
.png)
AI data management is a comprehensive approach that uses artificial intelligence technologies to automate, optimize, and improve data management processes. Its core objective is to handle both structured and unstructured data more effectively, boosting efficiency, security, and compliance, while minimizing human error. AI assists in various tasks like data discovery, cleaning, classification, and governance, making it easier for organizations to process vast amounts of data quickly and accurately. The ultimate goal is to ensure real-time data processing, provide actionable insights, and streamline workflows to support smarter decision-making.
AI data management is the use of AI and machine learning to automate how enterprise data is organized, cleaned, classified, governed, and monitored across its lifecycle. It helps data teams manage growing data volume without scaling effort linearly.
The reason this matters in 2026 is simple: most AI projects fail in production because the underlying data is incomplete, inconsistent, or untrusted, not because the model is wrong.
According to Gartner’s 2024 governance survey, 60% of organizations will fail to realize the value of their AI use cases by 2027 due to incohesive data governance frameworks. The bottleneck has shifted from models to data.
This guide covers four things: what AI data management actually is, how it differs from data management for AI workloads, the four core components required, and a five-step rollout strategy. It also breaks down the key challenges that derail most implementations.
What is AI data management?
AI data management is the practice of using artificial intelligence and machine learning within the data management lifecycle to automate how data is discovered, classified, cleaned, governed, and monitored.
Instead of relying only on manual rules and documentation, AI systems learn patterns in data to automate tasks such as tagging sensitive fields, detecting anomalies, mapping relationships, and enforcing policies. This helps organizations maintain accurate, usable, and compliant data as volume and complexity increase.
AI for data management vs data management for AI: what’s the difference?
These terms sound similar but solve different problems. The distinction matters when selecting tools and defining ownership.
|
Question |
AI for data management |
Data management for AI |
|
What it solves |
Uses AI/ML to automate data tasks such as discovery, quality, lineage, and governance |
Prepares and serves data so AI/ML models can train and run |
|
Who owns it |
Data engineering, governance, and platform teams |
ML engineering and MLOps teams |
|
Typical tools |
Data catalogs, observability platforms, and AI-driven governance tools |
Feature stores, vector databases, model registries |
|
Primary outcome |
Trusted, governed, well-described data assets |
Clean, labeled, high-performance training and inference data |
|
Example workflow |
Auto-tagging PII across thousands of tables |
Building a feature store for a churn prediction model |
This guide focuses on AI for data management. We also cover overlaps with data management for AI, where relevant, especially in the components section. (AI metadata is the underlying capability that makes both work.)
Core components of AI data management
As organizations deal with increasing data volumes, AI enables the scalable management of both structured and unstructured data.
Below are the core components of AI data management at a glance that make it a game-changer for businesses across industries.
|
Component |
What AI does here |
Why it matters |
|
Data discovery & metadata |
Scans, classifies, and tags data across cloud and on-prem sources |
Teams can find and trust data without manual cataloging delays |
|
Data quality, cleaning & anomaly detection |
Detects duplicates, missing values, format drift, and anomalies in real time |
Prevents decisions and AI models from running on unreliable data |
|
Classification, lineage & governance |
Identifies sensitive data, builds lineage graphs, and enforces access policies |
Ensures continuous compliance and audit readiness |
|
Lifecycle automation |
Automates ingestion, storage tiering, and archival based on usage and policy |
Reduces storage cost while keeping critical data accessible |
The sections below break down how each component works and where it adds value.
1. Data discovery & metadata generation
Data discovery involves identifying, cataloging, and classifying data from a wide range of sources across cloud environments, on-premise databases, and hybrid infrastructures. While traditional data discovery relies heavily on manual tagging and categorization, AI accelerates this process by automatically generating rich metadata (key information that helps users understand the content and context of their data).
AI systems do this by scanning datasets for meaningful characteristics such as data type, business relevance, usage frequency, and relationships to other data points.
| For a deeper look at how the catalog itself becomes AI-aware, see our guide on AI data catalogs. |
According to McKinsey’s 2024 Survey on Master Data Management, 80% of responding organizations report that some of their divisions still operate in silos, each with its own data management practices, source systems, and consumption behaviors. This fragmentation can create significant challenges in data discovery, making it difficult to access and integrate data across the organization.
