
Data lineage
Visualize your data Flow effortlessly & automated
TRUSTED BY













Data team
Impact
analysis
Understand your complex data pipeline and proactively assess the impact of a change, and communicate with the right people.

Business team
Build
trust
Transparency and clarity build trust. Provide your business team with a clear picture of how the data is being used and transformed.
Compliance team
Track
data
Automated lineage means you can uncover upstream data to the point of origin. You never have to run the risk of your reports failing to qualify.
System
Object
Attribute
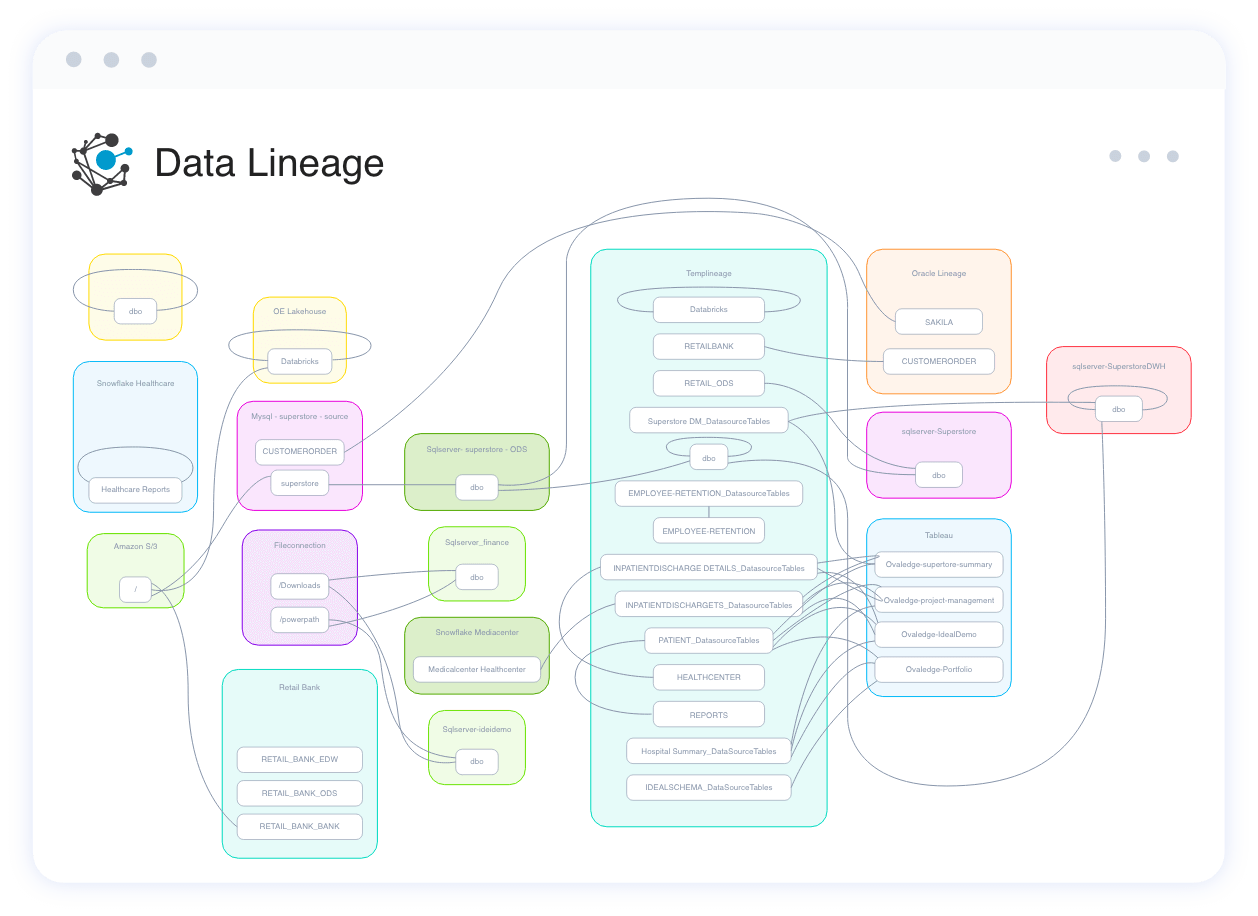
Get a bird's eye view in a snap
View the data flow between various applications, warehouses, and reporting systems with one click.
