
When a single typo in your billing data causes 72 customers to be double-charged, and you don’t find out until QA hits your Slack at 8 PM. For a SaaS data engineering lead like you, that kind of mess is more than a bug; it’s a breach in trust.
Companies that ignore data quality aren’t just cleaning up messes; they’re paying for them.
This is why establishing a comprehensive data governance framework is no longer optional for modern organizations.
McKinsey found that data processing and cleanup can consume over 30% of analytics teams’ time due to poor data quality and availability.
This guide is your rapid-fire playbook for data quality tools in 2026: what’s really working, how AI is shifting the playing field, and how you can pick a solution that moves you from firefight to trusted data.
What are the best data quality tools in 2026?
The best data quality tools in 2026 are OvalEdge, Great Expectations, Soda Core, Monte Carlo, Metaplane, Ataccama ONE, Informatica Data Quality, Collibra, Talend, and IBM InfoSphere. Each serves a different team profile: OvalEdge and Collibra lead for enterprises that need governance and quality unified in one platform; Great Expectations and Soda Core lead for data engineering teams that embed validation in CI/CD pipelines; Monte Carlo and Metaplane lead for observability-first teams focused on real-time anomaly detection.
The right choice depends on three factors: whether you need standalone validation or governance-integrated quality, whether your team is engineering-led or governance-led, and whether your data stack is modern (Snowflake, dbt, Databricks) or hybrid with legacy systems.
What are data quality tools?
Data quality tools are software solutions that help teams keep their data accurate, complete, and consistent across systems and databases.
In simple terms, they act like automated quality control for your data pipelines, continuously checking whether the data flowing into your dashboards, analytics, and AI models is clean, reliable, and ready to use.
According to Gartner, these tools “identify, understand, and correct flaws in data” to improve accuracy and decision-making. For fast-growing SaaS companies, this means fewer data silos, reduced compliance risks, and more trustworthy business insights.
By improving data integrity and data standardization, these tools prevent costly downstream errors that can derail strategic initiatives and customer trust.
Effective data quality management requires both the right tools and the right organizational structure to ensure accountability.
What do data quality tools do?
At their core, data quality management tools automate the process of detecting, diagnosing, and correcting issues across structured and unstructured datasets.
They combine data validation, data profiling, metadata management, and data observability to maintain accuracy and consistency across multiple systems.
Here’s what they typically do:
-
Data validation: Ensures values meet defined business rules or formats, for example, verifying that every customer record includes a valid email or payment ID.
-
Data profiling: Examines data distributions and anomalies to uncover hidden issues before they affect reports or AI outputs.
Data profiling works hand-in-hand with metadata management best practices to uncover hidden issues before they affect reports or AI outputs. -
Standardization: Harmonizes formats, naming conventions, and units of measure across platforms, improving data consistency and reliability.
-
Duplicate detection and matching: Identifies redundant records to reduce duplication in CRM or ERP systems, improving data accuracy.
-
Data observability and monitoring: Tracks data quality metrics, like freshness, volume, and schema changes, to flag anomalies early and maintain data trust.
Together, these capabilities allow organizations to shift from reactive cleanup to proactive data governance. Instead of discovering broken data after it hits a report, teams can prevent issues before they happen, saving time, cost, and credibility.
Why data quality tools matter in 2026
In 2026, data quality and governance are business differentiators, not back-office tasks. With AI-driven analytics and self-service platforms expanding, unreliable data can distort forecasts, mislead models, and trigger compliance risks.
As organizations accelerate their AI readiness initiatives, ensuring high-quality training data becomes mission-critical for model accuracy and reliability.
That’s why leading organizations now rely on AI-based data quality tools that unify data observability, governance, and automation.
Modern platforms continuously monitor pipelines, detect anomalies, and fix issues in real time, ensuring data reliability from ingestion to insight.
This shift toward active data governance means quality issues are prevented before they cascade through downstream systems.
