.jpg)
As AI agents take on a growing role in business decisions, the quality of their context is becoming just as important as the quality of their models. Dynamic Context vs Static Context is one of the most important design decisions in modern AI systems, determining whether agents rely on fixed instructions, current information, or both. This blog explains the differences between Dynamic Context vs Static Context, when to use each approach, and how context drift can undermine AI reliability. It also explores how governance, metadata, lineage, and validation help enterprises build trustworthy AI agents.
AI agents are becoming part of everyday business operations, making the quality of the context they receive just as important as the quality of the models themselves. A well-written prompt can guide an agent's behavior, but it cannot compensate for outdated definitions, deprecated datasets, missing governance rules, or stale metadata.
The challenge for enterprise teams is deciding what information should remain embedded in agent instructions and what should be retrieved dynamically at runtime.
The stakes are rising quickly.
Gartner's 2025 press release, "Gartner Announces the Top Data & Analytics Predictions", predicts that by 2027, 50% of business decisions will be augmented or automated by AI agents for decision intelligence, increasing the business impact of context-related errors and governance failures.
As business environments continuously evolve through changing schemas, ownership, lineage, access controls, and data quality signals, choosing the right context strategy becomes critical.
This blog explores static and dynamic context, when to use each, and the infrastructure required to support them.
What is static context in AI?
Static context is the fixed information provided to an AI system before or at the start of a task. It remains the same across interactions and only changes when someone manually updates the instructions, rules, prompts, or configurations.
For example, a governance assistant may always be instructed to avoid exposing sensitive data, respond in a structured format, and escalate legal interpretation questions to the compliance team. These instructions should remain consistent regardless of who uses the assistant or what question is asked. They define how the agent behaves, not what it knows at a particular moment.
Most static context falls into a handful of categories:
-
System prompts and the agent's role
-
Tone and response style
-
Response format and structure
-
Security instructions and guardrails
-
Few-shot examples
-
Escalation rules
-
Stable business rules and approved policy language
Static context works best when an instruction should stay consistent across users, sessions, and workflows. It provides the predictable foundation that makes agent behavior reliable, controlled, and reviewable.
Static context is not a limitation. It is an essential control layer. Problems arise only when information that changes frequently, such as data definitions, ownership, lineage, or quality status, is treated as static instead of being updated dynamically.
What is dynamic context in AI?
Dynamic context is information retrieved, assembled, or computed at inference time based on the user's query, identity, permissions, task, and the current state of the systems involved. Unlike static context, it changes from one interaction to the next and reflects the latest available information.
For example, a data discovery agent answering the question, "Which customer dataset should I use for churn analysis?" may need to retrieve current metadata, the approved business definition of churn, data quality scores, lineage, certification status, and user-specific access permissions before making a recommendation. If any of that information is outdated, the recommendation can quickly become unreliable.
An OvalEdge expert would push the churn example one step further. The hard part is not describing what a customer dataset contains. It is telling the agent which definition of customer and churn the business has actually approved, for this question, from this source.
"Customer" can mean a sales account in the CRM, a billing account in finance, or an active user in the product. A human analyst picks the right one by judgment. An agent may quietly pick the wrong one, generate the query, and pass the wrong answer into the next workflow.
In enterprise environments, dynamic context typically includes:
-
Metadata, schemas, and business definitions
-
Lineage, quality, ownership, and governance signals
-
User permissions, API responses, and retrieved knowledge
The purpose of dynamic context is not to provide more information. It is to provide the most relevant and current information at the moment a decision is made.
Research highlights the value of this approach.
A 2025 arXiv paper on Dynamic Context Tuning for RAG reported a 14% improvement in plan accuracy and a 37% reduction in hallucinations compared to static, single-turn retrieval baselines.
Dynamic context helps AI systems adapt to changing business environments while grounding responses in the latest available knowledge.