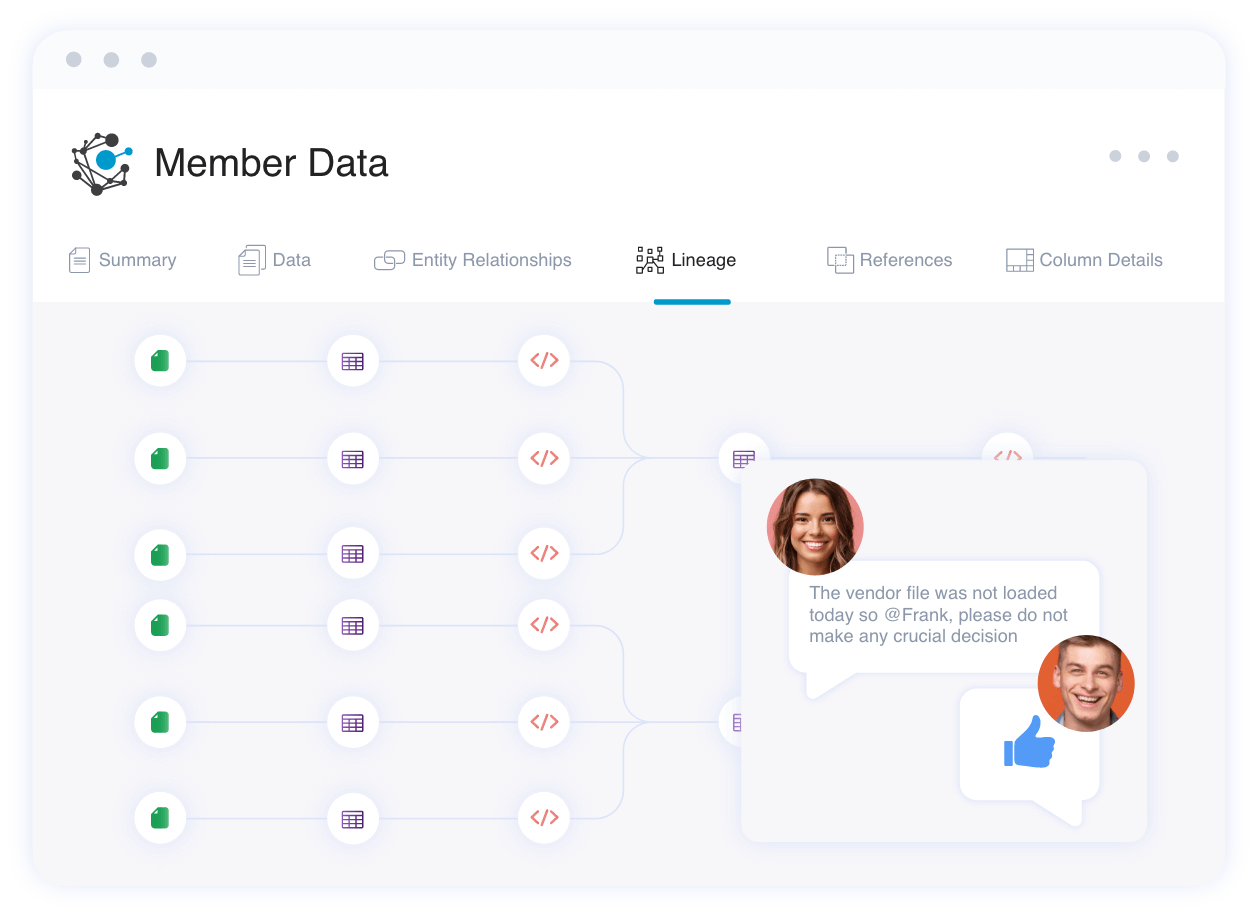
Collaborate with right stakeholders
Object level lineage connects the dots, and you can reach to the right person and collaborate within context.
