-1.png)
Without a data warehouse, enterprise data fragments fast. Metrics end up scattered across spreadsheets, ad hoc dashboards, and one-off reports. The same KPI shows different numbers depending on who built the query.
According to IBM Data Differentiator, 68% of enterprise data remains unanalyzed, trapped in disconnected systems where it can’t contribute to insights or decisions.
This fragmentation doesn’t just slow teams down; it buries potential value under layers of misalignment and duplication.
As data volume, sources, and users grow, these issues compound, turning analytics into friction rather than leverage.
You start hearing the same questions again and again:
-
Why doesn’t this dashboard match last week’s report?
-
Which table is the “source of truth”?
-
Can I trust this number before sharing it with leadership?
-
Who changed this metric, and when?
A data warehouse resolves this by becoming the system of record for analytics and governance. It centralizes data, enforces shared definitions, and applies access controls consistently.
In this blog, we will discuss what a cloud data warehouse solution is, how leading platforms differ, and the key features that matter most when choosing the right one for your organization
What is a cloud data warehouse solution?
A cloud data warehouse solution is a managed, cloud-native platform for storing, processing, and analyzing large volumes of data for analytics and reporting. The platform centralizes structured and semi-structured data for SQL-based querying and business intelligence.
The architecture separates storage from compute to support elastic scaling and cost-efficient usage. The solution supports batch and real-time workloads, strong security controls, and enterprise governance.
Organizations use cloud data warehouse solutions to modernize analytics, reduce infrastructure management, and enable faster, more reliable insights.
| Platform | Pricing model | Best for | Architecture |
| Snowflake | Credits / compute + storage | Multi-cloud analytics | Separated compute + storage |
| Google BigQuery | Per query / flat-rate slots | Analytics at scale | Fully serverless |
| Amazon Redshift | Node-based / serverless | AWS-native orgs | Provisioned or serverless |
| Databricks | DBU credits (per second) | ML + data engineering | Lakehouse on cloud object storage |
| Azure Synapse | DWU-based / serverless SQL | Microsoft stack | Dedicated pools or serverless |
Top cloud data warehouse solutions in 2026
The landscape of cloud data warehouse solutions has expanded rapidly, giving organizations more choice than ever before. While this flexibility is valuable, it also makes comparison more complex.
Each platform is designed around different assumptions about scale, cost, and workload behavior, which means understanding their core approaches is essential before evaluating specifics.

1. Snowflake
Snowflake is a fully managed cloud data warehouse solution designed to simplify analytics at scale. Its core innovation lies in decoupling compute and storage, allowing organizations to scale workloads independently without infrastructure planning.
Snowflake runs natively across AWS, Azure, and Google Cloud, making it one of the most visible multi-cloud data warehouse platforms on the market.
Snowflake is often adopted by organizations moving away from rigid on-prem data warehouses that struggle with concurrency, performance bottlenecks, and operational overhead.
Its architecture is purpose-built for analytics teams that need reliable performance across multiple workloads such as BI reporting, ad hoc analysis, and data sharing.
Key features
-
Separation of compute and storage: Compute clusters scale independently from storage, preventing reporting queries from blocking data transformations or other workloads.
-
Multi-cloud support: Snowflake runs on AWS, Azure, and Google Cloud, enabling deployment flexibility and reduced vendor lock-in risk.
-
Automatic scaling and concurrency handling: Virtual warehouses automatically scale up or down to handle spikes in query demand without manual intervention.
-
Support for semi-structured data: Native handling of JSON, Avro, and Parquet allows analytics on semi-structured data without complex preprocessing.
-
Secure data sharing: Snowflake enables governed data sharing across accounts without copying or moving data.
Pros
-
Strong performance for mixed BI and analytics workloads
-
Minimal infrastructure management
-
Mature governance, security, and access controls
-
Proven multi-cloud architecture
Cons
-
Costs can rise quickly with uncontrolled compute usage
-
Less native support for advanced data science workflows compared to lakehouse platforms
Pricing
Snowflake uses a simple, consumption-based pricing model, charging separately for compute credits and storage, with tiered editions that scale features, performance, security, and governance based on business needs.
Best for
Organizations that need a scalable, enterprise-ready cloud data warehouse with strong governance, high concurrency, and multi-cloud flexibility.
Ratings
What it can improve
Users repeatedly point to the lack of traditional optimization levers like indexes, native partitions, and full materialized view support as a genuine hurdle, not just a philosophical difference.