By automating metadata generation, AI eliminates time-consuming manual work and improves the comprehensiveness and accuracy of data inventories.
This makes it easier for teams to quickly access and understand the data they need, without relying on complex or outdated documentation systems.
|
For example, an enterprise OvalEdge customer in healthcare uses AI-driven discovery to auto-classify PHI columns as soon as a new data source is connected. Before this, data stewards manually tagged each column, creating a backlog that took months to clear. With AI handling the first pass and stewards reviewing flagged exceptions, classification now stays current within days of new data going live, and access controls inherit directly from those classifications. |
2. Data quality, cleaning, & anomaly detection
One of the most persistent challenges in data management is ensuring the accuracy, consistency, and cleanliness of data. Poor data quality can lead to faulty analytics, incorrect business decisions, and even compliance violations.
According to Forrester Research’s Data Culture & Literacy Survey 2023, over 25% of global data and analytics professionals report that poor data quality is a significant barrier, estimating that their organizations lose more than $5 million annually as a result. These figures underscore the critical need for effective data quality management.
AI helps overcome this by leveraging machine learning models that continuously clean and monitor data in real time.
AI systems can identify and correct common data quality issues, such as duplicate entries, missing values, and formatting inconsistencies, often before these issues impact downstream processes.
Also Read: See our deep dive on AI data cleaning for the techniques that work in production.)
|
For example, in customer data management, AI can detect when two different records belong to the same customer (i.e., a duplicate), or if a critical customer detail like an email address is missing. AI can automatically standardize data formatting, such as converting all dates to a consistent format, and remove redundant data entries, ensuring that the dataset is accurate and streamlined. |
Beyond these improvements, AI also plays a crucial role in anomaly detection. Data anomalies are irregularities that may indicate errors, fraudulent activity, or changing trends in data patterns.
Traditional methods of anomaly detection are reactive, meaning they only flag issues once they have already disrupted processes. AI-driven anomaly detection is proactive. It can continuously monitor data as it flows through systems, identifying unusual patterns or shifts in real-time.
|
For instance, if an AI system notices that sales numbers have drastically declined in a particular region, it can flag this as a potential issue and trigger a review before any significant business impact occurs. |
In highly regulated industries, such as healthcare or finance, AI-powered anomaly detection is vital for ensuring compliance with regulations.
|
For example, it can help detect discrepancies in financial transactions or unusual access to sensitive patient data, which could indicate potential breaches. |
3. Data classification, lineage, & governance
Data classification refers to the categorization of data based on its sensitivity, value, and usage. AI plays a crucial role in automating the classification process, which is particularly important for organizations managing large volumes of sensitive data.
|
For instance, personal data, credit card details, or confidential business strategies all need to be classified and protected differently. |
AI systems use natural language processing (NLP) and machine learning algorithms to assess the context and sensitivity of data. They can identify personally identifiable information (PII), intellectual property, and other protected categories of data.
By automatically tagging this data, AI ensures that appropriate access controls are enforced based on its classification. This reduces the burden on IT and security teams and helps businesses comply with data privacy laws like GDPR or CCPA.
Data lineage tracks the flow and transformations of data as it moves through systems, from ingestion through every join, transformation, and consumption point. AI-driven lineage tools build these graphs automatically by parsing query logs, ETL definitions, and BI metadata, and keep them updated as systems change.
This is where AI data management shifts from a useful capability to a requirement. Without lineage, teams cannot answer a GDPR data access request, validate financial calculations under BCBS 239, or trace where training data for a model originated.
Most tools treat lineage as a secondary feature. In practice, it connects discovery, quality, and governance. Without it, those components operate without context. When evaluating platforms, the real test is simple: can you trace where a data point came from, how it changed, and who is using it today? If not, the system will struggle under audit and compliance pressure.
|
For example, if a healthcare organization needs to demonstrate how patient data is being used across different departments, AI-powered lineage tracking can provide a clear, real-time map of this data flow, improving transparency and auditability. |
Governance is an essential aspect of data management, particularly in industries where data privacy and compliance are critical. AI tools assist by automating compliance checks and ensuring that data governance policies are consistently followed.
|
For example, in an organization with vast amounts of customer data, AI can automatically enforce rules on who has access to specific data based on roles or compliance requirements. This reduces the risk of human error and enhances overall governance processes. |
4. Data lifecycle & automation of ingestion to archiving
AI significantly enhances the management of the data lifecycle, spanning from the initial ingestion of data to its eventual archiving or deletion. This process, when automated with AI, ensures that data is stored efficiently, easily accessible when needed, and appropriately archived when it becomes inactive.
