.png)
Context engineering frameworks help AI systems access trusted, governed, and relevant information before generating answers or taking action. As AI adoption expands, context quality becomes critical for accuracy, consistency, and compliance. This guide explains what context engineering frameworks are, why enterprises need them, and how to build one using a practical six-step approach. It also explores common implementation challenges and the governance capabilities that support trusted AI at scale.
An AI assistant delivers a recommendation in seconds. The answer looks credible, cites multiple sources, and sounds convincing. Yet the conclusion is wrong because the system relied on outdated data, conflicting business definitions, and incomplete policies.
This challenge is becoming increasingly common as organizations expand AI across business processes.
According to AONA AI's 2025 AI Adoption Statistics report, 72% of enterprises have already deployed AI in at least one business function, while only 30% have formal AI governance frameworks in place.
As a result, many organizations struggle to ensure AI systems operate with trusted and governed information.
Context engineering frameworks help address this challenge by creating a structured approach for selecting, organizing, and delivering the context AI systems need to generate reliable outcomes.
What is a context engineering framework?
A context engineering framework is a repeatable approach for designing, governing, retrieving, and delivering the information an AI system uses before it responds or acts. Rather than relying on ad hoc prompts or disconnected retrieval systems, it helps organizations create a trusted, permission-aware, and reusable context layer for AI.
Unlike prompt engineering, which focuses on instructions, a context engineering framework manages the broader information environment that shapes AI outputs.
It can incorporate technologies such as RAG, vector databases, knowledge graphs, and orchestration tools, while also connecting them to governance, metadata, ownership, and validation processes.
Why enterprises need a context engineering framework
The need for structured context engineering has grown sharply because AI is moving from isolated experiments to enterprise-wide deployment. What AI systems are expected to do has also shifted. Early deployments were chat assistants and copilots that generated text. The current wave is agents, decision-support workflows, and governed analytics experiences.
These systems need reliable access to the current business context in a form that machines can use directly.
OvalEdge's view is that the missing layer is not smarter retrieval. It is business meaning rules. An AI system may be trained on language patterns that let it understand the word "revenue," but without explicit governance, it will not know which revenue definition the business intends, whether booked, recognized, or collected.
It will not know whether the data is current or whether the user has permission to see it. That gap between semantic understanding and governed business meaning is where trusted AI governance frameworks help agents succeed.
Without a framework, teams often build AI systems that retrieve information successfully but cannot consistently determine which sources, definitions, policies, and permissions should guide their decisions.
Without a framework, here's what happens in most enterprises. Team A builds a RAG pipeline for procurement questions. Team B builds a different pipeline for finance questions. Team C builds a third architecture for operations. Each team:
-
Writes its own retrieval logic
-
Manages its own source rules
-
Decides what counts as trusted context
-
Builds its own validation process
The result is inconsistent answers, duplicated engineering effort, weak governance, and a fragmented context that no one owns.
When AI spreads across the workforce, context becomes a shared infrastructure problem, not a team-level concern. A framework prevents fragmentation by creating a single operating model for how enterprise context flows into AI systems. Without it, governance becomes difficult to enforce and trustworthiness begins to erode.
Context engineering framework vs context engineering tools
Teams often confuse context engineering frameworks with context engineering tools. The distinction matters because buying tools does not automatically create a reliable context strategy.
A context engineering framework defines the process and governance model for how context is selected, validated, delivered, and maintained. Tools help execute specific parts of that process. Technologies such as RAG, MCP, vector databases, knowledge graphs, and orchestration frameworks are valuable, but they do not determine what information is trusted, who can access it, or how context quality is monitored.
This is why successful enterprise AI programs combine framework discipline with the right tools. The framework defines the rules. The tools help implement them.