Cost predictability is another recurring concern. While Snowflake removes much of the operational burden, several engineers note that usage-based pricing shifts responsibility from capacity planning to behavioral discipline.
Without guardrails, poorly designed queries or ungoverned access can quietly drive up spend, which feels risky compared to fixed-cost systems.
For some, Snowflake feels less like a replacement for traditional enterprise warehouses and more like a different tool altogether, one that shines at scale but asks experienced teams to unlearn habits they relied on for years.
2. Amazon Redshift
Amazon Redshift is AWS’s flagship cloud data warehouse solution, designed for large-scale analytical workloads within the AWS ecosystem. It uses columnar storage and massively parallel processing to execute complex queries efficiently.
Redshift is commonly chosen by organizations already standardized on AWS infrastructure.
Redshift addresses common enterprise pain points such as slow query performance on large datasets and complex data integration pipelines. It integrates deeply with AWS services, which simplifies data ingestion, security, and orchestration for AWS-centric teams.
Key features
-
Provisioned and serverless deployment options: Organizations can choose predictable cluster-based deployments or on-demand serverless execution.
-
Tight AWS ecosystem integration: Native integration with Amazon S3, Glue, IAM, and SageMaker simplifies data pipelines and governance.
-
Columnar storage and query optimization: Designed to improve performance for analytical queries on large structured datasets.
-
Workload management: Queues and resource controls help prioritize critical reporting workloads.
-
Security and compliance controls: Built-in encryption, IAM-based access control, and auditing align with AWS security standards.
Pros
-
Strong performance for batch analytics
-
Deep integration with AWS services
-
Mature security and compliance features
-
Flexible deployment models
Cons
-
Limited multi-cloud portability
-
More operational tuning required than fully serverless platforms
Pricing
AWS pricing follows a pay-as-you-go model, charging only for consumed cloud services, with options for savings through commitments, volume usage discounts, private pricing, and tools to estimate and optimize costs
Best for
Organizations heavily invested in AWS that want a tightly integrated, high-performance cloud data warehouse.
Ratings
What it can improve
Redshift often feels easy to adopt inside AWS, but much harder to live with long-term.
A common complaint centers on performance unpredictability. Engineers describe spending significant time tuning sort keys, distribution styles, and query plans, only to see inconsistent results.
The system can feel opaque. Identical queries sometimes behave differently across runs, and when something fails, the error messages offer little insight into what actually went wrong. That black-box feeling comes up again and again.
User experience also plays a role. Compared to platforms like Snowflake or Databricks, Redshift feels dated to many users. Feature development appears slow, especially around areas that modern analytics teams expect to work well out of the box, such as semi-structured data, developer tooling, and introspection.
Redshift works best when teams deeply understand its internals and actively manage it. For teams looking for faster iteration, simpler operations, or a more modern analytics experience, that tradeoff increasingly feels hard to justify.
3. Google BigQuery
Google BigQuery is a fully serverless cloud data warehouse solution that removes infrastructure management entirely.
Users run SQL queries directly against large datasets without provisioning clusters or managing capacity. BigQuery is designed for organizations that value simplicity, elasticity, and rapid time to insight.
BigQuery is commonly adopted by data teams facing unpredictable query volumes, real-time analytics requirements, or fast-growing datasets that are difficult to size in advance.
Key features
-
Fully serverless architecture: No cluster setup or maintenance required, with automatic scaling for all workloads.
-
Pay-per-query and storage pricing: Costs are based on data processed and stored, aligning spend with actual usage.
-
Native support for streaming data: Real-time ingestion enables near-real-time dashboards and analytics.
-
Integration with Google AI and ML tools: Works seamlessly with BigQuery ML and other Google Cloud analytics services.
-
Standard SQL support:
Uses ANSI SQL, lowering the learning curve for analysts.
Pros
-
Extremely low operational overhead
-
Handles unpredictable workloads well
-
Fast query execution at large scale
-
Strong support for real-time analytics
Cons
-
Cost management can be challenging without query controls
-
Less flexibility for low-level performance tuning
Pricing
Google Cloud offers transparent, pay-as-you-go pricing with free credits, automatic usage-based savings, committed-use discounts, and built-in cost management tools to estimate, control, and optimize cloud spending
Best for
Teams that want a serverless data warehouse for large-scale analytics, real-time data, and minimal infrastructure management.
Ratings
What it can improve
BigQuery feels simple, powerful, and safe to experiment with. There are no clusters to size, no infrastructure to manage, and public datasets look like a perfect playground for learning or quick analysis. Then comes the bill.
