
-1.png)
Active metadata replaces static, manual passive metadata with dynamic, real-time intelligence that reflects how data changes, moves, and is used. By syncing metadata across systems, capturing usage patterns, and automating enrichment, it strengthens discovery, governance, and decision-making. Effective adoption involves strategic planning, platform selection, contextual enrichment, workflow integration, and continuous monitoring to ensure accuracy and business alignment.
Active metadata is metadata that updates itself in real time, capturing how data is used, moved, and changed across systems. That matters because modern data does not sit still. It moves through cloud warehouses, BI tools, pipelines, AI models, and governance workflows every day.
Metadata defines structure, context, and meaning across technical, business, and operational layers. For a quick primer, see the different types of metadata before comparing active and passive metadata.
Unlike passive metadata, which is usually updated by hand, active metadata pulls signals from every tool in the data stack and pushes useful context back into them.
According to 2024 Gartner predictions, by 2026, 30% of organizations will adopt active metadata practices, cutting time to delivery of new data assets by up to 70%.
This guide covers what active metadata is, how it differs from passive metadata, the seven steps to implement it, and where it fits inside a modern data governance program.
What is active metadata?
Active metadata is metadata that is continuously analyzed, curated, and used to drive automation across the data stack.
Where passive metadata sits inside a static catalog, active metadata moves both ways. It ingests signals from warehouses, BI tools, pipelines, governance systems, and user activity. It also pushes recommendations, alerts, and policy actions back into those tools when something changes.
Three things distinguish active metadata from older, descriptive metadata:
-
It updates automatically: Schema changes, new data sources, quality alerts, and ownership updates are reflected when they happen, not during the next manual review cycle.
-
It carries behavioral context: Active metadata captures who queried a dataset, which tables are used most often, which reports depend on a column, and where governance policies were applied.
-
It triggers action: A failed quality check can pause a pipeline. A new PII column can apply a masking rule. A heavily used dataset can be promoted as a certified asset. This turns the catalog from documentation into an operational system.
| For a foundational primer, see the difference between data and metadata, or jump to the active vs passive metadata table below. |
Active vs Passive metadata
Understanding the difference between active and passive metadata helps teams decide whether their current metadata practices are only documenting data or actively improving discovery, governance, and decision-making.
Here is a side-by-side comparison of how the two approaches differ. The sections below explain each row in detail.
|
Feature |
Passive metadata |
Active metadata |
|
Update frequency |
Periodic, manual updates |
Continuous, real-time updates |
|
Adaptability |
Static and does not reflect immediate changes |
Dynamic and reflects data changes immediately |
|
Automation |
Requires manual input for updates |
Automatically updated based on data interactions |
|
Data discovery |
Limited in providing up-to-date context for discovery |
Enhances data discovery by enriching metadata in real time |
|
Decision-making |
Delayed due to outdated metadata |
Facilitates faster, data-driven decisions |
|
Governance and compliance |
Limited in tracking data lineage |
Tracks real-time data lineage, ensuring compliance and governance |
Passive metadata
Passive metadata refers to the traditional form of metadata that is typically manually curated, stored, and updated on a scheduled or occasional basis. This type of metadata provides a snapshot of the data’s structure, content, and other characteristics at a specific point in time.
In essence, passive metadata is static and doesn’t react to changes in real-time. It’s like taking a picture of your data landscape, but it doesn't change as your data evolves.
One of the primary examples of passive metadata is a data catalog. In a typical data catalog, metadata might describe a dataset’s source, its schema, and its structure.
|
For example, passive metadata can tell you that a database contains customer information, lists the columns of the database, and provides basic data definitions like “customer name,” “address,” and “email.” However, this data will not update automatically when a new field is added to the database, when the structure changes, or when data is accessed or altered. |
While passive metadata serves as a useful reference and provides a certain level of documentation, it presents several key challenges:
1. Limited timeliness: Passive metadata cannot account for real-time changes in data or reflect the current state of datasets as they are altered, accessed, or used by different stakeholders. This delay can significantly hinder decision-making, especially in fast-moving environments where accurate, up-to-date data is critical.