|
Area |
Context Engineering Framework |
Context Engineering Tools |
|
Purpose |
Defines how context is governed and managed |
Executes specific context-related tasks |
|
Scope |
End-to-end context lifecycle |
Retrieval, orchestration, storage, and monitoring |
|
Examples |
Governance model, context policies, operating processes |
RAG, MCP, LangChain, Google ADK, vector databases |
|
Ownership |
Shared across AI, data, and governance teams |
Typically owned by engineering teams |
|
Risk if Missing |
Inconsistent and ungoverned context |
Manual or inefficient implementation |
A 6-step enterprise context engineering framework
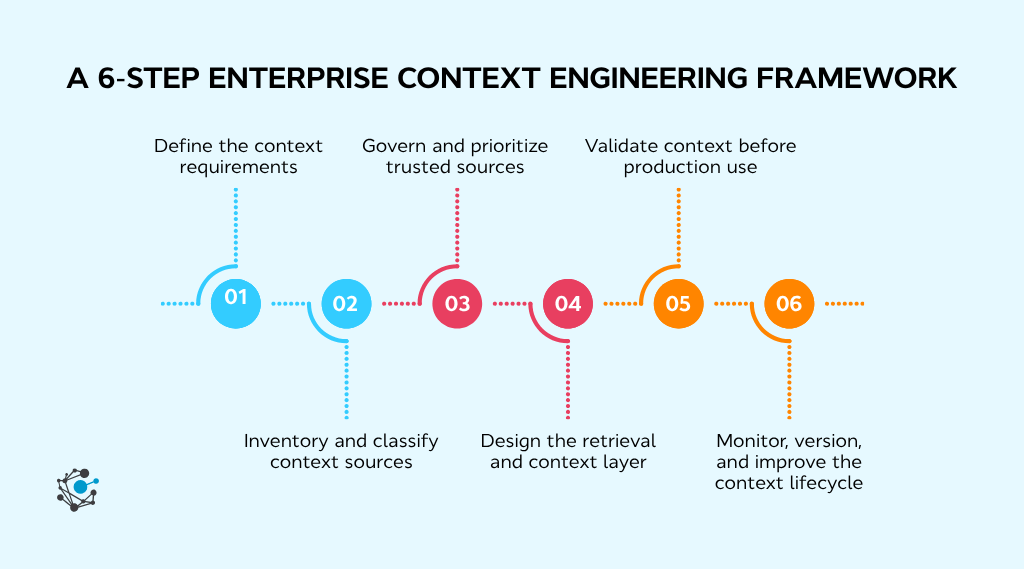
A practical context engineering framework moves through six clear steps. Each step builds on the last and helps ensure AI systems receive accurate, trusted, and governed context.
Step 1: Define the context requirements
Before you build anything, you have to know what the AI system actually needs to know. Most teams skip this and jump straight to tool selection. Start by asking: What is the user trying to do? What domain are they working in? What specific data sources matter? What definitions does the system need? What compliance or permission boundaries exist?
A finance copilot needs approved metric definitions, governed financial tables, access permissions that respect cost center boundaries, and lineage that traces where numbers came from. It does not need every financial document in the company. It needs the specific subset of context that makes the answer accurate and defensible.
For example, in healthcare, a clinical decision-support AI needs approved treatment protocols, patient data that the doctor is permitted to access, quality metrics for evidence-based practices, and disclaimers about liability. It doesn't need the patient's genetic research data or experimental trials unvetted by the institution.
In OvalEdge's experience, teams often make the mistake of starting with architecture instead of context requirements. They focus on building knowledge graphs, retrieval pipelines, or ontologies before identifying the business concepts that matter most. In healthcare, those may be the clinical definitions that influence patient safety.
In finance, it may be determining which approved definition of revenue the AI should use. The framework should establish these requirements first, then design the architecture around them.
Step 2: Inventory and classify context sources
Context sources live in databases, data warehouses, documents, reports, dashboards, APIs, and business glossaries. Before any of these feeds can be used by an AI system reliably, teams need to know what each contains, who owns it, when it was last updated, whether it's sensitive, and whether it's approved for AI use.
This is where metadata becomes critical. A table labeled "customers" could mean different things in different systems. A "revenue" field could be booked revenue, recognized revenue, or cash collected. Without metadata, you can't answer the basic questions that make context trustworthy.
Implementation tip: Tools such as OvalEdge Data Catalog help organizations inventory and govern context sources by providing visibility into metadata, ownership, lineage, and business context across enterprise data assets.
For example, in a fintech platform, mapping where "account balance" lives means identifying the ledger system, the customer-facing app database, and the reconciliation database; they often differ.
This is why governed metadata stops being a documentation exercise and becomes a machine-usable context. Without it, a retrieval pipeline cannot explain to an agent which version of 'account balance' is trusted or why.
Struggling to identify trusted context sources across your enterprise? Book a demo to see how OvalEdge helps teams discover, classify, and govern data assets for an AI-ready context.
Step 3: Govern and prioritize trusted sources
Not every available source should become a model context. This step separates enterprises that deploy reliable AI from those that discover their AI is using stale data, contradictory definitions, or information it shouldn't have access to.