AI helps businesses streamline and automate the entire data ingestion process. Data coming from various sources (e.g., external APIs, IoT devices, transactional systems) can be ingested automatically, processed, and stored in the appropriate systems.
|
For example, AI can analyze incoming data to determine its structure, format, and relevance, ensuring it is routed to the correct storage location (whether on-premise or cloud) with minimal human intervention. |
One of the key benefits of AI in data lifecycle management is storage tiering. Data that is frequently accessed (such as active customer records) can be kept in high-performance storage systems for fast access, while less frequently used data (e.g., historical transaction records) can be moved to cost-effective, lower-performance storage.
AI can automate these decisions by analyzing usage patterns and establishing rules for when data should be moved to a different storage tier. This ensures that businesses can manage their data at scale while keeping costs under control.
Moreover, when data becomes obsolete or outdated, AI can trigger automated archiving processes. For the full lifecycle picture from ingestion through retirement, see our guide on data lifecycle management.
|
For example, financial data that no longer meets compliance requirements or has reached its retention limit can be archived or purged in a manner that meets legal and regulatory standards. This automation reduces manual oversight and ensures that data management processes are always compliant and cost-effective. |
With AI-driven automation and intelligence, organizations not only improve their data management efficiency but also reduce operational costs, increase data accessibility, and ensure compliance with ever-evolving regulations.
The potential for AI to streamline data processes across the entire lifecycle, from ingestion to archiving, means that businesses can focus more on strategic decision-making and less on data maintenance, ultimately gaining a competitive edge in their respective industries.
What infrastructure does AI data management need?
AI data management runs on top of three core infrastructure layers, and the platform you choose needs to work across all of them:
-
Storage and compute layer: This includes cloud data warehouses such as Snowflake, BigQuery, Redshift, and Databricks, along with data lakes on object storage like S3, ADLS, and GCS, and operational databases. AI tools need metadata-level access across these systems, not just a single source.
-
Metadata and catalog layer: This is the system of record for what data exists, what it means, who owns it, and how it is used. Most AI capabilities in data management depend on this layer. Without a catalog as the foundation, AI tools can't reason about the data they're being asked to manage.
-
Pipeline and orchestration layer: This includes tools such as Airflow, dbt, Fivetran, and custom pipelines. AI lineage tools sit on top of this layer, parsing job definitions and run logs to build lineage in real time.
The most common mistake is adopting AI tools before establishing a strong metadata layer. Without it, the system has no reliable context to learn from. A working AI data management stack starts with a unified, queryable metadata foundation, typically a data catalog, and then layers AI capabilities on top.
AI data management strategy: the 5-step rollout framework
Adopting AI for data management works best with a structured approach that connects data readiness, governance, and measurable outcomes. Without that alignment, even advanced AI tools struggle to deliver value.
This 5-step rollout framework shows how to move from fragmented data to AI-driven data management in a controlled and scalable way.