The most common frustration isn’t that BigQuery is expensive by design. It’s that the cost model is dangerously easy to misunderstand.
Users describe running what they believe are small, harmless test queries, only to discover days later that those queries scanned terabytes of data. Because pricing is tied to data processed rather than intent, a poorly optimized filter or missing partition can quietly turn practice queries into a financial shock.
There’s also a sense that BigQuery’s power cuts both ways. Its ability to scan massive datasets instantly is impressive, but it removes natural guardrails. Traditional warehouses fail loudly when something goes wrong.
BigQuery succeeds silently and charges accordingly. Even experienced professionals admit that a single overlooked query pattern can spiral fast.
4. Databricks SQL Warehouse
Databricks SQL Warehouse is part of the Databricks lakehouse platform, combining data warehouse performance with data lake flexibility. It allows organizations to run SQL analytics directly on open data formats stored in cloud object storage.
Databricks appeals to teams that want to unify analytics, data engineering, and machine learning on a single platform rather than maintaining separate systems.
Key features
-
Lakehouse architecture: Supports analytics directly on open formats like Delta Lake without data duplication.
-
SQL-optimized execution engine: Designed for fast analytical queries while sharing infrastructure with Spark workloads.
-
Unified analytics and ML platform: Enables collaboration between analysts, engineers, and data scientists.
-
Elastic compute scaling: Automatically scales compute resources based on workload demand.
-
Strong data governance features: Centralized metadata, access controls, and lineage tracking.
Pros
-
Reduces data silos between analytics and data science
-
Strong performance on large, complex datasets
-
Open data architecture avoids proprietary lock-in
Cons
-
Higher learning curve for teams unfamiliar with Spark
-
Overkill for simple BI-only use cases
Pricing
Databricks uses pay-as-you-go pricing based on Databricks Units (DBUs), charging per second for workloads, with optional committed-use contracts that provide discounts and flexible usage across multiple cloud providers
Best for
Organizations that want a unified platform for analytics, data engineering, and machine learning using a lakehouse approach.
Ratings
What it can improve
The platform promises abstraction, but when something breaks, that abstraction disappears and exposes raw cloud infrastructure complexity underneath.
A recurring pain point is that Databricks often fails silently at the SQL warehouse layer. Instead of clear, actionable diagnostics, users are left inferring problems from generic startup delays or vague AWS API messages.
For newcomers evaluating Databricks as a cloud data warehouse solution, this creates an early impression that the system is powerful but unforgiving. You do not just learn SQL. You also learn networking, IAM policies, and cloud account hygiene, whether you planned to or not.
None of these questions addresses Databricks’ strengths at scale. But these experiences highlight where it can improve. Smoother onboarding, clearer error messaging, and more transparent defaults would go a long way toward making Databricks feel less like a platform you have to fight before you can use it.
5. Microsoft Azure Synapse Analytics
Azure Synapse Analytics is Microsoft’s integrated analytics service that combines enterprise data warehousing and big data analytics. It supports querying both structured warehouse data and large-scale data lakes from a single environment.
Synapse is often selected by enterprises already using Microsoft Azure and Power BI, particularly those managing hybrid or enterprise-scale analytics environments.
Key features
-
On-demand and provisioned analytics: Supports serverless SQL queries and dedicated SQL pools for predictable workloads.
-
Deep Microsoft ecosystem integration: Works seamlessly with Power BI, Azure Data Factory, and Azure Active Directory.
-
Unified analytics workspace: Enables querying data lakes and warehouses from a single interface.
-
Enterprise security and compliance: Built-in identity management, encryption, and auditing aligned with Azure standards.
-
Scalable global deployments: Supports multi-region architectures for resilience and data locality.
Pros
-
Strong fit for Microsoft-centric organizations
-
Flexible analytics across lakes and warehouses
-
Mature enterprise security capabilities
Cons
-
Can be complex to configure optimally
-
Performance tuning may require expertise
Pricing
Azure pricing follows a consumption-based model, letting customers pay only for used resources, with free trials, pricing calculators, and savings through reservations, savings plans, hybrid benefits, and cost management tools
Best for
Enterprises operating on Azure that need integrated analytics across data lakes and warehouses.
Ratings
What it can improve
For teams that push Azure Synapse beyond simple data ingestion, frustration tends to build quickly and loudly. Users say Synapse looks promising on paper, ticks all the enterprise boxes, and is often chosen by default in Azure-heavy organizations.
But once real pipelines grow in size or complexity, cracks start showing fast.