OvalEdge exemplifies this approach. It unites data quality, lineage, and governance within one ecosystem. Using active metadata, it automatically identifies issues, assigns ownership, and tracks remediation, creating a culture of data accountability and trust.
AI and Data Quality: What Has Changed in 2026
AI has fundamentally changed what data quality tools are expected to do. In earlier years, quality tools were reactive: they found problems after they occurred. In 2026, the leading platforms use machine learning to detect anomalies before they impact pipelines, automatically suggest quality rules based on observed data patterns, and continuously update lineage maps without manual configuration.
Three shifts define the AI-powered data quality landscape in 2026:
Automated anomaly detection: Instead of defining static thresholds manually, AI-powered tools learn what "normal" looks like for each dataset and alert teams when that pattern breaks. Monte Carlo and Metaplane lead here for observability use cases; OvalEdge's active metadata engine applies this across the full governance layer.
AI-assisted rule generation: Platforms like Ataccama ONE use machine learning to profile data and suggest quality rules automatically, reducing the manual configuration time that slows down traditional implementations. This matters most for enterprises managing hundreds of datasets across multiple domains.
AI readiness as a quality requirement: As organizations feed data into AI models, the quality standard for training and inference data has become stricter. A single schema error that might have caused a dashboard discrepancy in 2023 can now distort a model prediction at scale. This makes proactive lineage tracking and automated quality checks a prerequisite for any organization building on AI, not just a governance best practice.
For teams evaluating data quality tools in 2026, the question is no longer just "does this tool find errors?" It is "does this tool prevent them, document them, and make someone accountable for fixing them?"
10 best data quality tools for 2026
The best data quality tools in 2026 don’t just fix bad data; they build trust in every number, report, and AI model.
From open-source validation to enterprise-grade observability, these platforms help companies maintain clean, compliant, and reliable data at scale.
1. OvalEdge: Unified data quality, lineage & governance
OvalEdge combines data cataloging, lineage visualization, and quality monitoring into a single, governed platform. Its active metadata engine automatically detects anomalies, maps dependencies, and assigns data owners for quick remediation.
OvalEdge has been recognized as a Niche Player in the 2026 Gartner Magic Quadrant for Data and Analytics Governance Platforms, reinforcing its position as a trusted platform for unified data governance and quality management.
Upwork, the world’s largest work marketplace, used OvalEdge to unify fragmented data across multiple analytics environments.
The company implemented active metadata intelligence, data ownership visibility, and automated quality workflows, allowing every stakeholder, from analysts to executives, to understand how data flows, who owns it, and how reliable it is.
Here’s how OvalEdge helped Upwork overcome its governance challenges:
-
Connected quality and lineage to reveal the root cause of data discrepancies.
-
Automated governance workflows, ensuring every record has an accountable owner. This approach embodies effective data stewardship by clearly defining ownership and accountability for every data asset.
-
Enabled a unified catalog and glossary, improving data discoverability and consistency.
By connecting governance, lineage, and quality under one platform, OvalEdge turned fragmented, siloed data into a reliable enterprise asset, setting a new benchmark for data quality management tools in 2026.
Best for: Enterprises seeking a single, governed platform for data cataloging, lineage, and quality management.
2. Great Expectations
Great Expectations enables teams to define “expectations”, rules that data must meet, using simple YAML or Python. It integrates seamlessly with dbt, Airflow, and Snowflake, making validation a natural part of data workflows.
Vimeo used Great Expectations to improve reliability across its analytics pipelines. Data engineers previously struggled to ensure consistency between transformations and reports.
After adopting the framework, Vimeo embedded validation directly into its Airflow jobs, catching schema issues and anomalies early.
Heineken saw similar results when automating validation across Snowflake environments.
Here’s how Great Expectations helped Vimeo improve trust in analytics:
-
Automated validation checks within existing CI/CD processes.
-
Generated Data Docs for transparency between technical and business teams.
-
Reduced manual cleanup, freeing engineers to focus on higher-value analysis.
With its open-source flexibility and strong developer community, Great Expectations remains a top data validation framework for proactive quality control.