Approved sources are those that the business has decided are suitable for AI use. Certified sources go further: a data owner has reviewed them and vouched for their accuracy. Sensitive sources require special handling. Without this step, retrieval pipelines pick context based on semantic similarity alone, which often leads to outdated definitions or exposed sensitive information.
For example, in banking, deciding that loan eligibility decisions use the certified credit score from Equifax, not an older internal score, and in insurance, designating which claims database is the source of truth for underwriting rules versus marketing claims.
OvalEdge's principle: Governance is slow when teams start with the wrong scope. Smart scoping means choosing one urgent business problem, governing the data that matters most to it, proving value, and then expanding
Step 4: Design the retrieval and context Layer
Once you know which sources are trusted, design how the context will be retrieved and delivered. This is where RAG, knowledge graphs, and MCP become relevant, but the design should be driven by steps 1-3, not by tool capabilities.
RAG retrieves relevant documents by semantic similarity, but that's not the only filter. The retrieval layer should also use metadata to narrow results: filter by owner, restrict to recently updated data, exclude sensitive information unless the user has permission, and prioritize certified sources, much like how responsible AI data governance ties governance policy to retrieval logic in real time.
One practical approach: let vector similarity find candidates, use metadata filters to refine them, then rank by governance signals like freshness and certification.
For example, a legal services AI might retrieve contract clauses based on semantic match, but then filter by jurisdiction (only California law), certify source (only approved precedents), and exclude redacted sections.
Step 5: Validate context before production use
Context should be tested before the AI system reaches users. Validation checks whether the retrieved context is accurate, whether it's the right source for the user's permission level, whether all necessary context was found, and whether the AI is using approved sources.
For a revenue question: Did the AI use the approved revenue definition? Did it pull from the certified data source? Did it respect cost center access controls? Can the user actually see this data? These checks can be automated, but human review is essential for regulated or business-critical workflows.
Step 6: Monitor, version, and improve the context lifecycle
Context engineering is not a one-time setup. It's an ongoing practice. Source freshness changes. Definitions evolve. Access policies shift. A source that was current two months ago might be stale now.
Monitor for source freshness, context drift, hallucination, and user feedback. For agents and autonomous systems, lifecycle management is critical because an agent running on stale context compounds problems with every decision. Versioning is part of this: when a definition changes, version it. When access policies shift, track those versions. This makes it possible to audit what context an AI system was using at any point in time.
For example, a financial services firm discovers its AI has been citing outdated exchange rates for currency conversions.
Who owns a context engineering framework?
Context engineering is a cross-functional discipline. It spans data engineering, data governance, AI/ML, and business teams, which means ownership must be clearly defined.
The most effective approach is to separate accountability from execution. A single owner, typically the CDO office, data governance function, or AI governance leader, should be accountable for the framework as a whole. This owner is responsible for ensuring the framework remains aligned with business objectives, governance requirements, and AI initiatives.
Execution is distributed across teams. Data engineering builds and maintains the infrastructure and retrieval mechanisms. Governance teams define trusted sources, business definitions, and access policies. AI/ML teams determine how agents consume and validate context at runtime.
The table below shows how execution responsibilities are typically divided across the framework lifecycle.
|
Framework step |
Primary owner |
Supporting teams |
|
Define requirements |
AI/ML + business users |
Governance |
|
Inventory sources |
Data engineering |
Governance |
|
Govern trusted sources |
Data governance/CDO office |
Data engineering, subject matter experts |
|
Design retrieval layer |
Data/platform engineering |
AI/ML |
|
Validate context |
AI/ML + governance |
Domain owners |
|
Monitor lifecycle |
Governance + platform |
Data product owners |
A shared source of truth, typically a governed catalog or metadata platform, helps keep these teams aligned.
What should a context engineering framework include?
The best frameworks have several key components working together.
-
Context inventory: A discoverable map of what sources can supply context. This isn't just a list. It's a catalog that describes what each source contains, who owns it, how fresh it is, and whether it's approved for AI use.
-
Metadata layer: Descriptors that explain what each context source means, who maintains it, how often it updates, whether it's sensitive, and how it relates to other sources. Without good metadata, retrieval is blind.
-
Governance rules: The explicit decisions about which sources are approved, which are restricted, what access permissions apply, and what policies govern their use. These rules feed directly into retrieval and validation.
-
Retrieval layer: The technical mechanism for finding and assembling context. This includes semantic search (RAG), graph traversal for relationships, filtering by metadata, and ranking by governance signals like freshness and certification.