2. Manual maintenance: Passive metadata relies heavily on manual updates and periodic audits, which means that as data structures evolve or new datasets are added, there’s a risk of outdated or incorrect metadata being used for important decisions. This manual intervention can be resource-intensive and prone to human error.
3. Missed insights: Passive metadata lacks the ability to capture usage patterns or behavioral signals.
|
For example, it cannot tell you if a particular dataset is frequently accessed by the marketing team or if certain fields are no longer relevant to ongoing projects. This makes it less effective for dynamic data discovery or optimizing data management practices. |
Despite its limitations, passive metadata still matters. It gives teams a foundation for definitions, ownership, lineage, and documentation. But as data ecosystems become more dynamic, passive metadata alone is not enough to support real-time governance and self-service analytics.
Active metadata
Active metadata, in contrast, refers to metadata that is continuously updated in real-time based on system interactions, data usage, and behavioral changes. It is dynamic, evolving, and integrated into the data ecosystem, constantly reflecting updates as data is accessed, modified, or moved across various systems.
Unlike passive metadata, active metadata is inherently designed to react to the changing nature of data, ensuring that the most relevant, contextual information is always available.
Active metadata is a “living” entity that grows and adapts as data changes. As soon as any system interaction occurs, whether data is queried, updated, or analyzed, the metadata is automatically updated to reflect these changes.
For instance, if a dataset undergoes a structural change (such as new columns or attributes being added), the metadata will instantly update to reflect these modifications.
The key advantage of active metadata lies in its ability to offer real-time insights that drive more informed decision-making. Because it continuously reflects changes in the data ecosystem, active metadata allows organizations to:
1. Make timely, data-driven decisions: Since the metadata is always up to date, business and data teams can make faster, more accurate decisions.
|
For instance, if a sales team notices a spike in interest for a particular product, active metadata can reveal which attributes (like category, description, or pricing) contributed to that spike. |
2. Facilitate data discovery and self-service analytics: Active metadata powers data discovery by enriching metadata with contextual, behavioral, and business-related insights. This allows data users to quickly identify relevant datasets based on specific usage patterns or business needs. As data is automatically categorized and contextualized, business users can perform more self-service analytics without waiting for IT teams to provide them with the necessary datasets.
3. Enhance data governance and compliance: With active metadata, organizations can track data lineage and monitor changes in real-time. This is crucial for compliance, as it ensures that all data usage and modifications are properly documented.
|
For instance, in industries like finance or healthcare, where data governance and regulatory compliance are paramount, active metadata allows organizations to ensure that data is used and maintained in accordance with regulatory requirements, without manual intervention. |
As businesses increasingly rely on data to drive decision-making, the ability to track and manage metadata in real-time is crucial.
Benefits of active metadata
Active metadata delivers value in five practical ways. It improves how quickly teams deliver trusted data, how easily they govern sensitive information, and how confidently business users find and use the right datasets.
-
Up to 70% faster delivery of new data assets: Gartner projects that organizations adopting active metadata practices can reduce time to delivery of new data assets by up to 70%. Real-time lineage, automated documentation, and current ownership context reduce the back-and-forth between data engineers, stewards, and business users.
-
40 to 50% time savings on compliance reporting: Active metadata helps automate the classification of PII, PHI, PCI, and other sensitive data. This reduces manual tagging effort and gives compliance teams audit trails they can use when they need to prove who accessed data, where it moved, and how it was governed.
-
15 to 30% reduction in storage and compute costs: Behavioral metadata shows which tables, reports, and datasets are unused, duplicated, or rarely accessed. Teams can use this context to archive stale assets, remove duplicate datasets, and reduce unnecessary cloud spend.
-
50 to 70% improvement in root cause analysis: Column-level lineage helps teams trace where a broken dashboard, failed metric, or data quality issue came from. Instead of spending days checking pipelines manually, teams can identify the affected source, transformation, or downstream report in minutes.
-
Stronger self-service analytics adoption: When metadata flows into BI tools such as Tableau, Looker, or Power BI, business users can see definitions, owners, freshness, lineage, and quality context without leaving their workflow. This makes them more likely to use trusted data independently.