Best for: Data engineers and analytics teams embedding validation directly into CI/CD pipelines.
3. Soda Core & Soda Cloud

Soda Core and Soda Cloud work together to make data quality testing simple and collaborative. Soda Core, the open-source CLI framework, lets engineers define and run data tests as code.
Soda Cloud, the SaaS interface, adds real-time monitoring, anomaly detection, and alerting, giving teams a complete view of data reliability across pipelines.
HelloFresh faced recurring challenges with late or inconsistent data affecting reporting accuracy. By implementing Soda Cloud, they automated anomaly detection and monitored freshness across key pipelines.
The platform’s Slack integration allowed teams to resolve issues immediately, keeping operational data reliable across global systems.
Here’s how Soda helped HelloFresh streamline data reliability:
-
Automated freshness and anomaly detection for continuous monitoring.
-
Delivered real-time alerts in Slack to improve response time.
-
Reduced undetected issues before they reached production dashboards.
Soda’s blend of simplicity, observability, and collaboration makes it one of the most effective data quality monitoring tools for agile teams.
Best for: Analytics and data engineering teams that need quick, real-time visibility into data health.
4. Monte Carlo
Monte Carlo is one of the leading AI-based data quality tools that pioneered the concept of data observability, continuously monitoring data freshness, schema changes, and pipeline performance across modern data stacks.
It automatically detects anomalies, quantifies incident impact, and maps data lineage to reduce downtime across data ecosystems.
Warner Bros. Discovery adopted Monte Carlo to tackle broken dashboards and late analytics updates during its post-merger data consolidation.
By enabling end-to-end lineage visibility and automated anomaly detection, the company reduced downtime and rebuilt confidence in its data pipelines.
Here’s how Monte Carlo helped Warner Bros. Discovery regain data trust:
-
Mapped lineage to trace errors from dashboards to upstream tables.
-
Automated anomaly detection, minimizing manual investigations.
-
Improved response time with AI-driven alerts and insights.
With strong integrations across Snowflake, Databricks, and BigQuery, Monte Carlo remains the gold standard for data observability platforms at enterprise scale.
Best for: Large enterprises focused on data reliability, uptime, and automated anomaly detection.
5. Metaplane
Metaplane is a lightweight data observability platform designed for analytics teams that rely on tools like dbt, Snowflake, and Looker. It automatically detects anomalies in metrics, schema, and data volume, and alerts teams before bad data impacts decision-making.
According to Metaplane’s customer stories, companies such as Ramp and Drizly use Metaplane to monitor key data pipelines and ensure consistent, trustworthy reporting.
Ramp, a fintech company, used Metaplane to eliminate unreliable dashboard metrics caused by unnoticed schema changes. With dbt and Snowflake integration, they could detect anomalies automatically and alert analysts instantly through Slack.
Here’s how Metaplane helped Ramp strengthen pipeline reliability:
-
Automated anomaly detection across dbt models and data warehouses.
-
Provided instant alerts, reducing the time to identify data issues.
-
Improved analyst confidence in dashboards and reporting accuracy.
Metaplane’s speed, simplicity, and modern design make it a powerful choice for small teams aiming to maintain big-enterprise reliability.
Best for: SaaS and analytics teams that need fast, automated data observability without heavy engineering overhead.
6. Ataccama ONE

Ataccama ONE is an enterprise-grade platform that combines data quality management, AI-assisted profiling, and master data management (MDM) in a single environment.
It uses machine learning to automatically detect data patterns, suggest quality rules, and classify sensitive information, reducing manual effort in large-scale data operations.
Vodafone used Ataccama to overcome fragmented customer records across markets. Its AI-driven data profiling and automated rule generation helped the company standardize customer information, improving personalization and compliance with GDPR.
Here’s how Ataccama helped Vodafone manage complex data at scale:
-
Unified customer records across multiple regions for a single source of truth.
-
Automated rule discovery, reducing manual configuration time.
-
Ensured compliance with strict European data protection laws.