Do connected governance
Object level lineage connects the dots, and you can reach the right person and collaborate within context.
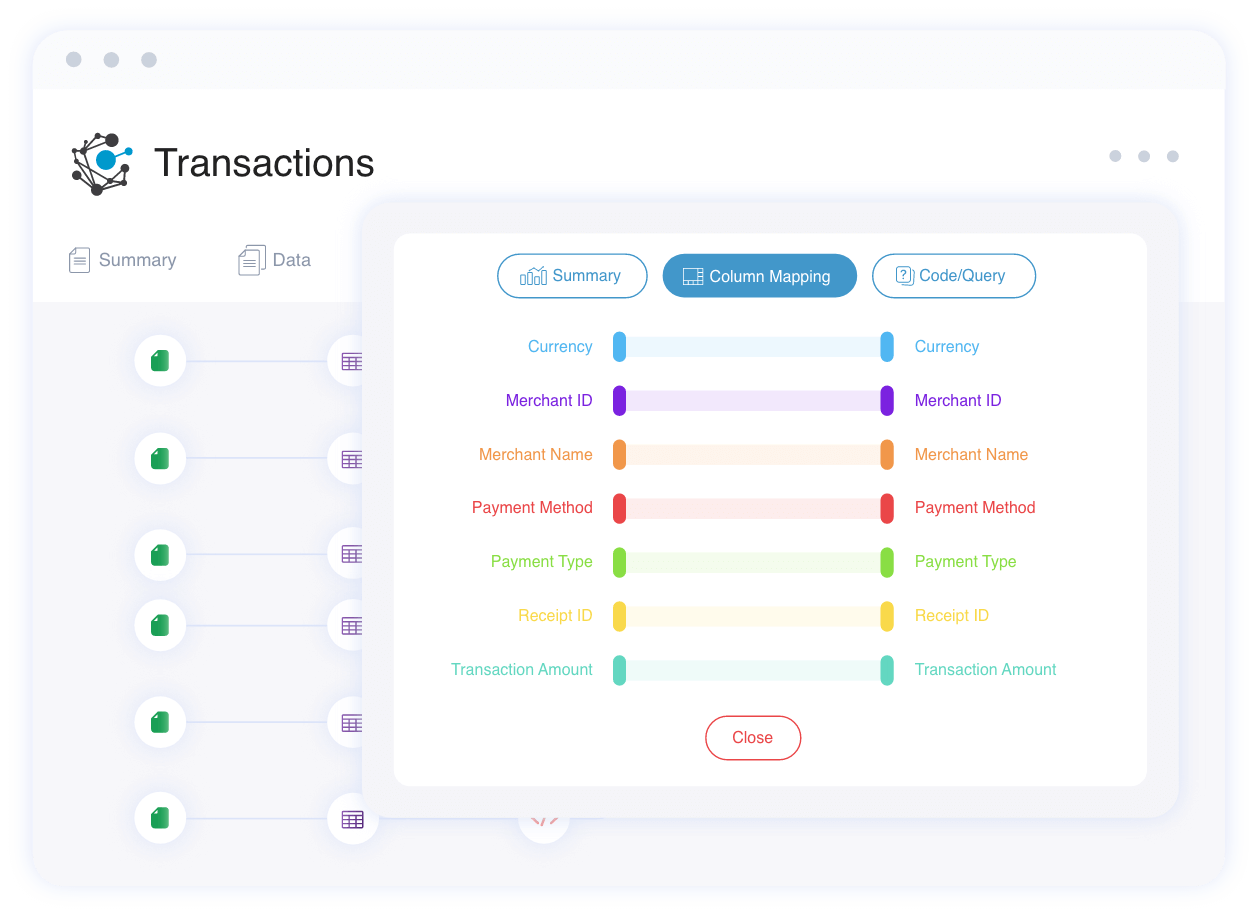
Analyze upstream for business term discussion
Bring the right people together for conflict resolution and consensus building.
Analyze downstream to assess impact of any change
Proactively analyze which reports might fail or report inaccurate data when upgrading your source systems.
OvalEdge Recognized as a Leader in Data Governance Solutions

.png?width=1081&height=173&name=Forrester%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