These outcomes depend on three foundations: a unified metadata layer, bi-directional integration with the data stack, and clear governance over who can change, certify, or approve metadata. The next section breaks down the core characteristics that make active metadata work.
How active metadata works: Core characteristics
Active metadata works by continuously collecting, updating, and sharing context across the data stack. Instead of sitting in a static catalog, it captures signals from warehouses, BI tools, pipelines, governance systems, and user activity, then turns those signals into automated actions.
Four characteristics make active metadata different from traditional metadata: automated enrichment, bi-directional flow, behavioral context, and real-time governance.

1. Automated enrichment and updates
Active metadata automatically updates as data changes. When a new table is created, a schema change occurs, a column is added, or a data quality issue appears, the metadata layer reflects that change without waiting for manual review.
|
Consider a data-driven e-commerce company. When it adds new products to its catalog, active metadata can update related product categories, availability status, pricing fields, and ownership details across connected systems. If a new customer segment is added to a BI tool, that context can also flow into dashboards, analytics workflows, and machine learning models. |
This helps teams maintain:
-
Consistent metadata: Teams work with current definitions, ownership, and structure across systems.
-
Lower manual effort: Data stewards spend less time updating fields by hand.
-
Better data relevance: Analysts and business users see the current context before using a dataset.
2. Continuous bi-directional flow across the ecosystem
Active metadata not only pulls information into a catalog. It also pushes context back into the tools where people work.
|
A global retail chain uses several different platforms for its various operations: inventory management, sales tracking, customer relationship management (CRM), and marketing. If a CRM update creates a new customer segment, active metadata can sync that context with the data warehouse, marketing automation platform, and analytics dashboards. If a governance rule changes, that update can flow back into BI tools or access workflows. |
This bi-directional flow supports:
-
Cross-platform consistency: Updates in one system are reflected across connected tools.
-
Faster data access: Users do not need to switch tools to understand ownership, lineage, or freshness.
-
Stronger integration: Teams get a more unified view of data across warehouses, BI tools, catalogs, and governance systems.
3. Behavioral signals, usage patterns, and context
Active metadata tracks how data is actually used. It can show which datasets are queried most often, which users rely on specific tables, which reports depend on a column, and which assets are no longer used.
|
For example, a financial services firm may find that its fraud detection team repeatedly queries a specific transaction table while other related datasets receive little use. Active metadata can help the data team prioritize the high-value table, improve its documentation, certify it for trusted use, or archive unused assets. |
This helps teams improve:
-
Governance decisions: Access and policy controls can reflect actual usage patterns.
-
Data discovery: Frequently used and trusted datasets can be surfaced more prominently.
-
User experience: Business users get context based on how teams already work with data.
4. Governance, lineage & real-time insights
Active metadata strengthens governance by tracking how data moves from source to consumption. It records changes across transformations, pipelines, dashboards, and downstream systems, which gives teams a clearer view of lineage and impact.
|
Consider a healthcare organization that handles patient data. It can use active metadata to trace where sensitive health records originate, how they are transformed, who accesses them, and where they appear downstream. If a sensitive column is added or a data quality issue appears, the metadata layer can flag it quickly for review. |
Real-time insights allow organizations to monitor data usage, quality, and compliance as they occur, addressing issues before they affect reporting, access, or regulatory controls.
For a deeper look at column-level lineage and impact analysis, see these data lineage best practices.
This supports:
-
Compliance visibility: Teams can monitor sensitive data usage and maintain audit-ready records.
-
Data integrity: Real-time monitoring helps teams detect quality issues before they affect reports or decisions.
-
Risk management: Governance teams can identify access, lineage, and policy issues earlier.
As data ecosystems scale, these four characteristics turn metadata into an operational layer. They help teams understand what data means, how it changes, who uses it, and what action should happen next.
How to implement active metadata
Implementing active metadata requires careful planning, the right tools, and an ongoing commitment to ensuring the metadata is continuously updated and aligned with your business goals.
Whether you're just beginning to explore active metadata or looking to improve your existing practices, these steps will help you move from static documentation to real-time metadata operations.
