
Agentic data stewardship introduces AI agents as an execution layer that enforces governance across environments. It replaces ticket-driven processes with real-time workflows for classification, quality validation, lineage analysis, and compliance. Organizations gain faster outcomes while scaling operations. This guide outlines implementation steps, policies, and human-in-the-loop oversight, ensuring automated decisions remain transparent, auditable, and aligned with evolving business and regulatory requirements.
Stewardship is no longer a periodic task. It is a continuous responsibility that needs to keep pace with real-time data flows and decisions across enterprise systems.
This is where agentic data stewardship comes in. It introduces AI agents that can autonomously tag metadata, classify data assets, validate quality, and enforce governance policies without requiring constant human intervention. Instead of relying on stewards to execute every task manually, these agents operate as an execution layer that runs continuously in the background.
For CDOs and data governance leaders, the focus is shifting from managing tasks to designing how stewardship runs at scale. This blog breaks down what agentic data stewardship means in practice, how it changes the steward role, which workflows AI agents can handle effectively, and how to implement it with the right governance controls in place.
What is agentic data stewardship?
Agentic data stewardship uses AI agents to execute stewardship tasks such as metadata tagging, data quality monitoring, and policy enforcement in real time across distributed data environments. It replaces manual, ticket-driven processes with always-on, automated workflows.
While data governance defines policies, standards, and rules, agentic data stewardship acts as the execution layer that enforces those rules through automated workflows. Governance sets direction. Stewardship ensures it actually happens at scale.
How agentic data stewardship differs from traditional data stewardship
The core shift is not just automation. It is a change in how work gets done. Traditional stewardship relies on humans as the default execution layer, while agentic systems introduce autonomous data management where AI agents handle repetitive, high-volume tasks continuously.
|
Area |
Manual stewardship |
Agentic stewardship (AI agents) |
|
Tasks |
Performed by stewards via tickets and reviews |
Executed autonomously based on rules and context |
|
Speed |
Periodic, delayed |
Continuous, near real-time |
|
Consistency |
Depends on individual judgment |
Standardized and repeatable |
|
Scalability |
Limited by team capacity |
Scales across domains and datasets |
|
Human role |
Default executor |
Supervisor with escalation control |
The key distinction is human-in-the-loop oversight versus human-as-default execution. Stewards still define policies, validate edge cases, and handle exceptions, but they no longer need to execute every operational task themselves.
The five components of the agentic stewardship framework
A practical agentic stewardship model is built on five connected components that enable continuous execution.
-
Continuous data discovery and context ingestion ensure that agents stay updated with schema changes, lineage signals, and usage patterns across systems, forming the foundation for context-aware decisions.
-
Intelligent metadata stewardship allows agents to automatically tag datasets, map them to business glossary terms, and update metadata dynamically as data evolves.
-
Autonomous data quality enforcement enables continuous validation of data against defined rules, detecting anomalies and triggering actions when thresholds are breached.
-
Policy execution and access governance ensure that access controls, masking rules, and compliance policies are enforced dynamically based on predefined governance logic.
-
Feedback loops and self-learning systems allow agents to improve over time by learning from steward interventions, false positives, and evolving data patterns. The mechanism works as follows: when a steward overrides an agent's decision, correcting a misclassification or reversing a remediation, that intervention is captured as a labeled signal and used to retrain the agent's decision logic.
Over time, this closed-loop process reduces false positives and improves classification accuracy without requiring manual rule updates. It is what distinguishes agentic stewardship from static, rule-based automation that degrades as data environments evolve.
Together, these components turn automated data stewardship into a reliable execution layer that continuously operationalizes governance policies without relying on manual intervention.
Core workflows powered by agentic AI
Agentic data stewardship becomes tangible through the workflows AI agents execute continuously. Instead of waiting for manual intervention, these workflows run in real time across datasets, pipelines, and policies, ensuring governance is enforced as data moves and changes.
1. Metadata classification and enrichment workflows
AI agents continuously classify and enrich metadata using schema patterns, query behavior, lineage signals, and business context. This removes the dependency on manual tagging, which often becomes outdated quickly.
Agents map datasets to business glossary terms and domains automatically, ensuring consistency between technical and business metadata. As usage patterns evolve, metadata gets updated dynamically, improving discoverability and trust without requiring periodic cleanups.