By merging MDM and AI-based automation, Ataccama ONE empowers enterprises to maintain data consistency, quality, and governance at scale.
Best for: Large enterprises managing complex, multi-domain data ecosystems with governance and AI-driven automation needs.
7. Informatica Data Quality
Informatica Data Quality (IDQ) is one of the most established enterprise data quality tools, providing deep capabilities for data profiling, matching, standardization, and cleansing. It’s part of the Informatica Intelligent Data Management Cloud (IDMC), which connects data quality with governance, integration, and metadata management.
KPMG implemented Informatica IDQ to automate validation in financial datasets used for audits and compliance. The result was improved accuracy, fewer manual reviews, and consistent reporting across business units.
Here’s how Informatica helped KPMG achieve audit-ready data:
-
Automated validation and matching for financial reporting accuracy.
-
Created standardized data models, reducing inconsistencies.
-
Integrated governance and lineage, ensuring traceable compliance.
For companies operating in regulated industries, Informatica Data Quality delivers the reliability, lineage tracking, and performance needed to maintain clean, compliant, and trusted data every day, across every system.
Best for: Large organizations that require robust, customizable data profiling and compliance-grade data governance.
8. Collibra
Collibra Data Quality & Observability connects data quality monitoring directly to business context, linking datasets, quality rules, and ownership inside the Collibra Data Intelligence Platform.
This integration allows organizations to measure, visualize, and improve data trust while keeping governance at the center of their data operations.
Adobe adopted Collibra to unify governance standards across marketing analytics. The platform’s AI-powered rule generation helped standardize customer data definitions and ensure consistent reporting globally.
Here’s how Collibra helped Adobe strengthen governance and quality:
-
Linked quality rules with data ownership for accountability.
-
Automated rule generation saves time on manual setup.
-
Improved reporting accuracy, reducing duplicated definitions across teams.
By embedding governance into quality monitoring, Collibra helps enterprises turn data stewardship into measurable trust.
Best for: Enterprises with established governance programs that want to unify quality, lineage, and catalog insights.
9. Talend
Talend Data Quality is part of the broader Talend Data Fabric, combining data profiling, standardization, and cleansing with seamless integration capabilities.
It’s designed to ensure that data entering analytics platforms or business systems is complete, consistent, and compliant with governance rules.
Domino’s used Talend to unify customer and order data from multiple systems, improving delivery analytics and digital experience consistency.
The platform’s cleansing and transformation tools reduced data duplication and accelerated insights (Talend Case Studies).
Here’s how Talend helped Domino’s improve operational data accuracy:
-
Consolidated disparate data sources into one clean repository.
-
Automated cleansing and standardization, reducing manual data prep.
-
Improved analytics accuracy, enhancing marketing and logistics performance.
With its hybrid deployment model and open-source roots, Talend remains a trusted choice for integration-driven data quality management.
Best for: Data engineering and operations teams managing hybrid pipelines across cloud and on-prem environments.
10. IBM InfoSphere Information Server
IBM InfoSphere Information Server is one of the most established data quality and integration platforms for enterprise-scale data management.
It offers data profiling, validation, transformation, and governance capabilities in a unified environment, built to handle massive data volumes and regulatory workloads.
Erste Bank used InfoSphere to streamline data validation and compliance reporting for Basel III and BCBS 239 standards, improving accuracy and audit readiness (IBM Case Studies).
Here’s how IBM InfoSphere helped Erste Bank ensure compliance and reliability:
-
Automated data validation reduces manual verification time.
-
Provided lineage visibility, making compliance audits easier.
-
Standardized quality controls across finance and risk systems.
With its enterprise-grade scalability and proven reliability, IBM InfoSphere remains a cornerstone data quality platform for organizations managing regulated or legacy data.
Best for: Large enterprises and government organizations managing legacy systems or complex data infrastructures.
How to Choose the Right Data Quality Tool for Your Organization
Choosing a data quality tool depends on your team structure, data stack, and governance maturity. The market in 2026 splits across four distinct buyer profiles. Matching your profile to the right tool category is the fastest path to measurable impact.