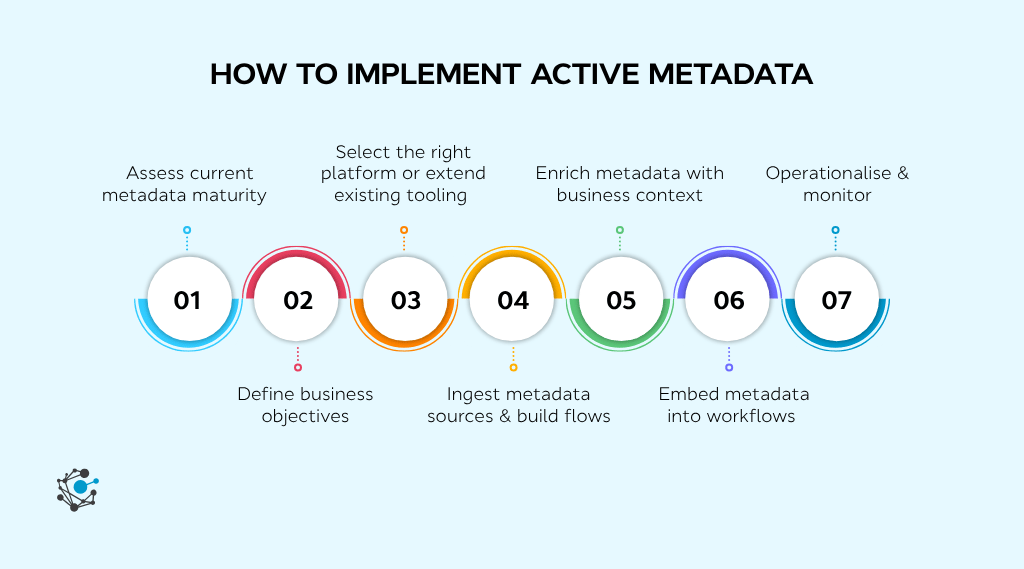
Step 1: Assess current metadata maturity
Assessing your metadata maturity will help identify the gaps in your current systems and determine where active metadata can provide the most value.
-
Are you using passive metadata? If so, it’s time to evaluate how frequently your metadata is updated and whether it’s reflective of the current state of your data.
-
Do you struggle with data discovery or governance? If metadata management is too static or siloed, active metadata could offer better ways to enhance real-time discovery and governance.
-
Is your data ecosystem fragmented? If your data exists in separate platforms (e.g., data warehouses, BI tools, CRMs), integrating active metadata can help unify it across systems.
|
A retail company using outdated passive metadata in its inventory system might struggle with keeping track of stock levels in real time. With active metadata, updates to inventory levels or product categories would automatically reflect across the system, enabling better operational decision-making. |
Step 2: Define business objectives
Aligning your active metadata strategy with specific business objectives ensures that your efforts support organizational goals. Enterprise metadata management strategy walks through how to set those objectives at scale. Whether you’re aiming to improve data quality, support automation, or facilitate decision-making, knowing what you want to achieve will guide your strategy.
-
What specific problems are you trying to solve?
-
Are you trying to make data more accessible for business teams?
-
Are you aiming to improve compliance? Or
-
Are you focused on automating metadata updates for efficiency?
-
How will active metadata improve business outcomes? For example, will better data governance help your compliance team? Will enriched metadata improve your marketing team’s targeting accuracy?
|
For a financial services firm, active metadata could be used to track the lineage of sensitive financial data in real-time, ensuring compliance with industry regulations. The business goal here would be to reduce risk by enhancing visibility into data flows. |
Step 3: Select the right platform or extend existing tooling
Choosing the right platform decides whether active metadata becomes a real operational layer or another catalog that teams rarely use. Most teams either extend an existing metadata tool with active capabilities or choose a purpose-built platform such as OvalEdge, Atlan, Collibra, or Alation.
The decision should come down to five questions:
-
Does it support the tools in your data stack?
Look for connector coverage across Snowflake, Databricks, BigQuery, Redshift, dbt, Airflow, Tableau, Power BI, Looker, Salesforce, and legacy databases. Active metadata only works when the platform can connect to the systems where data is created, transformed, governed, and consumed. See our comparison of metadata management tools for a vendor-by-vendor view.