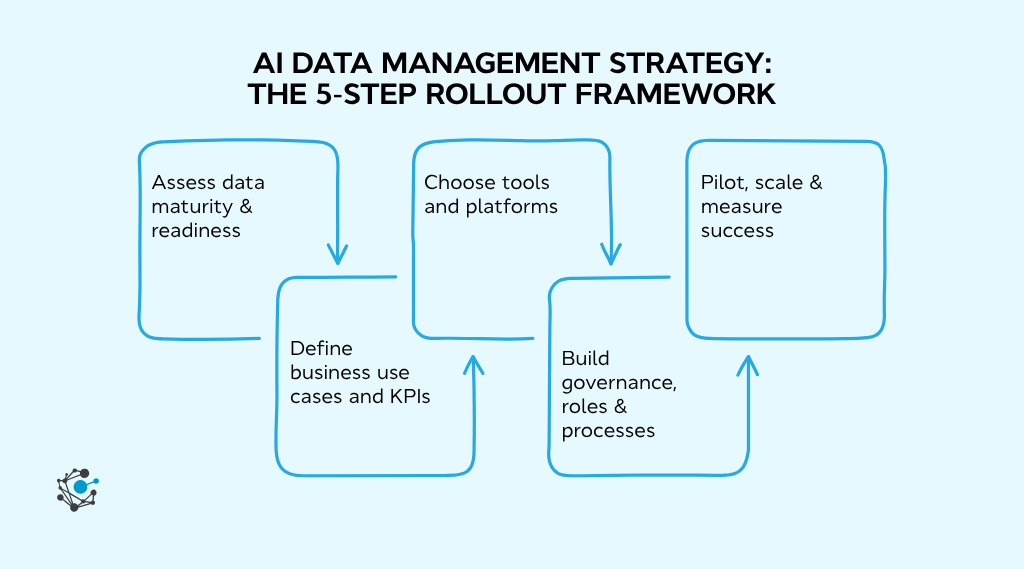
Step 1: Assess data maturity & readiness
Before diving into the implementation of AI data management, it's crucial to assess your organization’s data maturity. This is a foundational step, as it allows businesses to understand where they currently stand in terms of data governance, data infrastructure, and analytics capabilities.
A clear understanding of data maturity helps organizations set realistic expectations, identify gaps, and establish a roadmap for success.
What does a data maturity assessment involve?
-
Data infrastructure evaluation: Assess your current systems, whether cloud-based, on-premise, or hybrid.
-
Are your data storage and processing systems capable of handling AI-driven workflows?
-
AI requires high-quality, structured data, and an infrastructure that can support fast data processing.
-
Metadata standards: Metadata is the backbone of AI systems. AI-driven tools need accurate, standardized metadata to make sense of data. You should evaluate how well metadata is currently being generated, stored, and used.
|
For example, if metadata is incomplete or inaccurate, AI algorithms will struggle to find patterns or automate processes effectively. |
-
Data governance practices: Governance is critical, especially when dealing with AI. Your existing governance structure should align with AI-driven approaches. This includes ensuring that data privacy, security, and ethical considerations are incorporated at the outset.
AI can help automate compliance checks, but governance protocols must be in place to ensure the technology adheres to regulations such as GDPR, HIPAA, or CCPA.
-
Automation readiness: Evaluate the level of automation your organization is comfortable with. Some businesses may need a phased approach, starting with automation in specific areas like data cleaning or reporting.
For others, fully automated AI solutions might be the goal from the start. The readiness for AI automation will depend on the organization's current workflow and the complexity of the tasks to be automated.
|
A large healthcare provider looking to implement AI might first assess its data infrastructure, which includes Electronic Health Records (EHR) systems, patient data privacy standards, and the speed at which data is transferred across departments. By understanding its data maturity, the organization can prioritize AI initiatives, such as improving data quality for predictive analytics or enhancing the automation of patient billing processes. |
Step 2: Define business use cases and KPIs
AI is a versatile tool, but to achieve tangible benefits, it’s crucial to focus on areas that have a clear return on investment (ROI). Use cases should align with business priorities and address specific pain points. These could range from improving data accuracy to enhancing compliance reporting or accelerating decision-making.
Choosing the right use cases:
-
Compliance automation: For industries like finance and healthcare, AI can be used to automate compliance-related tasks, such as monitoring transactions for fraud or ensuring that healthcare records comply with privacy regulations.
-
Data quality improvement: AI can continuously monitor data pipelines for inconsistencies, missing values, or data anomalies, ensuring the quality of data used for decision-making and analytics.
-
Analytics and decision support: AI can enable more efficient data analysis, allowing for faster insights.
|
For example, AI can be used to generate real-time business intelligence dashboards, which can significantly improve decision-making speed in fast-paced industries like e-commerce or telecommunications. |
Once the use cases are defined, it's essential to establish measurable KPIs to track the success of AI implementation. KPIs could include:
-
Reduction in data errors: For example, tracking how AI’s automated data cleaning impacts the number of data quality issues.