2. Data quality monitoring and anomaly detection
AI agents validate data against predefined rules such as completeness, freshness, and accuracy in real time. They also detect anomalies using statistical patterns and behavioral baselines, identifying issues that static rules might miss.
According to a Gartner research from 2024, poor data quality costs organizations an average of $12.9 million annually, which is why continuous monitoring is becoming critical rather than optional.
Agents trigger alerts when deviations impact downstream analytics, helping teams act before business decisions are affected.
3. Policy enforcement and compliance workflows
Instead of relying on periodic audits, AI agents enforce governance policies as data is accessed or modified. Access controls, masking rules, and retention policies are applied dynamically based on user roles, attributes, and context.
Agents also detect and flag policy violations across datasets and pipelines in real time. This ensures compliance is not just documented but actively enforced across distributed systems.
4. Lineage-driven impact analysis
AI agents continuously track upstream and downstream dependencies across data pipelines. When a schema, transformation logic, or source system changes, agents can instantly identify which datasets, dashboards, or models will be affected.
They alert relevant stakeholders with context about potential business impact, enabling faster and more informed decisions. This reduces the risk of silent failures in analytics and reporting workflows.
5. Issue detection and auto-remediation
AI agents monitor data signals continuously to detect issues such as duplicates, schema mismatches, or pipeline failures. Once identified, issues are prioritized based on severity and business impact rather than treated equally.
Where rules allow, agents can apply automated fixes such as deduplication or schema alignment. For more complex scenarios, they route issues to stewards with full context, ensuring faster resolution without recreating manual bottlenecks.
Architectural design for agentic data stewardship systems
Agentic data stewardship depends on a strong architectural foundation. AI agents can only act reliably when metadata is unified, systems are connected, and every decision is observable, explainable, and governed in real time. In practice, data flows from source systems into a unified metadata layer, where AI agents interpret context, apply governance policies, and trigger actions across pipelines, access controls, and monitoring systems.
1. Active metadata as the operational foundation
Active metadata forms the core of any agentic stewardship system. It creates a unified layer that connects technical metadata, business context, lineage, and usage signals across all data systems.
This metadata is not static. It updates continuously through ingestion pipelines, query patterns, and user interactions. That continuous flow enables AI agents to make context-aware decisions, such as correctly classifying sensitive data or applying the right governance policy based on how data is actually used.
|
Related resource:
OvalEdge explains in its whitepaper Implementing Data Governance how active metadata, policy-driven workflows, and automated controls enable continuous governance execution across enterprise data environments. |
2. AI agent orchestration across systems
Agentic stewardship is not powered by a single model. It relies on multiple AI agents working together across classification, quality monitoring, and governance enforcement.
These agents are orchestrated through event-driven triggers. For example, a schema change can trigger classification updates, which then initiate quality checks and policy validation. Managing dependencies between agents ensures workflows run in the right sequence or in parallel where needed, without conflicts or gaps in execution.
3. Integration with modern data platforms
For agentic stewardship to work at scale, it must integrate seamlessly with the existing data stack. This includes data warehouses, data lakes, and transformation pipelines where data is created and processed.
It also needs to sync with catalogs, governance tools, and access control systems to ensure policies are consistently applied. Strong interoperability across distributed environments ensures that stewardship actions are not siloed but enforced across the entire data ecosystem.
An often-overlooked integration layer is data contracts: machine-readable agreements between data producers and consumers that define expected schemas, quality thresholds, and delivery standards. In agentic stewardship architectures, data contracts serve as structured policy inputs that agents can validate automatically. When a dataset violates its contract terms, the agent detects the breach and triggers the appropriate governance response without waiting for manual review. This makes data contracts a practical complement to active metadata in any production-grade agentic system.
4. Observability, auditability, and control layers
Autonomous execution without visibility creates governance risk. Observability layers track what agents do, when they act, and why decisions are made.
Auditability ensures that every action is logged for compliance and review, including policy enforcement, data access changes, and remediation steps. Explainability adds another layer by making agent decisions transparent, which is critical for regulated environments where accountability cannot be delegated to automated systems.
Step-by-step framework to implement agentic data stewardship
Implementing agentic data stewardship requires a structured rollout that starts with identifying execution gaps, defines governance guardrails first, and scales automation in controlled stages. A sequenced approach ensures AI agents enhance stewardship without introducing risk or inconsistency.