-
Does metadata flow both ways?
Many catalogs only ingest metadata. Active metadata needs to push context back into Slack, Jira, BI dashboards, governance workflows, and query editors so users can see definitions, alerts, lineage, and policy context inside the tools they already use.
-
Does it support real-time updates?
The platform should detect schema changes, lineage updates, quality issues, and usage patterns quickly. If metadata only refreshes through nightly batch updates, it will not support real-time governance or discovery.
-
Are governance features built in?
Look for native support for PII and PHI classification, business glossary workflows, certified data assets, access governance, and impact analysis. OvalEdge, for example, supports sensitive-data classification and column-level lineage so teams can connect metadata management with governance execution.
-
Does the pricing model scale with enterprise use?
Per-user pricing can become expensive when governance expands across business, analytics, compliance, and engineering teams. Review the five-year total cost of ownership before selecting a platform.
If you already use a data catalog, evaluate whether it supports the bi-directional flow that active metadata requires. Many catalogs document metadata well, but they do not operationalize it across daily workflows.
Step 4: Ingest metadata sources & build flows
Ingesting relevant metadata sources across your data ecosystem is the foundation for building active metadata flows. By aggregating metadata from various systems, you create a centralized, real-time view of your data.
This ensures that all systems and users have access to the same up-to-date metadata, improving consistency and decision-making.
-
Data Sources: Collect metadata from all relevant systems, such as data catalogs, lineage systems, and user interaction logs. These systems will provide the foundation for building active metadata flows.
-
Metadata Flow Design: Build flows that ensure metadata is consistently updated and synchronized across platforms. This means ensuring that metadata can move seamlessly between your data warehouse, analytics tools, governance platforms, and more.
|
A marketing team frequently updates customer segmentation and models. By integrating customer data sources into the metadata flow, any change to the segmentation model automatically triggers metadata updates across the marketing and analytics platforms, ensuring consistency. |
Step 5: Enrich Metadata with Business Context
Technical metadata alone often lacks the business context that can make it truly actionable. By enriching metadata with business context such as ownership, usage patterns, and key business terms, you bridge the gap between technical data teams and business stakeholders, empowering both groups to make data-driven decisions.
-
Business Context: Add relevant business context to the metadata, such as defining business terms (e.g., "customer lifetime value," "churn rate") or linking datasets to specific business objectives (e.g., marketing, customer service).
-
Cross-Department Collaboration: Work closely with business teams to understand how they interact with data and what metadata will be most valuable to them.
|
In a healthcare organization, technical metadata might define a dataset as “patient records.” However, by enriching this metadata with business context, such as linking it to business units like “patient care” or “billing,” the data becomes more meaningful and actionable for different departments. |
Step 6: Embed metadata into workflows
Embedding metadata into everyday workflows ensures that it becomes an integral part of daily operations. By making metadata a part of the workflow, you allow teams to leverage it in real time, leading to improved decision-making and operational efficiency.
-
Integration with Daily Tools: Ensure that active metadata is integrated into the tools that teams use daily, such as analytics platforms, BI tools, or data management systems.
-
Ease of Access: Make sure that metadata is easily accessible and understandable by both technical and non-technical users, ensuring it can drive faster and better decision-making.
A data science team using an analytics tool to create predictive models can benefit from metadata being embedded directly into the tool.
|
For instance, by accessing metadata that reflects how often a dataset is updated, they can better understand the timeliness and relevance of the data they are using. |
Step 7: Operationalize & monitor
Once active metadata is integrated into your data ecosystem, it’s essential to establish processes for monitoring and maintaining it. Regular monitoring ensures that your metadata stays up-to-date, accurate, and aligned with business goals.
-
Metrics for Monitoring: Track metrics such as metadata update frequency, data quality, and user engagement. These metrics help you understand how well your active metadata strategy is performing.