Dynamic context vs static context: key differences
The difference between static and dynamic context comes down to stability versus freshness. Static context shapes how an agent behaves. Dynamic context determines what the agent knows at the moment a task is performed. One provides the rules. The other provides the current knowledge needed to apply those rules correctly.
|
Comparison point |
Static context |
Dynamic context |
|
Basic meaning |
Fixed information is loaded before a task |
Live information retrieved during inference |
|
Main purpose |
Control agent behavior |
Ground answers in current information |
|
Best used for |
Prompts, policies, response rules, tone, and role instructions |
Metadata, lineage, permissions, quality signals, and tool outputs |
|
Update pattern |
Manual updates and version control |
On-demand retrieval and system lookups |
|
Strength |
Consistency and predictability |
Freshness and task relevance |
|
Weakness |
Can become outdated |
Can introduce latency or retrieval errors |
|
Governance focus |
Prompt reviews and policy approval |
Access controls, lineage, quality, and auditability |
|
Example |
"Always summarize policy exceptions in three bullets." |
"Retrieve the latest owner and quality score for this dataset." |
The short version is simple: static context gives the agent its rules, while dynamic context provides its current working knowledge. Effective AI systems need both.
At OvalEdge, we believe the industry often treats dynamic context as primarily a retrieval challenge when it is equally a trust challenge. Pulling information is only the first step. AI systems also need confidence that the information is governed, current, traceable, and appropriate for the question being asked.
A governed semantic layer for AI can help establish meaning, but trust comes from lineage, permissions, quality signals, ownership, and governance controls. More retrieval alone does not create trust, and more automation alone does not create understanding.
When to use static context vs dynamic context
The cleanest way to make this call is to ask one question for each piece of context: should this stay the same for everyone, or does it depend on who is asking and what is true right now? Stable behavior belongs in a static context. Changing knowledge belongs in a dynamic context.
|
Use case |
Better fit |
Why |
|
Agent role and tone |
Static context |
These instructions should stay consistent |
|
Response format |
Static context |
The format can be fixed and reused |
|
Few-shot examples |
Static context |
Examples guide behavior and can be versioned |
|
Security boundaries |
Static and dynamic |
The rule is fixed, but enforcement needs live permissions |
|
Policy explanation |
Static and dynamic |
The policy is fixed, but applying it needs live metadata |
|
Current schema |
Dynamic context |
Schemas change and need a runtime lookup |
|
Business metric definition |
Dynamic context |
Approved definitions get revised |
|
Data owner or steward |
Dynamic context |
Ownership shifts across teams and systems |
|
User access rights |
Dynamic context |
Permissions depend on user, role, and asset |
|
Data freshness |
Dynamic context |
Freshness must reflect the current pipeline state |
|
Data lineage |
Dynamic context |
Dependencies change as systems evolve |
|
PII classification |
Dynamic context |
Sensitive data tags should reflect the current status |
A useful pattern shows up in the rows that need both. Security and policy explanations sit in two places at once. The rule itself is fixed in a static context, but enforcing or applying it requires a live read of permissions and metadata. That combination, a fixed rule applied to current enterprise data, is where most real agents work.
The hidden risk: context drift
Context drift is the gap between what an AI agent believes to be true and what is currently true in the business, data, or policy environment. It is mostly invisible, which is what makes it dangerous.
It shows up in ordinary ways. A metric definition changes, but the agent keeps using the old formula. A table owner moves on, but the agent still routes questions to the wrong steward. A column gets reclassified as PII, while the agent still treats it as general data. A dashboard's lineage shifts after a pipeline update. A RAG index quietly serves as documentation that was accurate two quarters ago.
In every one of these cases, the answer can look polished and arrive with confidence while being outdated, non-compliant, or simply wrong. That is the trap. Drift does not announce itself.
One myth to retire: Retrieval-augmented generation does not fix context drift on its own. RAG is only as fresh as the sources behind it and the refresh cycle that maintains them.
If the underlying data quality for AI is not monitored and the metadata is not kept current, retrieval simply delivers stale answers faster.
Context drift is ultimately a governance challenge, not just a retrieval challenge. Organizations that want to reduce AI risk need trusted metadata, lineage, quality signals, and ownership information available at runtime. Without that foundation, even sophisticated retrieval systems can deliver answers that are outdated, incomplete, or difficult to trust.
Ready to see how a governed context foundation can help improve AI accuracy and trust? Book a demo to explore how OvalEdge helps organizations connect AI agents to trusted business context.