What users repeatedly run into isn’t one big failure, but death by a thousand paper cuts. Every day development tasks, things engineers take for granted, suddenly feel harder than they should.
Basic control flow is limited. Reusability is awkward. Refactoring is manual and error-prone. Even something as simple as version control feels bolted on rather than designed in. Instead of writing clean, modular pipelines, teams end up copy-pasting logic and managing workarounds.
Synapse Pipelines works reasonably well as a lightweight orchestrator for simple extract-and-load jobs, but falls apart when asked to handle serious transformation logic or large-scale workflows.
Teams exploring cloud data warehouse solutions often start with the same question: Which platform fits our needs without adding unnecessary complexity?
With multiple providers offering overlapping capabilities, clarity comes from understanding how leading solutions differ in architecture, deployment models, and ecosystem alignment.
Feature-by-feature comparison: what to evaluate when choosing a platform
Cloud data warehouse solutions may look similar on the surface, but their differences become clear when you examine how they handle scale, cost, governance, and integration.
A feature-by-feature evaluation helps cut through marketing claims and focus on what actually affects day-to-day usage.
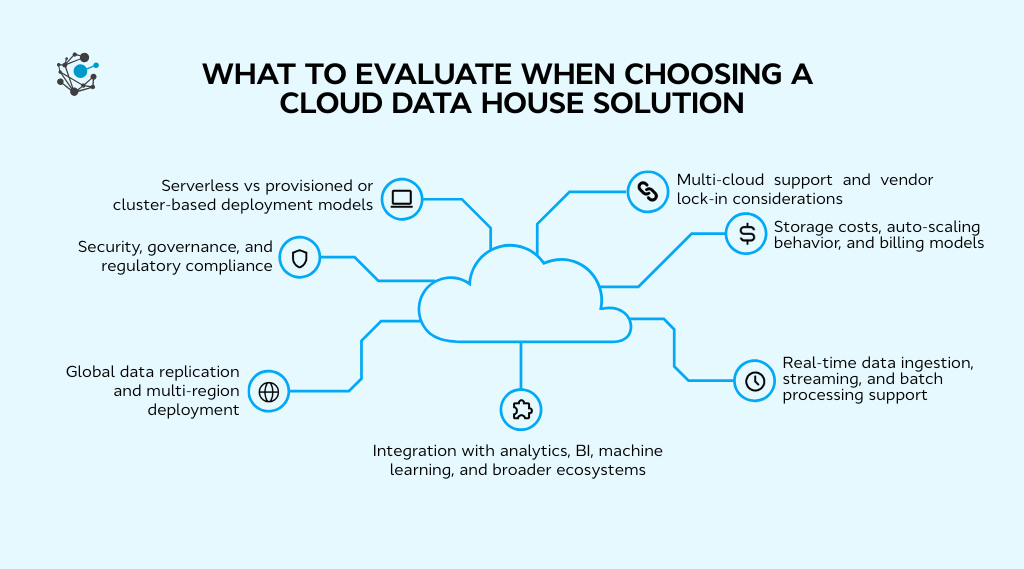
1. Serverless vs provisioned or cluster-based deployment models
One of the most consequential decisions when evaluating cloud data warehouse solutions is choosing between a serverless architecture and a provisioned or cluster-based model. This choice directly affects cost predictability, performance consistency, and operational overhead.
|
Serverless data warehouses, such as Google BigQuery, remove infrastructure management entirely. Teams submit queries, and the platform automatically allocates compute resources behind the scenes. This model works particularly well for organizations with variable or unpredictable workloads, such as ad hoc analytics, exploratory data analysis, or seasonal reporting spikes. |
There is no need to size clusters in advance, which eliminates a common pain point for teams migrating from on-prem systems.
Provisioned or cluster-based models, commonly associated with traditional Amazon Redshift deployments, require teams to define and manage compute capacity. While this introduces operational responsibility, it also provides tighter control over performance.
For workloads that run continuously or support mission-critical dashboards with strict response-time expectations, provisioned models can deliver more consistent results.
Some modern cloud data warehouse solutions, including Databricks and Azure Synapse Analytics, offer hybrid approaches. They allow organizations to mix serverless and provisioned resources depending on workload type.
This flexibility is useful for teams that run steady batch processing alongside bursty analytical queries.
The right deployment model depends on real usage patterns. Teams that overestimate predictability often overpay for idle capacity, while teams that underestimate variability can face unexpected performance issues or cost spikes.
2. Multi-cloud support and vendor lock-in considerations
Multi-cloud support has moved from a niche requirement to a strategic consideration for many enterprises evaluating cloud data warehouse solutions.