-
Faster time to insights: For use cases around business intelligence, measuring how AI accelerates the speed at which insights are generated from raw data.
-
Cost savings: AI can reduce operational costs by automating repetitive tasks. Measuring cost reduction in areas such as manual data cleaning or report generation will help demonstrate ROI.
|
For example, a manufacturing company looking to enhance its predictive maintenance system might define KPIs such as the reduction in machine downtime, cost savings from optimized maintenance schedules, and improvement in data quality for predictive models. |
Step 3: Choose tools and platforms
The choice of AI tools and platforms is critical to the success of the data management strategy. Many AI-driven data management tools are available, but selecting the right platform involves more than just picking the most popular solution.
You need to consider your organization’s specific requirements, such as scalability, ease of integration, and AI-native features.
Key factors to consider when selecting tools:
-
Scalability: Choose platforms that can grow with your business. As data volumes increase, AI systems should be able to scale to handle more data and more complex processes. Cloud-based platforms are often preferred for their ability to scale on demand.
-
Integration with existing systems: Many organizations already have complex data ecosystems, so it's important that new AI tools can integrate seamlessly with existing systems, whether they are legacy systems or cloud-based platforms. Look for tools that offer flexible integration options, such as APIs or pre-built connectors.
-
AI-Native features: Not all data management platforms are built with AI in mind. Ensure that the platform you choose includes AI-powered features, such as automated data cleaning, anomaly detection, and predictive analytics.
-
Governance and Security: Security and data governance must be built into the platform. Since data privacy is a major concern, especially for businesses in healthcare, finance, and e-commerce, ensure that your platform supports strong governance models, like role-based access control (RBAC), audit trails, and compliance management.
|
For example, a retail business looking to personalize customer recommendations might opt for an AI-driven platform with built-in machine learning algorithms that can integrate with its existing CRM system, ensuring that the AI can access and process customer data without disrupting current workflows. |
Step 4: Build governance, roles & processes
Effective data governance is essential in any AI-driven data management strategy. AI systems often work autonomously, but governance ensures they operate within the boundaries set by business policies, ethical guidelines, and regulatory requirements.
Establishing clear governance processes and roles will provide transparency and accountability for AI systems.
Critical components of data governance include:
-
Data ownership and stewardship: Clearly define who owns and is responsible for data across the organization.
|
For example, data stewards should be designated to ensure the quality, accessibility, and accuracy of data in their respective domains. |
-
Approval workflows: Establish workflows that define how data is accessed, used, and approved for various tasks. This ensures that only authorized personnel can make decisions based on sensitive data.
-
Compliance and ethical standards: AI tools must adhere to regulatory requirements like GDPR, HIPAA, and CCPA. Governance frameworks should automate compliance checks to ensure AI-driven processes respect privacy laws and data protection standards. For a fuller framework, see our AI data governance guide.
-
Transparency and accountability: Especially when using AI to make automated decisions, it is important to ensure that those decisions are explainable and auditable. This is particularly critical in sectors such as finance or healthcare, where AI decisions need to be explainable to both regulators and stakeholders.
Step 5: Pilot, scale & measure success
A pilot project provides valuable insights into how AI will perform in real-world conditions and allows organizations to test the new processes without full-scale deployment.
Key actions during the pilot phase:
-
Define success metrics: Prior to the pilot, establish clear metrics for success.
|
For example, if the goal is to automate data cleaning, measure the reduction in manual data cleaning time and the improvement in data accuracy. |
-
Stakeholder alignment: Engage stakeholders early in the pilot phase. This ensures that there is alignment across departments on the expected outcomes and the methodology used to evaluate success.
-
Refinement: After evaluating the pilot results, refine the AI models, governance processes, and workflows. It's crucial to address any shortcomings discovered during the pilot phase before scaling across the organization.
Once the pilot proves successful, the next step is to scale the AI implementation. Scaling should be done in stages, gradually expanding to other departments, data sources, and use cases, ensuring that the processes can be repeated and refined along the way.
