics initiatives?
A data product operating model improves AI and analytics by creating standardized, reusable, and trusted data assets across domains. It helps teams access governed datasets faster, reduces duplication, improves data consistency, and supports scalable AI workflows through better metadata management, lineage visibility, and ownership accountability.
2. What is the difference between data ownership and data stewardship?
Data ownership focuses on business accountability, decision-making, and lifecycle management of data products. Data stewardship focuses on operational governance activities such as metadata maintenance, quality monitoring, policy enforcement, and access management. Both roles work together to maintain trusted and governed enterprise data environments.
3. Why are data contracts important in distributed data environments?
Data contracts help standardize expectations between data producers and consumers. They define schemas, update frequency, quality expectations, and change-management processes. This reduces operational disruptions, improves interoperability across domains, and helps organizations maintain reliable analytics and governance practices as data ecosystems scale.
4. How do data marketplaces support self-service analytics?
Data marketplaces improve self-service analytics by making trusted data products easier to discover, access, and reuse. They provide business context, ownership details, certification indicators, and governance visibility, helping analysts and business users identify reliable datasets without depending heavily on centralized data teams.
5. What challenges do enterprises face when implementing federated governance?
Enterprises often struggle with inconsistent policy enforcement, unclear ownership boundaries, fragmented tooling, and a lack of governance standardization across domains. Federated governance also requires strong collaboration between business and technical teams to balance domain autonomy with enterprise-wide governance and compliance requirements.
6. How can organizations measure the success of a data product operating model?
Organizations can measure success through adoption metrics, data quality improvements, reuse rates, governance compliance, analytics delivery speed, and consumer satisfaction. Operational indicators such as metadata completeness, SLA adherence, and issue-resolution efficiency also help evaluate the maturity and effectiveness of the operating model.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)