How static and dynamic context work together in production AI agents
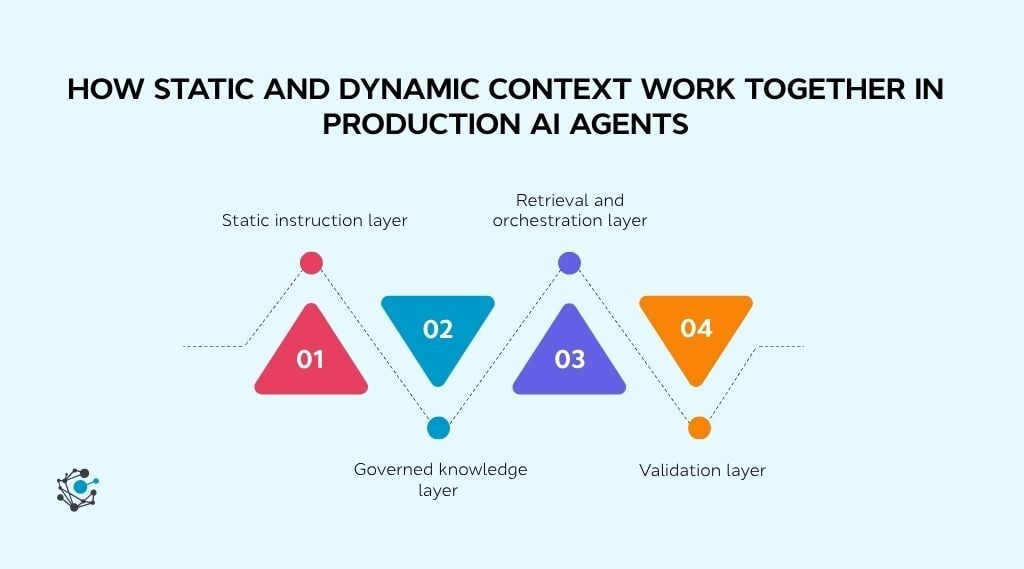
Production AI systems do not choose between static and dynamic context. They rely on both. Static context provides consistency and control, while dynamic context ensures decisions are based on current information. The most effective implementations combine these capabilities in a layered architecture, with governance acting as the bridge between enterprise knowledge and AI reasoning.
During inference, these layers work together sequentially. The agent first receives behavioral instructions, then retrieves relevant business context, applies governance and access controls, and finally generates and validates its response. Each layer helps ensure the agent's decisions remain accurate, consistent, and aligned with business requirements.
1. Static instruction layer
This layer defines how the agent behaves. It includes the system prompt, role definition, response format, guardrails, escalation rules, and other instructions that remain relatively stable across interactions.
Example: A governance assistant is instructed to never expose sensitive data, always cite approved sources, and escalate legal interpretation requests to the compliance team.
2. Governed knowledge layer
This layer contains the trusted business context that the agent relies on to make decisions. It includes metadata, business glossary definitions, lineage, ownership information, privacy classifications, quality scores, certification status, and governance policies.
Example: Before recommending a dataset for churn analysis, the agent retrieves the approved churn definition, certified data asset, assigned steward, and quality status.
A maintained metadata layer for AI is what makes this layer reliable. Without it, retrieval systems may surface information that is technically accessible but not trustworthy.
This is the layer that decides whether an enterprise is actually ready for agents. A more capable model does not inherit business context. It does not know that revenue means different things to finance, sales, and operations, or that one table is stale and another is restricted.
That knowledge has to live in the governed layer and be made available at runtime, or the agent works without it.
3. Retrieval and orchestration layer
This layer is responsible for gathering and assembling context. It includes RAG systems, MCP servers, APIs, tool calls, query routing, and ranking mechanisms that determine what information is retrieved and presented to the model.
Example: When a user asks about customer churn, the orchestration layer retrieves relevant glossary entries, metadata records, lineage information, and supporting documentation from multiple systems.
4. Validation layer
Before the agent responds, the retrieved context should be checked for freshness, relevance, permissions, and traceability. This layer helps prevent outdated, unauthorized, or low-quality information from influencing answers.
Example: The agent verifies that the dataset is certified, the quality score meets policy thresholds, and the user has permission to access the underlying information before generating a recommendation.
Together, these layers create a clear division of responsibility. Static context governs behavior. Dynamic context supplies current knowledge. The governed knowledge layer provides trust, and the validation layer helps ensure that trust is maintained throughout the decision-making process.