This structured approach to AI data management enables businesses to make data-driven decisions faster, reduce operational costs, and position themselves as leaders in their industries.
Challenges with AI data management
AI data management improves scale and efficiency, but it also introduces challenges that need to be addressed early. Most issues do not come from the AI itself, but from gaps in data visibility, governance, and system integration.
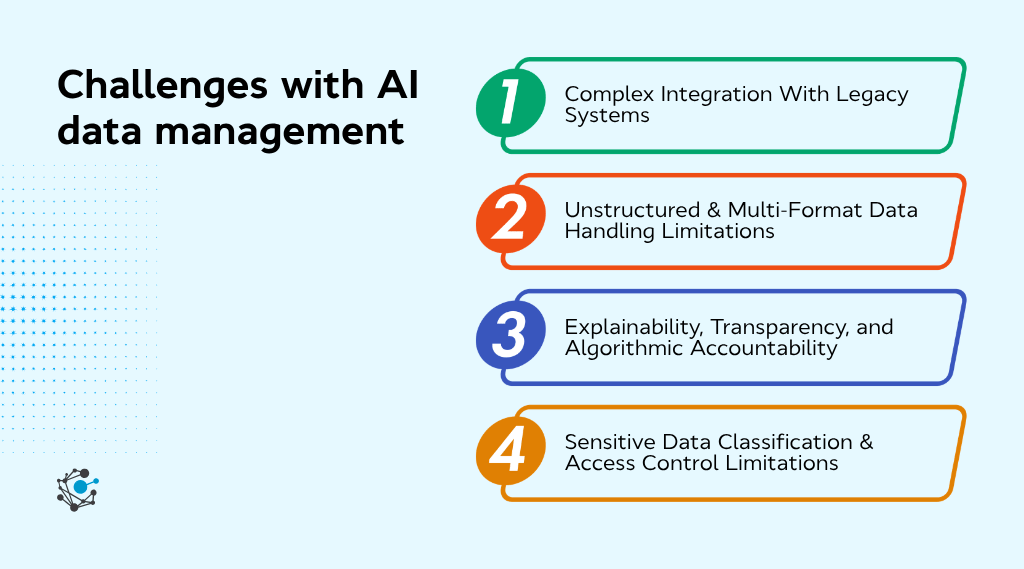
1. Complex integration with legacy systems
Many organizations still rely on legacy systems that were not built for AI-driven workflows. These systems often store data in outdated formats, lack modern interfaces, and cannot support real-time data access.
The challenge is not just integration. It is maintaining consistency and trust as data moves between old and new systems. Without clear visibility into how data flows, integration efforts can introduce inconsistencies or break downstream processes.
A phased approach works best. Instead of replacing legacy systems immediately, teams can connect them through pipelines and gradually move critical data into modern platforms.
This is where data lineage becomes essential. Without lineage, teams cannot track how data moves from legacy systems into modern environments or identify where errors are introduced. Lineage provides the context needed to integrate safely and validate outcomes during migration.
|
For example, a financial institution migrating data from a legacy mainframe to a cloud warehouse may find discrepancies in reporting numbers. Without lineage, teams cannot trace where transformations introduced errors. With lineage in place, they can quickly identify the exact step where the data changed and validate the fix before it impacts downstream reporting. |
2. Unstructured & multi-format data handling limitations
Most enterprise data is not structured. It exists in documents, emails, images, audio, and logs. While AI can process these formats, the challenge is standardizing them into a form that can be governed and reused.
Different formats require different processing methods. Text may need NLP. Images require recognition models. Audio needs transcription. Without a consistent way to describe and organize this data, it remains difficult to use at scale.
The key is not just processing unstructured data, but making it discoverable and governed. This is where a data catalog with strong metadata support plays a central role. It provides a unified layer where structured and unstructured data can be indexed, classified, and made accessible.
Without that layer, unstructured data remains fragmented, even if it is technically processed by AI models.
|
For example, a support team analyzing customer feedback across emails, chat logs, and call transcripts may struggle to unify insights. Without a metadata layer to standardize and classify this data, each format remains siloed. A data catalog helps index and tag these inputs, making them searchable and usable across teams. |
3. Explainability, transparency, and algorithmic accountability
AI systems often operate in ways that are not immediately visible to users. When an AI model flags an anomaly, classifies data, or enforces a rule, teams need to understand why.