If you are a data engineering team working in a modern stack (dbt, Snowflake, Airflow): Start with Great Expectations or Soda Core. Both embed directly into your pipelines, run validation as code, and integrate natively with the tools you already use. They require engineering ownership but are the most flexible and cost-effective options for shift-left quality.
If you are a data and analytics team that needs real-time observability: Monte Carlo or Metaplane. Both detect anomalies automatically, map lineage to trace issues, and alert teams through Slack or email before problems reach dashboards. Monte Carlo suits large enterprise environments; Metaplane suits lean SaaS teams.
If you are an enterprise with a data governance program or compliance requirements: OvalEdge, Collibra, or Ataccama ONE. These platforms connect quality to ownership, lineage, and policy enforcement. They are built for environments where data must be documented, auditable, and managed across business and technical stakeholders.
If you are managing legacy systems or regulated data at scale (banking, government, healthcare): Informatica IDQ or IBM InfoSphere. Both handle large data volumes, support compliance frameworks including BCBS 239, SOX, and HIPAA, and offer the depth of profiling and matching that legacy environments require.
Three questions to ask any vendor before buying:
- Does the tool integrate with your existing warehouse and pipeline without a full rebuild?
- Can it connect quality issues back to a data owner who is accountable for resolution?
- Does it produce a documented audit trail for compliance purposes?
Why OvalEdge outperforms standalone data quality tools
Most data quality tools focus on a single capability, like profiling or monitoring, but they don’t solve the larger challenge of connecting issues back to ownership, governance, and impact. That’s why teams often fix the same problems repeatedly, without improving data trust long term.
A Michigan-based hospital using Epic Systems adopted OvalEdge to solve compliance and traceability challenges across departments. Before OvalEdge, patient and operational data were siloed, making HIPAA audits time-consuming and risky.
By deploying OvalEdge, the hospital built a centralized data catalog, established stewardship roles, and automated lineage mapping.
These steps improved audit readiness, strengthened data accuracy, and gave clinical teams confidence in their reports.
Here’s what sets OvalEdge apart:
-
Active metadata intelligence: Continuously scans and updates lineage to detect anomalies in real time.
-
Business-rule integration: Converts governance policies into enforceable quality rules across systems.
-
Automated stewardship workflows: Assigns and tracks data quality issues, ensuring every record has an owner.
-
End-to-end lineage visualization: Traces every metric from source to report, simplifying root-cause analysis.
-
Unified catalog and glossary: Aligns business and technical users under shared definitions for consistency. OvalEdge's business glossary ensures everyone speaks the same data language, eliminating confusion around metric definitions.
-
AI-driven quality scoring: Prioritizes critical issues for faster resolution and stronger compliance.
By combining governance, quality, and automation, OvalEdge helped the customer turn fragmented data into a single, trusted source of truth, proving that when data quality and governance work together, reliability becomes a built-in advantage.