The ability to operate across multiple cloud providers can reduce dependency on a single vendor and provide flexibility in response to pricing changes, regulatory requirements, or corporate cloud strategies.
|
Platforms such as Snowflake and Databricks are designed to run across AWS, Azure, and Google Cloud with relatively consistent functionality. This allows organizations to standardize analytics practices while retaining the option to shift workloads or expand into new regions without rearchitecting their data stack. |
By contrast, cloud data warehouses that are tightly integrated with a single provider, such as Amazon Redshift on AWS, often deliver deeper native integrations and operational efficiencies within that ecosystem.
For organizations already committed to a single cloud, this tight coupling can simplify identity management, security configuration, and data movement.
Vendor lock-in is not inherently negative, but it becomes a risk when it is unintentional. Migrating large analytical datasets between platforms can be complex and costly, especially when proprietary features or data formats are involved.
Evaluating portability early helps organizations avoid being constrained by architectural decisions made during initial adoption.
3. Storage costs, auto-scaling behavior, and billing models
Cost management is one of the most common challenges associated with cloud data warehouse solutions. While pay-as-you-go pricing is often positioned as a benefit, it introduces new complexities compared to fixed-capacity on-prem systems.
Most modern platforms separate storage and compute costs. Storage typically scales automatically as data volumes grow, which eliminates capacity planning but also removes natural spending limits. Compute costs are driven by query execution, concurrency, and workload duration.
|
Platforms like BigQuery and Snowflake are frequently cited for transparent usage-based billing, but transparency alone does not guarantee cost control. |
A recurring issue for many teams is unoptimized query behavior. Broad table scans, inefficient joins, and unrestricted ad hoc access can quickly inflate costs in consumption-based models.
This is why FinOps practices have become closely linked to cloud data warehouse adoption. Monitoring usage, setting budgets, and educating users on cost-aware querying are now part of operating a modern analytics platform.
When comparing solutions, it is important to look beyond headline pricing and evaluate tooling for cost visibility, usage attribution, and workload governance. The best platforms make it easier to understand not just how much is being spent, but why.
4. Real-time data ingestion, streaming, and batch processing support
Analytics workloads today are rarely limited to overnight batch processing. Many organizations rely on near-real-time data to power dashboards, alerts, and operational decision-making.
As a result, support for both streaming and batch workloads has become a key evaluation criterion for cloud data warehouse solutions.
|
Platforms such as Google BigQuery and Azure Synapse Analytics support direct ingestion of streaming data, enabling organizations to analyze events as they arrive. This capability is particularly valuable for use cases such as monitoring application behavior, tracking user interactions, or responding to operational signals without delay. |
At the same time, batch processing remains essential for historical analysis, complex transformations, and data modeling. Amazon Redshift and Databricks are often favored for large-scale batch workloads due to their performance characteristics and integration with data engineering pipelines.
The challenge for many organizations is avoiding architectural fragmentation. Maintaining separate systems for streaming and batch analytics increases complexity and operational risk.
Leading cloud data warehouse solutions aim to support both patterns within a unified platform, allowing teams to choose the right processing mode without duplicating data or tooling.
5. Integration with analytics, BI, machine learning, and broader ecosystems
A cloud data warehouse rarely delivers value in isolation. Its effectiveness depends heavily on how well it integrates with analytics tools, BI platforms, data pipelines, and machine learning environments.
Strong BI integration is often a baseline requirement.
|
Platforms like Snowflake and Azure Synapse are widely used with tools such as Tableau and Power BI, enabling self-service reporting without extensive data movement. BigQuery’s close integration with Google’s analytics and AI services makes it appealing for organizations that want to combine traditional reporting with advanced analytics. |
Beyond BI, integration with data engineering and orchestration tools is equally important. ELT pipelines, reverse ETL workflows, and analytics engineering practices depend on reliable connectors and predictable behavior.
When evaluating platforms, it is important to consider not only current tools but also how well the warehouse fits into long-term data architecture plans.
6. Security, governance, and regulatory compliance
Security and governance are foundational requirements for enterprise cloud data warehouse solutions. As data volumes and user counts grow, unmanaged access and unclear data ownership can quickly undermine trust in analytics.
Most leading platforms support encryption at rest and in transit, role-based access control, and detailed audit logging. Compliance with regulations such as GDPR, HIPAA, and SOC 2 is now standard rather than exceptional.