Explainability methods such as LIME and SHAP help interpret model outputs, but they do not solve the full problem. The bigger challenge is connecting AI decisions back to the underlying data.
|
For example, if a data quality issue is flagged, teams need to trace:
|
This is where lineage and metadata together enable explainability. Instead of treating AI as a black box, organizations can trace decisions back to source data and transformations.
In practice, explainability in data management is less about model interpretation and more about data traceability. Without lineage, explanations remain incomplete.
4. Sensitive data classification & access control limitations
Sensitive data classification is critical in industries handling personal or regulated information such as finance, healthcare, and legal services. While AI can automate classification at scale, errors in tagging or incomplete coverage can still create compliance risks.
The challenge is not just identifying sensitive data, but ensuring that classification remains accurate and consistently enforced over time.
This requires:
-
Governance policies that define access rules
-
Role-based access control (RBAC) to enforce permissions
-
Audit trails to track data usage and changes
Automated data governance workflows are how this is enforced at scale, without a steward in the loop for every access request.
Without these controls, classification becomes a one-time activity instead of a continuous process. Sensitive data may be exposed if classifications are incorrect or not updated as data evolves.
|
For example, if an AI system misclassifies a column containing customer email addresses as non-sensitive, it may become accessible across teams. Without governance controls such as RBAC and audit trails, this can expose personal data unintentionally. With classification tied to access policies, permissions update automatically when sensitivity changes, reducing the risk of unauthorized access. |
Conclusion
AI data management is no longer about improving isolated processes. It is about building a system where data is continuously discovered, trusted, governed, and usable across the organization. Without that foundation, AI initiatives struggle to scale, and decision-making slows down despite increased data availability.
Most organizations today are not limited by tools. They are limited by fragmented data, missing metadata, and weak governance. This is why success with AI data management depends less on the model and more on how well data is managed across its lifecycle.
If you're earlier in the journey, start by mapping your current state. Do you have a clear inventory of where your data lives, who owns it, and how it flows across systems? If not, a data catalog becomes the starting point. AI tools cannot compensate for missing structure or context.
If you already have that foundation and are ready to layer AI on top, the focus shifts to automation and scale. This is where AI-driven discovery, automated lineage, and policy-based governance start to deliver real value across teams.
OvalEdge brings these capabilities together in a single platform, helping teams move from fragmented data environments to governed, AI-ready systems without long implementation cycles.
Book a 30-minute walkthrough to see what your first 90 days could look like.
FAQs
1. What is the difference between AI data management and traditional data management?
Traditional data management is rules-based and reactive, relying on predefined checks. AI data management is pattern-based and proactive, using machine learning to detect anomalies and generate metadata continuously. The key difference is scale: traditional approaches grow linearly, while AI-driven systems automate high-volume tasks and improve efficiency.
2. What are the types of AI data management?
AI data management includes predictive analytics, data integration, data governance, and anomaly detection. Each type focuses on automating and optimizing specific aspects of data workflows, ensuring real-time processing, high data quality, and compliance with regulations.
3. What are the key pillars of AI data management?
The main pillars of AI data management are automation, scalability, data quality, governance, and integration. These pillars enable businesses to streamline data processes, improve decision-making, and ensure secure, compliant data management across platforms.
4. What is the role of cloud-based AI in data management?
Cloud-based AI platforms enable scalable, cost-effective data management by offering flexibility and on-demand resources. These platforms allow businesses to store, process, and analyze large datasets without the constraints of on-premise infrastructure, ensuring that AI models can scale as data volumes grow.
5. How can AI help with data integration across systems?
AI simplifies data integration by automating the process of mapping and merging data from different sources, including on-premise systems, cloud storage, and third-party platforms. This allows businesses to create a unified data environment, making it easier to access and analyze comprehensive data.
6. How do AI models predict data trends in data management?
AI models predict data trends by analyzing historical data and identifying patterns and correlations. Machine learning algorithms then use these insights to forecast future trends, enabling businesses to proactively adjust their strategies and operations based on data-driven predictions.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)