Challenges in implementing and managing data quality tools
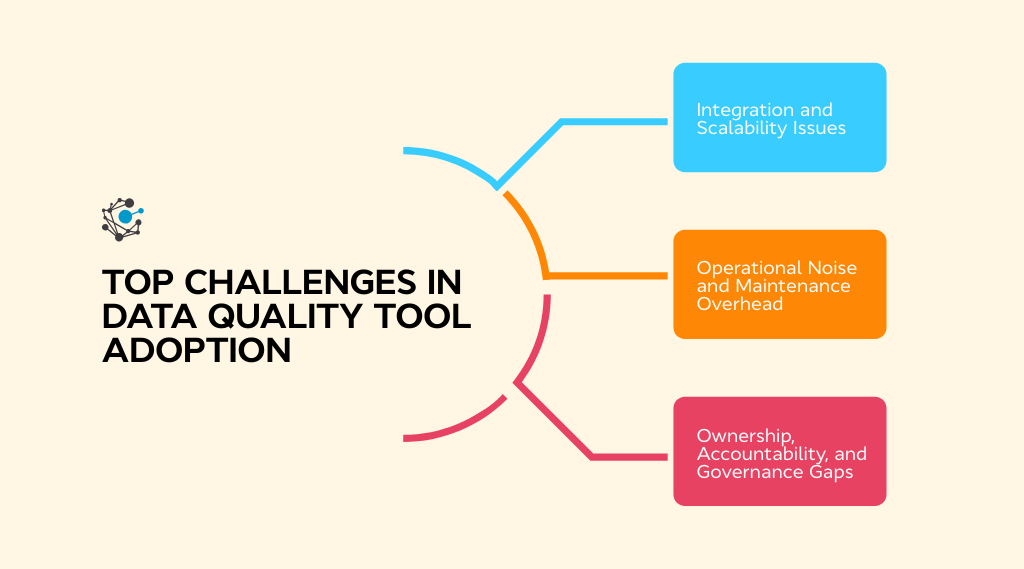
Even the best data quality tools can fall short if they aren’t implemented with the right governance, integration, and accountability structures.
Many organizations discover that ensuring accuracy at scale isn’t a technology problem alone; it’s a combination of process, ownership, and trust.
Here are the most common challenges teams face when managing data quality programs:
-
Integration and scalability issues
Integrating data quality tools into existing ecosystems often requires complex configurations and custom connectors, delaying implementation and results.
As data volumes grow, traditional solutions struggle to process large datasets efficiently, creating performance bottlenecks and forcing teams to invest in additional infrastructure and manual oversight.
-
Operational noise and maintenance overhead
Static thresholds and redundant alerts frequently lead to alert fatigue, making it difficult for data teams to focus on the issues that truly impact business outcomes.
Over time, maintaining these systems becomes burdensome, with ongoing tuning and monitoring required to ensure relevance and effectiveness.
-
Ownership, accountability, and governance Gaps
Without clear data ownership and stewardship models, accountability suffers, resulting in unresolved quality issues and inconsistent reporting.
In regulated industries, disconnected governance processes further complicate compliance efforts, making it challenging to maintain audit trails or meet frameworks like GDPR, HIPAA, and SOC 2.
Organizations operating in regulated environments, whether managing BCBS 239 compliance in banking or NDMO standards in Saudi Arabia, face even greater complexity.
These challenges highlight why organizations are moving toward integrated platforms like OvalEdge, where data quality, lineage, and governance operate within a single, active metadata framework.
Best practices for building a data quality framework
Building a strong data quality framework is all about creating a culture of accountability where every dataset is accurate, compliant, and trusted.
The most effective organizations blend automation, governance, and collaboration to make quality a continuous process rather than a one-time cleanup effort.
Here are the best practices that define a successful, future-ready data quality strategy:
-
Embed testing directly into CI/CD pipelines. Integrate validation tools like dbt tests or automated rule engines early in your data lifecycle. This ensures errors are caught before they reach analytics or AI models, reducing rework and downstream risk.
-
Link data quality to governance and stewardship. Quality improves when data ownership is clear. Define stewardship roles and connect them with business rules, glossaries, and access policies. This ensures accountability and compliance across every system.
Following the four pillars of data governance helps organizations build comprehensive frameworks that balance quality, security, stewardship, and lifecycle management. -
Leverage active metadata and automation. Modern data ecosystems move fast, and manual monitoring can’t keep up. Use metadata-driven automation to continuously detect anomalies, refresh lineage, and update data quality scores in real time.
-
Standardize rules and metrics across platforms. Establish a shared set of definitions for accuracy, completeness, and timeliness. Consistent standards help avoid duplication, simplify reporting, and make cross-team collaboration easier.
-
Create feedback loops for continuous improvement. Treat data quality like DevOps: monitor, measure, and refine it. Regular reviews and automated alerts help identify recurring issues and improve processes over time.
Organizations using unified platforms like OvalEdge can automate these best practices by connecting data quality, lineage, and governance into one intelligent system.