-
Knowledge graph or context map: Relationships between data assets, business definitions, systems, policies, and owners. This surfaces context that point queries might miss.
-
Validation process: Automated and manual checks that verify context accuracy, relevance, completeness, and permission-awareness before it reaches users or drives agent actions.
-
Orchestration layer: The routing logic that ensures the right context reaches the right model, agent, or tool in the right format. Different use cases need different context shapes.
-
Versioning system: The ability to track how context changes over time. When a definition changes, what triggered it? When access rules shift, what prompted the change? This matters for compliance and debugging.
-
Monitoring and observability: Continuous signals about whether sources are fresh, whether retrieval is working correctly, whether contexts are drifting, and whether validation is catching problems.
The stronger frameworks don't treat governance and AI engineering as separate tracks. They treat them as integrated.
Common mistakes when building a context engineering framework

Even well-designed context engineering frameworks can fail if foundational mistakes are overlooked during implementation.
1. Starting with tools before context requirements
Teams often buy RAG, MCP, or agent frameworks before they've defined what context they actually need. The result is a sophisticated system retrieving the wrong information.
2. Treating all sources as equally trustworthy
Enterprise context should be ranked. A dashboard maintained by a professional analytics team is more trustworthy than a spreadsheet maintained by someone's personal folder. A definition approved by the business is more reliable than an inferred one. Without explicit ranking, retrieval defaults to "whatever matches the query best," which is not good enough.
3. Ignoring metadata and lineage
This is where frameworks slip into fragility. Without metadata, you can't explain where an answer came from. Without lineage, you can't assess whether the underlying sources are trustworthy. When an AI system gives an answer and someone asks, "Where did that come from?" you have to be able to answer clearly. Metadata is how you do that.
OvalEdge has seen this repeatedly: metadata transforms from documentation into machine-usable context when AI enters the picture. It is the difference between a governance tool for people and a governance tool for agents, the core insight behind the governed semantic layer for AI, and why traditional metadata management falls short once agents are in the loop.
4. Skipping validation
It's tempting to assume that if retrieval works well and the model is good, the answers will be right. Validation catches the cases where good retrieval meets contradictory context or sensitive data that shouldn't have been exposed.
5. Forgetting lifecycle ownership
The framework ships, runs for a few months, and then starts degrading. Sources go stale. Definitions change. Access policies shift. New regulations arrive. Without clear ownership of the lifecycle, the framework becomes a monument to how things were, not a living system for how things are.
How OvalEdge fits into an enterprise context engineering framework
A context engineering framework is only as reliable as the information it can access and trust. While retrieval and orchestration technologies help deliver context, they depend on governance capabilities that determine what information should be used, who can access it, and whether it can be trusted.
OvalEdge provides several of the foundational capabilities that support an enterprise context engineering framework:
-
Data catalog and source inventory: Helps teams discover available data assets, understand ownership, and identify which sources are suitable for AI use.
-
Business glossary and trusted definitions: Provides a governed source of business terms and metrics, helping AI systems use consistent definitions across the organization.
-
Lineage and traceability: OvalEdge's data lineage capabilities enable teams to understand where data originated, how it was transformed, and how AI outputs can be traced back to source systems, which is critical for auditing the context an agent actually used and why.
-
Data quality signals: Surface quality and certification information that can help prioritize trusted sources and identify potential risks.
-
Access governance and privacy controls: Supports permission-aware context retrieval by helping ensure sensitive data is only accessible to authorized users.
-
AI governance: Helps organizations document AI use cases, data dependencies, and governance requirements associated with AI initiatives.
Together, these capabilities help organizations build a context layer that is discoverable, governed, traceable, and trusted. As teams move through the framework, they can use metadata, glossary definitions, lineage, quality signals, and governance controls to improve context selection, validation, and ongoing management.
Conclusion
A context engineering framework gives enterprises a structured way to operationalize context for AI systems. It moves teams from ad hoc prompts to a governed, reusable, trustworthy context.
The framework works through six steps: define context requirements, inventory sources, govern trusted context, design retrieval, validate before production, and monitor lifecycle.
Start with one AI use case. Map what context it needs, where it lives, which sources are trustworthy, and how you'll keep it current. The biggest friction point is identifying governed, trustworthy sources; that's where visibility into your data landscape matters.
Platforms like OvalEdge can help you build this foundation through data catalog, business glossary, lineage, and access governance.
Ready to get started? Schedule a demo to see how governed metadata supports your context framework.tory audit processes.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)