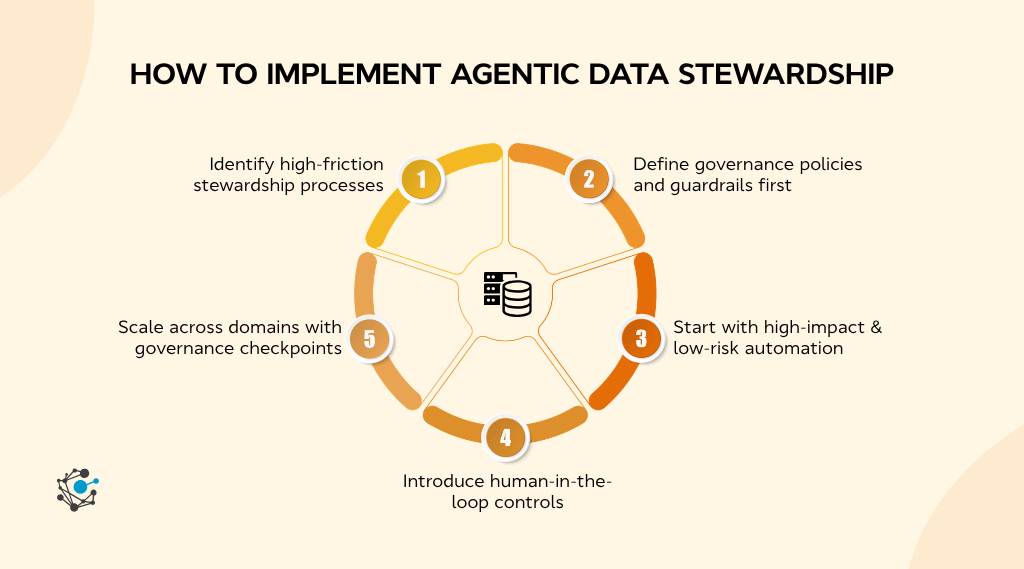
Step 1: Identify high-friction stewardship processes
The starting point is not tooling. It is identifying where stewardship work breaks down or slows the business. This typically includes manual metadata tagging, delayed access approvals, recurring data quality issues, and inconsistent policy enforcement across systems.
A practical way to prioritize is by mapping processes on an effort versus impact matrix. High-frequency, rule-based, and time-consuming tasks are strong candidates for automation. According to a report published by McKinsey & Company, “Generative AI and the future of work in America”, in 2023, up to 30% of activities in data-intensive roles can be automated with current technologies, which highlights the immediate opportunity in stewardship workflows.
Step 2: Define governance policies and guardrails first
Automation without clear policy definition leads to inconsistent outcomes at scale. Governance policies must be defined before introducing AI agents so that execution remains aligned with business and regulatory expectations.
A governance guardrail typically includes a clearly defined policy object, its scope across datasets or domains, and escalation rules for exceptions. For example, a sensitive data policy should specify classification criteria, access restrictions, masking requirements, and conditions under which human review is required. This ensures agents act within boundaries rather than making uncontrolled decisions.
Step 3: Start with high-impact, low-risk automation
Initial rollout should focus on workflows that are repetitive, rules-driven, and low risk from a compliance standpoint. Common entry points include metadata tagging, duplicate detection, and access request routing.
A focused 90-day pilot within a single data domain allows teams to validate outcomes, measure efficiency gains, and refine policies before scaling. In 2026, IBM shares in its insights that organizations with mature data governance practices see significantly higher data trust and decision accuracy, reinforcing the value of starting with controlled, measurable use cases.
|
Did you know:
A leading credit union implemented OvalEdge to automate data governance workflows and metadata management, significantly reducing manual stewardship effort. By introducing policy-driven controls and improving data quality visibility, the organization enabled faster, more reliable decision-making across business teams. |
Step 4: Introduce human-in-the-loop controls
Autonomy should be introduced with clear thresholds for when agents can act independently and when they must escalate decisions. Confidence scoring plays a key role here. High-confidence scenarios can be executed automatically, while ambiguous or high-risk cases are routed to stewards.