Instead of reactive fixes, they gain proactive control, where every anomaly is traced, every issue has an owner, and every dataset contributes to business trust.
Conclusion
In 2026, data quality is the foundation of trust, compliance, and competitive advantage. The right data quality tool goes beyond fixing errors; it connects governance, lineage, and automation so your teams can make confident, data-driven decisions every day.
That’s exactly what OvalEdge delivers. Its unified, metadata-driven platform turns fragmented data into a governed, reliable source of truth, powering analytics, AI, and compliance with confidence.
If you’re ready to move from reactive fixes to proactive data trust, book a personalized demo of OvalEdge and see how you can build a data ecosystem where quality is automatic and trust is measurable.
FAQs
1. What is the difference between data quality and data governance?
Data quality focuses on the accuracy, completeness, and consistency of data. Data governance defines the policies, roles, and rules that ensure data is managed responsibly.
Together, they create a framework for trusted, compliant, and reliable decision-making across the enterprise.
To understand this relationship better, explore our comprehensive guide on what data governance is and how it creates the foundation for quality initiatives.
2. How do AI-based data quality tools improve data reliability?
AI-powered data quality tools use machine learning to detect anomalies, suggest quality rules, and automate validation. This reduces manual monitoring and helps teams maintain real-time trust in datasets, especially in fast-changing environments like cloud analytics or AI-driven platforms.
3. How can my organization implement an effective data quality strategy?
Start by assessing your current data landscape, identifying where data quality breaks down, who owns key datasets, and how governance is enforced. Then, adopt a platform like OvalEdge that unifies data quality, lineage, and governance in one place. This helps automate rule enforcement, assign ownership, and maintain continuous trust across all your systems.
4. How do you choose the right data quality tool for your organization?
The best data quality tool depends on your priorities, whether you need automation, governance integration, or observability. Enterprises often look for solutions that unify quality, lineage, and metadata to reduce complexity and improve accountability, such as OvalEdge.
5. Can data quality tools help with AI and compliance initiatives?
Yes. Data quality tools ensure the datasets feeding AI models and compliance reports are accurate, complete, and governed. Platforms like OvalEdge help organizations maintain lineage visibility, assign data ownership, and meet frameworks such as GDPR, SOC 2, and HIPAA.
Organizations can also benefit from understanding specific compliance requirements like data privacy compliance and how quality tools support regulatory adherence.
6. What metrics should you track in a data quality program?
Common data quality metrics include accuracy, completeness, consistency, timeliness, and validity. Tracking these continuously helps organizations identify patterns, measure improvement, and maintain long-term trust in business-critical data.
7. What are the best data quality tools in 2026?
The best data quality tools in 2026 are OvalEdge, Great Expectations, Soda Core, Monte Carlo, Metaplane, Ataccama ONE, Informatica Data Quality, Collibra, Talend, and IBM InfoSphere. The right choice depends on whether you need observability, validation in CI/CD pipelines, or a governance-integrated quality platform. Enterprises with compliance requirements typically choose OvalEdge, Collibra, or Informatica. Engineering-led teams typically start with Great Expectations or Soda Core.
8. What is the best software for managing data quality and lineage together?
OvalEdge is the strongest option for organizations that need data quality and lineage managed in one platform. It connects quality issues directly to lineage maps so teams can trace where a problem entered the pipeline, who owns the affected asset, and what downstream reports or models are at risk. Collibra offers similar integration but focuses more on business glossary and governance policy enforcement. For teams that only need lineage visibility without full quality management, standalone lineage tools or Monte Carlo's observability platform are alternatives.
9. What should I look for when evaluating data quality tools?
The four most important evaluation criteria are: integration with your existing data stack without requiring a rebuild, the ability to connect quality issues to a named data owner for accountability, a documented audit trail for compliance purposes, and the level of engineering effort required to implement and maintain. Enterprise governance platforms like OvalEdge automate most of this. Open source tools like Great Expectations require more configuration but offer more flexibility for engineering-led teams.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)