How OvalEdge supports a governed dynamic context for AI
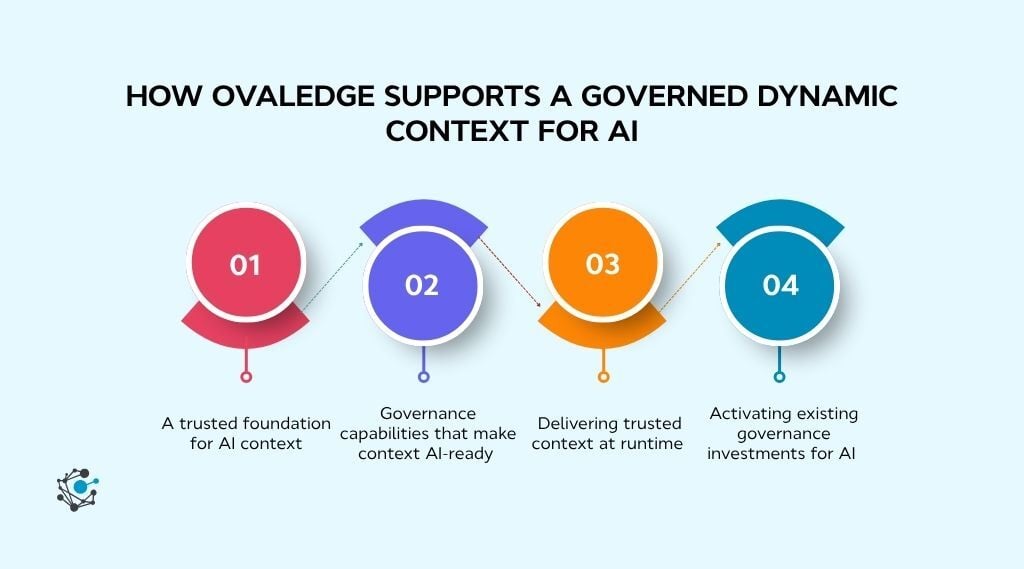
Dynamic context is only as reliable as the governance foundation behind it. AI agents may retrieve information from many sources, but they still need authoritative business context to make trustworthy decisions. This is where governed metadata platforms play an important role.
1. A trusted foundation for AI context
OvalEdge serves as the governed knowledge layer of the AI stack. Rather than replacing retrieval systems, agent frameworks, or orchestration tools, it provides a central source of business context that AI systems can rely on at runtime.
As organizations scale AI adoption, the challenge shifts from finding information to determining which information is trustworthy. OvalEdge helps address this challenge by organizing metadata, business definitions, ownership information, quality signals, and governance assets into a trusted foundation for AI-driven decisions.
2. Governance capabilities that make context AI-ready
AI systems require more than access to data. They need business meaning, trust signals, and governance controls that can be consumed during inference.
OvalEdge brings together data catalog, business glossary, data lineage, data quality, privacy and access governance, AI governance, active metadata, and stewardship workflows in a single platform. These capabilities help provide the definitions, traceability, ownership, and quality indicators that support more reliable AI outputs.
Practical Insight: OvalEdge's Data Catalog helps reduce context drift by providing current metadata, ownership details, lineage information, and certification status that AI systems can use as part of their context.
3. Delivering trusted context at runtime
Access to current information alone does not guarantee reliable AI outcomes. Agents also need context that is approved, explainable, and aligned with business rules.
OvalEdge helps connect AI systems to certified assets, governance policies, business definitions, and lineage information, enabling agents to retrieve context that is not only relevant but also traceable and governed. This helps improve consistency, explainability, and trust in AI-generated recommendations and decisions.
4. Activating existing governance investments for AI
Many organizations already possess much of the information needed to support AI context through catalogs, glossaries, lineage, quality controls, and stewardship processes.
At OvalEdge, we believe the opportunity is not to rebuild these assets for AI. It is to activate existing governance investments and make them available in a machine-readable form that agents can consume safely and effectively. This allows organizations to extend the value of their governance programs into AI workflows rather than creating an entirely separate foundation.
Conclusion
Static context and dynamic context are not competing approaches. Enterprise AI depends on both. Static context provides the instructions, guardrails, and consistency that shape agent behavior, while dynamic context supplies the current business knowledge needed to make accurate decisions.
The challenge is not simply retrieving more information. It ensures that the information AI agents receive is governed, trustworthy, and aligned with business reality. Metadata, business definitions, lineage, quality signals, ownership, and access controls all play a role in making dynamic context reliable enough for enterprise use.
At OvalEdge, we believe most organizations already possess much of this foundation through their governance programs. The opportunity is to activate those assets and make them available as an AI-ready context at runtime.
Ready to see what a governed dynamic context foundation looks like in practice? Schedule a demo with OvalEdge.

.png?width=1081&height=173&name=Forrester%201%20(1).png)
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)