In practice, confidence scoring works best when mapped to three defined action tiers:
|
Confidence tier |
Example scenario |
Agent behavior |
|
High |
Tagging a dataset matching a known schema pattern |
Acts autonomously, logs action |
|
Medium |
Classifying a dataset with partial metadata match |
Acts and flags for steward review |
|
Low |
Ambiguous schema with no lineage context |
Escalates without acting, routes to steward |
This tiered model ensures agents do not default to full autonomy or full escalation, both of which create either governance risk or operational bottlenecks. Teams should define tier thresholds per workflow type during the pilot phase rather than applying a single global threshold across all use cases.
The goal is to avoid recreating manual bottlenecks through poorly designed review queues. Instead, stewards should only engage where human judgment adds value.
Step 5: Scale across domains with governance checkpoints
Once initial workflows are stable, expansion should follow a domain-by-domain approach. Starting with high-volume, low-sensitivity data reduces risk while building operational confidence in agent performance.
Before scaling further, governance checkpoints should validate policy alignment, auditability, and performance outcomes. Regular review cadences ensure policies remain relevant and agents continue to operate within defined boundaries.
To make these checkpoints actionable, teams should validate agent performance against four core metrics before approving expansion to any new domain:
-
Automated tagging accuracy rate: Percentage of agent-assigned metadata tags confirmed correct by stewards during review.
-
Mean time to issue resolution: Average time from issue detection to remediation, compared against the pre-automation baseline.
-
Policy violation detection rate: Percentage of actual violations caught by agents versus those identified through manual audits.
-
Governance coverage ratio: Share of total data assets under active agent monitoring versus previously unmonitored.
These metrics create a measurable performance baseline that informs both scaling decisions and the ROI case for continued investment in agentic stewardship. This phased approach allows organizations to move toward autonomous data stewardship while maintaining control, transparency, and trust.
Challenges and governance considerations
Agentic data stewardship introduces new risks alongside its benefits. CDOs need to manage automation boundaries, ensure explainability, keep policies aligned, and guide teams through role changes so autonomy strengthens governance without reducing control.
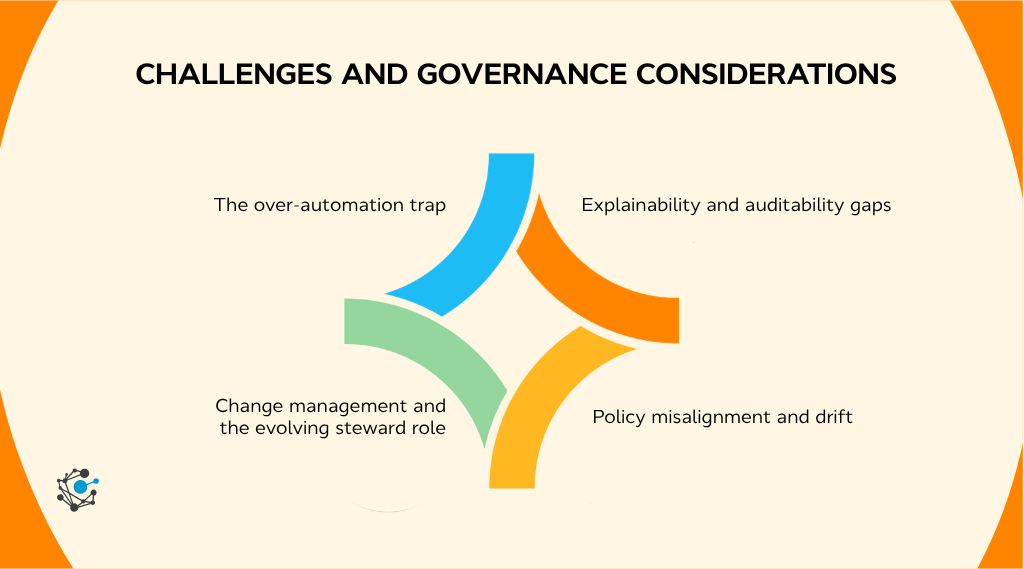
1. The over-automation trap
AI agents can act quickly, but without enough context, they can misclassify data or apply incorrect fixes at scale. This risk increases when metadata or policies are incomplete.
Mitigation comes from confidence scoring, escalation thresholds, and domain-specific guardrails. These ensure agents act autonomously only in well-defined scenarios and route uncertain cases to human stewards.