-
Issue Identification and Resolution: Implement systems to flag issues like metadata mismatches, outdated data, or poor data quality. Early identification of issues allows for quicker resolutions, reducing the risk of using inaccurate data.
|
A retail company tracks customer transaction data using active metadata. By monitoring metadata usage frequency, the company can identify which datasets are underutilized and take action to either improve their quality or remove them from active use. |
Implementing active metadata requires a structured approach that involves assessing current practices, defining clear business objectives, choosing the right platforms, and embedding metadata into day-to-day workflows.
By following these steps, organizations can create a dynamic, real-time metadata ecosystem that enhances data governance, facilitates faster decision-making, and improves overall data management.
Realistic timeline for active metadata implementation
Most active metadata rollouts start with a few focused use cases before expanding across the enterprise. The first use cases usually include sensitive data classification, BI freshness alerts, and broken-dashboard root cause analysis.
|
Phase |
Duration |
What gets done |
|
Foundation |
Weeks 1-2 |
Inventory existing metadata sources, select the platform, and agree on the first three use cases, such as PII classification, BI freshness, and broken-dashboard root cause analysis. |
|
First integrations |
Weeks 3-6 |
Connect two to three priority sources, such as a warehouse, BI tool, and governance system. Set up bi-directional metadata flow and validate real-time syncs. |
|
First automations |
Weeks 6-8 |
Turn on auto-classification, lineage capture, and quality alerts for priority sources. Begin embedding metadata into Tableau, Looker, or Power BI. |
|
Scale and adopt |
Months 3-6 |
Expand to more data sources. Roll out workflows to business glossary owners, data stewards, and analytics teams. Track adoption and usage metrics. |
|
Full value |
Months 6-9 |
Active metadata feeds back into pipelines, access controls update automatically, and root cause analysis starts moving from days to minutes. |
A focused team can usually ship the first three active metadata use cases in about eight weeks. Full enterprise coverage typically takes six to nine months because teams need time to connect sources, validate lineage, align governance workflows, and drive adoption.
Be cautious of any “one-week activation” promise. That usually means the vendor is selling a connector setup, not a full active metadata operating layer.
Why active metadata matters for modern data teams
Active metadata enables organizations to streamline operations, enhance data governance, and improve decision-making.
1. It makes data discovery faster and more reliable
Business users often lose time searching for the right dataset, checking whether it is fresh, and asking data teams whether it can be trusted. Active metadata reduces that delay by showing the current context inside the tools users already work with.
For example, metadata can show:
-
Who owns the dataset
-
When it was last updated
-
Which dashboards use it
-
Whether it is certified
-
Whether there are known quality issues
When this context flows into tools such as Tableau, Looker, or Power BI, users do not need to leave their workflow to validate a dataset. They can search, compare, and use trusted data faster.
In OvalEdge, this connects directly with the data catalog, business glossary, and certification workflows. Teams can make trusted datasets easier to find while reducing dependency on tribal knowledge.
2. It strengthens governance and lineage
Governance breaks down when teams cannot see where data comes from, how it changes, or where it is consumed. Active metadata helps close that gap by tracking data movement across systems and keeping lineage current.
In 2023, the Accenture enterprise data study found that 55% of organizations cannot always trace data from its source to its point of consumption. That gap matters because lineage is central to impact analysis, compliance, audit readiness, and issue resolution.
Active metadata helps teams trace data across warehouses, pipelines, transformations, and dashboards. For example, if a column in Snowflake changes, teams can see which dbt models, Tableau dashboards, or downstream reports may be affected. Automated data lineage tools are the engine behind this in modern stacks, helping teams map data movement and identify downstream impact faster.
By providing real-time visibility into how data is used and where it moves, active metadata improves both data integrity and governance confidence.
| If you want to understand where lineage ends and observability begins, see this guide on data observability vs data lineage. |
3. It reduces manual metadata work
Manual metadata maintenance does not scale. Data stewards cannot keep up with every schema change, new data source, policy update, or usage shift across a growing data stack.
Active metadata automates routine metadata tasks such as:
-
Tagging new data assets
-
Classifying sensitive fields
-
Updating ownership and usage context
-
Capturing lineage
-
Flagging quality or freshness issues
This helps data teams spend less time updating catalogs by hand and more time improving data quality, governance workflows, and business adoption. Automated data governance follows the same playbook by applying automation to policy enforcement, access controls, and governance workflows.