According to Gartner's July 2025 forecast, global end-user spending on information security reached $213 billion in 2025, up from $193 billion in 2024, with spending projected to climb to $240 billion in 2026.
This surge highlights the heightened urgency among enterprises to fortify data environments and meet increasingly complex compliance obligations.
However, the practical effectiveness of these features varies. Governance capabilities such as metadata catalogs, data lineage, and policy enforcement play a critical role in maintaining data quality and accountability.
Choosing a platform with strong native data governance features reduces reliance on external tooling and lowers the risk of compliance gaps as analytics adoption scales.
7. Global data replication and multi-region deployment
For organizations operating across regions or serving global users, data locality and availability are essential considerations. Cloud data warehouse solutions increasingly offer built-in support for multi-region deployment and data replication.
|
Platforms like Snowflake provide mechanisms to replicate data across geographic regions, improving query performance for distributed teams and supporting disaster recovery scenarios. |
This capability also helps organizations meet data residency and sovereignty requirements, which are becoming more complex as regulations evolve.
Multi-region architectures reduce single points of failure and support business continuity planning. However, they also introduce considerations around consistency, cost, and governance.
Evaluating how a platform handles replication, failover, and access control across regions is critical for enterprises with a global footprint.
Viewed together, these features highlight where cloud data warehouse solutions diverge in meaningful ways. The right choice depends on how these capabilities align with your workloads, governance needs, and operational constraints rather than on any single feature in isolation
Conclusion
Without a data warehouse, data problems don’t stay small.
-
Reporting becomes slower and more manual.
-
Teams duplicate logic, metrics drift, and trust in numbers steadily declines.
-
Security gaps widen as data spreads across tools and personal extracts.
What starts as “just one more spreadsheet” eventually turns analytics into a constant cleanup exercise instead of a decision-making engine.
Data warehouse tools exist to stop that slide. They centralize analytical data, enforce consistent definitions, and make governance scalable instead of fragile. Access rules, lineage, and auditing are handled at the platform level, not patched together after issues appear.
Performance improves because data is modeled for analytics, not retrofitted from operational systems.
A well-chosen data warehouse turns analytics into shared infrastructure rather than tribal knowledge. When data is consistent, governed, and accessible, teams spend less time reconciling numbers and more time acting on them.
Struggling to govern data across multiple warehouses and tools?
OvalEdge connects with 150+ data sources and cloud warehouses to give you unified governance, lineage, and control.
See how OvalEdge helps you make any data warehouse easier to manage, without slowing teams down.
FAQs
1. Do cloud data warehouses support disaster recovery?
Yes. Leading platforms include built-in backup, replication, and recovery features. These capabilities help ensure data availability and business continuity without requiring custom infrastructure or manual failover processes.
2. What role does SQL play in cloud data warehouse solutions?
SQL is the primary interface for querying and analyzing data in cloud data warehouses. It enables analysts and business users to access data without deep engineering knowledge, supporting reporting, dashboards, and ad hoc analysis.
3. What types of data can be stored in a cloud data warehouse?
Cloud data warehouses store structured data and commonly support semi-structured formats such as JSON and logs. This flexibility allows analytics teams to work with application data, events, and operational records in one system.
4. What happens if cloud data warehouse usage spikes unexpectedly?
Most platforms automatically scale compute resources to handle increased demand. While this prevents performance issues, usage spikes can increase costs, making monitoring and query governance important for long-term cost control.
5. How long does it take to implement a cloud data warehouse?
Implementation time varies by data complexity and migration scope. Many organizations begin querying data within weeks, especially when starting with limited datasets and expanding incrementally rather than migrating everything at once.
6. Do cloud data warehouses support disaster recovery?
Yes. Leading platforms include built-in backup, replication, and recovery features. These capabilities help ensure data availability and business continuity without requiring custom infrastructure or manual failover processes.
7. What are the best cloud data warehouses used in modern data architecture?
The most widely adopted platforms in 2026 are Snowflake, Google BigQuery, Amazon Redshift, Databricks SQL Warehouse, and Azure Synapse Analytics. The right choice depends on your cloud provider, workload type, and governance requirements. Multi-cloud teams typically favor Snowflake or Databricks; AWS-native organizations often default to Redshift.
8. Cloud data warehouse vs data lakehouse: which should I choose?
Choose a data warehouse for governed, SQL-based BI and reporting where consistency matters most. Choose a lakehouse if your team runs ML workflows alongside SQL or needs to store raw unmodeled data. Many enterprises run both: a lakehouse for ingestion and data science, a warehouse for governed BI consumption

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)