2. Explainability and auditability gaps
“The AI decided” is not a valid audit response. Every automated action must be traceable and explainable.
Explainable stewardship requires clear audit logs showing what action was taken, why it was triggered, and which policy it aligns with. This is essential for compliance and trust in regulated environments.
3. Policy misalignment and drift
Governance policies evolve, but agents enforce whatever rules they are given. If policies become outdated, agents can scale incorrect decisions consistently.
A defined cadence for policy review and agent retraining ensures alignment with current business and regulatory needs.
4. Change management and the evolving steward role
Agentic stewardship shifts stewards from execution to supervision. Resistance often comes from unclear role changes.
Organizations need to reposition stewards as AI supervisors, supported by training, updated KPIs, and clear ownership. This ensures adoption without disrupting governance operations.
The future of data stewardship in an agentic ecosystem
Agentic data stewardship is reshaping how governance operates across enterprise data systems. As AI agents take on execution responsibilities, stewardship shifts toward continuous, embedded control.
According to a Gartner release published in 2025, 40% of enterprise applications will include task-specific AI agents by 2026, up from less than 5% today, highlighting the rapid shift toward agent-driven, autonomous systems.
-
Autonomous governance systems at scale: Governance will move from periodic oversight to real-time enforcement, where AI agents continuously monitor, validate, and act across the data lifecycle without manual triggers.
-
Alignment with data mesh and data products: Agentic stewardship will act as the enforcement layer in decentralized models, ensuring consistent policy application across domain-owned data products without central bottlenecks.
-
The CDO’s strategic imperative: The role of the CDO will shift from enforcing governance to architecting systems where policies, metadata, and AI agents work together to deliver scalable, reliable execution.
-
Emerging signals to watch: Multi-agent collaboration, LLM-driven policy generation, and real-time regulatory adaptation will define the next phase of intelligent, autonomous data stewardship.
Conclusion
Agentic data stewardship marks a shift from manual, ticket-driven execution to continuous, AI-driven operations. Tasks like metadata classification, data quality validation, and policy enforcement can now run in real time across systems, improving consistency and scalability.
Autonomy, however, only works with control. Governance policies, confidence thresholds, auditability, and human-in-the-loop oversight ensure decisions remain explainable and aligned with business and regulatory needs. The role of stewards evolves from execution to supervision and policy design.
For CDOs, the next step is to audit current stewardship friction points, prioritize high-impact workflows, and define guardrails before introducing automation.
Platforms like OvalEdge enable this shift by combining active metadata, automated workflows, and governance enforcement into a unified system.
To see how agentic stewardship works in practice, book a demo and evaluate how it fits into an enterprise data governance strategy.
FAQs
1. What is agentic data stewardship, and how does it work?
Agentic data stewardship uses AI agents to continuously discover, classify, validate, and govern data across systems. These agents execute policies in real time, reducing manual intervention while ensuring governance is consistently applied across the data lifecycle.
2. What tasks can AI agents automate in data stewardship?
AI agents automate metadata tagging, data quality checks, anomaly detection, policy enforcement, access approvals, lineage tracking, and issue remediation. These tasks are repetitive and high-volume, making them ideal for continuous, automated execution at scale.
3. Can AI replace data stewards, or does it only augment them?
AI augments data stewards rather than replacing them. Agents handle execution tasks, while stewards define policies, manage exceptions, and oversee governance outcomes, ensuring accountability and human judgment remain central to decision-making.
4. How do you maintain governance and control when AI agents act autonomously?
Control is maintained through defined policies, confidence thresholds, escalation rules, audit trails, and human review mechanisms. These ensure agents operate within boundaries and every automated decision is traceable, explainable, and aligned with governance requirements.
5. What is the difference between agentic AI and traditional data catalog automation?
Traditional automation follows predefined rules for specific tasks. Agentic AI uses context, adapts dynamically, and orchestrates end-to-end workflows, enabling continuous and intelligent execution rather than isolated, rule-based automation.
6. How do you measure the ROI of agentic data stewardship?
ROI is measured by reduced manual effort, improved data quality, and increased governance coverage. Establish baseline metrics before implementation to track gains in efficiency, accuracy, and the number of governed data assets over time.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)