In OvalEdge, automated classification and metadata enrichment help teams identify sensitive data, apply governance context, and keep metadata more current across connected systems.
4. It supports faster impact analysis and issue resolution
When a dashboard breaks or a metric changes, teams need to know what happened quickly. Passive metadata may show the table structure, but it may not show the latest dependency, transformation, or usage path.
Active metadata supports faster root cause analysis by connecting technical metadata, lineage, usage signals, and quality context.
For example, if a revenue dashboard in Tableau starts showing incorrect numbers, active metadata can help teams trace the issue back to a source table, transformation logic, or recent schema change. This shortens the investigation cycle and reduces the risk of business teams acting on incorrect data.
5. It prepares governance programs for AI workloads
AI systems depend on trusted, well-documented, and policy-aligned data. If teams cannot understand where training data comes from, how it changes, or whether it contains sensitive information, AI governance becomes difficult to enforce.
Active metadata helps by keeping data context current across pipelines, models, and governance workflows. It can show whether a dataset is approved for use, whether sensitive fields are present, who owns the data, and how the data has changed over time.
As AI adoption grows, this real-time context becomes a foundation for stronger governance, safer analytics, and more reliable data products.
Active metadata matters because it connects discovery, governance, lineage, and automation into one continuous flow. Instead of forcing teams to document data after the fact, it helps them govern and use data as it changes.
Conclusion
Passive metadata updates too slowly. It depends on manual effort. It fails to capture real usage and context. These limitations create blind spots that weaken discovery, governance, and decision-making.
Data governance is evolving into a modern, AI-driven discipline. It demands real-time visibility, automated controls, and intelligence that adapts as data flows across systems. Organizations can no longer rely on static documentation to manage dynamic, distributed, and rapidly changing data environments.
Active metadata has become a core pillar of this new governance model. It delivers continuous updates, behavioral context, and automated lineage that keep teams aligned with the true state of their data.
It turns metadata into an always-current intelligence layer that supports quality, trust, and faster decisions. As data ecosystems scale and AI becomes central to operations, active metadata will define how modern organizations govern, understand, and use their data.
Active metadata is the foundation; active data governance is the practice that runs on top of it.
If your team is still updating metadata by hand or chasing lineage across spreadsheets, OvalEdge can show you what active metadata looks like running on your own data stack.
Book a demo and see how OvalEdge auto-classifies sensitive columns, traces column-level lineage across Snowflake and Tableau, and pushes governance context into your BI tools, without manual tagging.
FAQs
1. What is active metadata in simple terms?
Active metadata is metadata that updates automatically as data is used, moved, or changed. Unlike passive metadata, which only describes tables, columns, and owners, active metadata also captures usage, movement, lineage, and policy signals in real time.
2. What is the difference between active and passive metadata?
Passive metadata is manually updated and mainly describes what a dataset is. Active metadata updates continuously based on system signals and shows how data is used, changed, governed, and consumed. Passive metadata documents data, while active metadata helps operationalize it.
3. Is active metadata the same as a data catalog?
No. A data catalog stores and organizes metadata. Active metadata is the real-time metadata layer that powers modern catalogs. It pulls signals from warehouses, BI tools, pipelines, and governance systems, then pushes useful context back into daily workflows.
4. How long does it take to implement active metadata?
Most teams can launch their first active metadata use cases in six to eight weeks. These often include PII classification, BI freshness alerts, and lineage-based root cause analysis. Full enterprise rollout usually takes six to nine months.
5. What are the most common use cases for active metadata?
Common active metadata use cases include sensitive-data classification, column-level lineage, data quality alerts, freshness monitoring, ownership visibility, BI context, and unused-asset cleanup. These use cases help teams reduce manual metadata work and improve governance.
6. Which platforms support active metadata?
Active metadata platforms include OvalEdge, Atlan, Collibra, Alation, Informatica, and data.world. Compare them based on connector coverage, bi-directional metadata flow, lineage depth, governance features, business glossary support, and total cost of ownership.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)